
Один из распространенных алгоритмов, обсуждаемых на технических собеседованиях, - это двоичный поиск. Учитывая массив из n элементов, найдите, присутствует ли вход, будь то строка или целое число, в массиве элементов. Двоичный поиск более эффективен, чем проверка каждого элемента в массиве, потому что массив уменьшается вдвое при каждом проходе цикла for. Когда вы усвоите базовую установку, вы почувствуете себя более уверенно, решая ее под давлением настоящего собеседования.
Этот подход можно использовать только для отсортированных массивов. То есть элементы в массиве должны быть расположены от наибольшего к наименьшему для целых чисел или в алфавитном порядке для строк.
Вход: отсортированный массив и значение, которое мы проверяем.
Базовая настройка
Маршруты: создайте функцию с именем fruitSort, которая принимает отсортированный массив, называемый массив, и значение, которое мы проверяем, называемое вводом. Эта функция должна найти средний индекс массива, а затем перебрать массив, чтобы проверить, совпадает ли среднее значение со значениями в массиве.
- Сначала установите переменные start и end в начало и конец массива.
2. Затем вычислите средний индекс массива.
3. Сравните ввод со значением среднего числа.
4. средний будет индексом 3. Допустим, у нас есть вход «бузина». В середине будет index = 0 со значением «blueberries». Следовательно, все значения до середины, включая середину, слишком малы. В результате мы переместим start вправо, переназначив is с start = middle + 1.
5. Если наш ввод меньше среднего, мы хотим переместить конец, потому что мы знаем, что все, что находится после середины, исключено из наших возможных совпадений. Вот почему этот метод называется «разделяй и властвуй» и почему он снижает общее количество поисков по сравнению с линейным поиском.
Прежде чем мы перейдем к решению, выполните следующие действия по устранению проблемы и откройте фрагмент в Chrome, как описано здесь. Вам также потребуется использовать цикл while. Какие условия должны выполняться для продолжения цикла?
Допустим, input = «zucchini» - значение больше, чем все значения в нашем диапазоне. Если мы не учтем это, наш цикл будет проверять бесконечно. С «кабачком» наш ввод ›плод [середина], тогда наша петля будет продолжать двигаться, начиная с левой, без остановки. Предупреждение о крайнем случае!
РЕШЕНИЕ НИЖЕ. ПОПРОБУЙТЕ ЭТО В первую очередь.
Big O и сложность времени
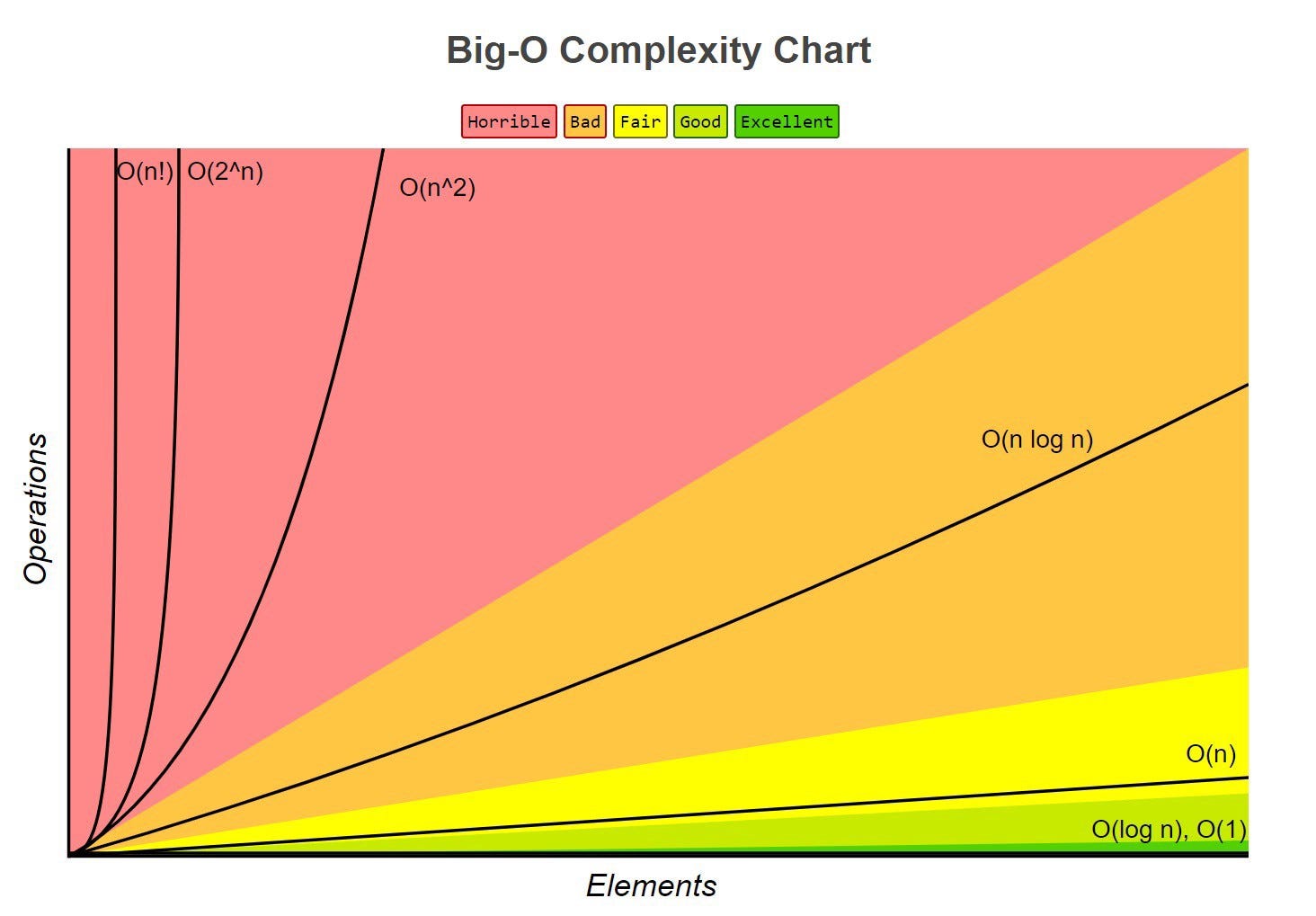
Как вы можете видеть здесь, log n приближается к O (1), что замечательно для нашей среды выполнения, но почему? Как упоминалось здесь, вопрос, который мы должны задать себе, заключается в том, сколько раз нам нужно разделить наш исходный массив (n), пока мы не дойдем до единственного элемента (1), который мы ищем, или, возможно, последнего элемента, который не соответствует ?
Вот немного математики с сайта интервьюcake.com:
n * (1/2) * (1/2) * (1/2) ... = 1 n * (1/2) ^x // x is equal to the # of times we halve n - that is finding our middle in the array Solving for x gives us: 1) n * (1/2) ^x = 1 2) n * (1^ x/ 2^x) = 1 3) n * (1/ 2^x) = 1 4) n/ 2^x = 1 5) n = 2^x 6) log2n = log2 2 ^x 7) n = 2 ^x
На шаге 6 показатель, обратный экспоненте, является логарифмом, поэтому мы берем логарифм по основанию 2 с обеих сторон. 2 ^ x и логическое основание 2 компенсируют друг друга, давая нам x с левой стороны. Справа - log2 n.
log2 n = x
Логическое основание 2 похоже на выражение 2, возведенное до того числа (x), которое дает нам n. Следовательно, двоичный поиск дает нам время выполнения O (log (n)).
Ресурсы: