Каждый день генерируется много данных в разных формах, и одна из форм - текст; один хороший источник этих текстовых данных - твиты, где люди активно делятся своими мыслями. Наша цель в этой статье - использовать Twitter API для извлечения твитов и анализа их настроений.
Необходимые библиотеки и модули:
import matplotlib.pyplot as plt
%matplotlib inline
import re
import pandas as pd
import tweepy
from tweepy import OAuthHandler
from textblob import TextBlob
import csv
import string
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
n_words= set(stopwords.words('english'))
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from wordcloud import WordCloud,STOPWORDS
porter = PorterStemmer()
lemmatizer = WordNetLemmatizer()
nltk.download('punkt')
nltk.download('wordnet')
Как использовать Twitter API:
Нажмите здесь, чтобы узнать, как сгенерировать Twitter API.
вы получите четыре типа ключей:
# I replaced my keys with "xxxxxxx" :)
consumer_key = 'xxxxxxxx'
consumer_secret ="xxxxxxxxxxx"
access_token = 'xxxxxxxxxx'
access_token_secret = 'xxxxxxxxxxx'
давайте использовать их для аутентификации через python :)
def TwitterClient():
# keys and tokens from the Twitter Dev Console
consumer_key = 'xxxxxxxx'
consumer_secret ="xxxxxxxxxxx"
access_token = 'xxxxxxxxxx'
access_token_secret = 'xxxxxxxxxxx'
# attempt authentication
try:
# create OAuthHandler object
auth = OAuthHandler(consumer_key, consumer_secret)
# set access token and secret
auth.set_access_token(access_token, access_token_secret)
# create tweepy API object to fetch tweets
api = tweepy.API(auth)
except:
print("Error: Authentication Failed")
return api #now we can make request to twitter using this api
Предварительная обработка ТЕКСТА
Предварительная обработка - это ключ, который очень помогает модели лучше понять вещи, а также помогает снизить вычислительные затраты и время. Но это также уменьшает пространство, на котором должна работать модель, и мы вернемся к этому позже.
Перечислим моменты, на которых мы хотим сосредоточиться при очистке данных:
- ссылки: Они не участвуют в выражении каких-либо чувств.
- Теги: такие теги, как # tags и @ tags, для нас бесполезны.
- Знаки препинания
- Числовые значения
- Запрещенные слова: такие слова, как и, и т. Д., Не влияют на настроение.
- Нормализация слов: например, выделение корней, лемматизация и т. Д.
Давайте посмотрим, что я имел в виду под словом "нормализация":
Стебель:
Это процесс преобразования слов в их корневые формы, например, кошки превращаются в кошек и т. Д. Мы будем использовать стеммер Портера, предлагаемый NLTK.
Porter Stemmer - это алгоритм, состоящий из некоторых наборов правил и удаления суффикса слова. Этот процесс также известен как чередование суффиксов; иногда корень, генерируемый этим алгоритмом, даже не является значимым словом на английском языке. Но его используют из-за его скорости и простоты.
def clean(text):
# removing @ tags and links from the text
text= ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t]) |(\w+:\/\/\S+)", " ", text).split())
# converting all letters to lower case and relacing '-' with spaces.
text= text.lower().replace('-', ' ')
# removing stowards and numbers
table= str.maketrans('', '', string.punctuation+string.digits)
text= text.translate(table)
# tokenizing words
tokens = word_tokenize(text)
# stemming the words
stemmed = [porter.stem(word) for word in tokens]
words = [w for w in stemmed if not w in n_words]
text = ' '.join(words)
return text
Анализ настроения:
Мы будем использовать библиотеку TextBlob для анализа настроения или полярности твитов.
analysis = TextBlob(tweet) senti= analysis.sentiment.polarity if senti<0 : emotion = "NEG" elif senti>0: emotion= "POS" else: emotion= "NEU"
Получим твиты с помощью API и помечаем их эмоциями:
def get_tweets(query, count = 10):
tweets = []
try:
# call twitter api to fetch tweets
fetched_tweets = api.search(q = query, count = count)
for tweet in fetched_tweets:
# cleaning the tweets
tweet= clean(tweet.text)
# getting the sentiment from textblob
analysis = TextBlob(tweet)
senti= analysis.sentiment.polarity
# labeling the sentiment
if senti<0 :
emotion = "NEG"
elif senti>0:
emotion= "POS"
else:
emotion= "NEU"
# appending all data
tweets.append((tweet, senti, emotion))
return tweets
except tweepy.TweepError as e:
# print error (if any)
print("Error : " + str(e))
:
# getting the api access api = TwitterClient() # calling function to get tweets, count is the number of tweets. tweets = get_tweets(query = "Farmer's Protest", count = 200) df= pd.DataFrame(tweets, columns= ['tweets', 'senti', 'emotion']) # droping retweets df= df.drop_duplicates()
Поздравляем, мы успешно проанализировали настроения или полярность твитов с помощью Twitter API.
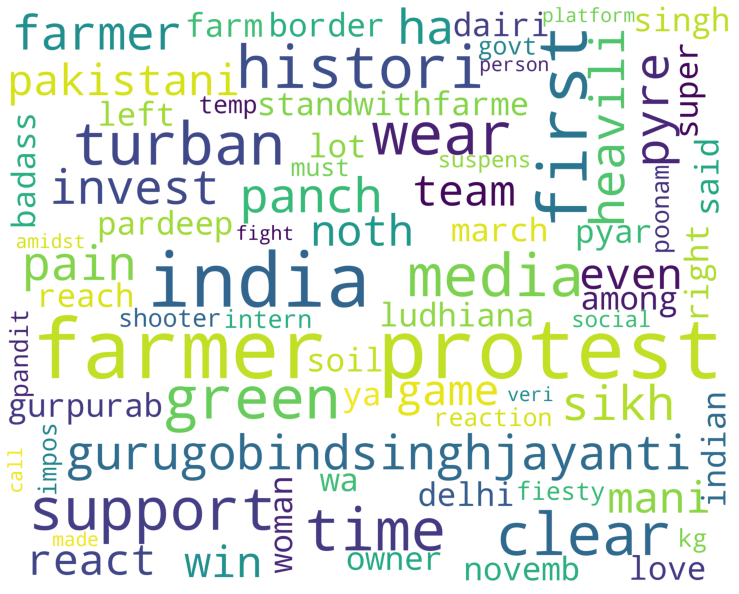
Давайте посмотрим на наиболее часто используемые слова в выражении положительных эмоций. Мы будем создавать облако слов, используя библиотеку wordcloud.
def wordcloud_draw(data, color = 'black'):
words = ' '.join(data)
cleaned_word = " ".join([word for word in words.split()
and not word.startswith('#')
and word != 'rt'
])
wordcloud = WordCloud(
background_color=color,
width=2500,
height=2000
).generate(cleaned_word)
# using matplotlib to display the images in notebook itself.
plt.figure(1,figsize=(13, 13))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
df_pos = df[ df['emotion'] == 'POS']
df_pos = df_pos['tweets']
wordcloud_draw(df_pos, 'white')
Получите код здесь :)
Спасибо за прочтение; поделитесь, если хотите. Увидимся в следующей истории ✌️
Дополнительная информация: