Введение
Если вы, как и я, занимаетесь наукой о данных в 2020-х годах, то вы можете понять, что индустрия данных растет, развивается и даже меняет парадигмы с головокружительной скоростью.
Так как же практикующему не отставать?
Ну, есть много способов. Есть MOOC, технические подкасты, видео на Youtube и (подсказка) блоги, учебные пособия и бесчисленное множество вещей, которые можно прочитать, просмотреть и сохранить для дальнейшего использования.
Однако при таком огромном количестве информации кажется почти невозможным прочитать каждый ценный блог или учебник, которые вы может появиться в вашей ленте Google, Twitter или где-либо еще (по крайней мере, сразу), и самая лучшая и самая ценная информация часто требует тщательного изучения.
Хорошо, а как мне упорядочить всю эту информацию?
Есть закладки браузера и функциональность браузера для чтения позже, но после 20 папок закладок, полной панели закладок и сотен нетронутых вкладок для чтения позже вы можете обнаружить, что пользовательский интерфейс… неоптимален.
ВОЙТИ В КАРМАН…
Pocket – это онлайн-приложение, которое позволяет сохранять, добавлять в закладки, отмечать теги, выполнять поиск и получать рекомендации для веб-страниц, которые вы найдете в Интернете, с помощью подключаемого модуля для браузера. — в комплекте с мобильными и настольными приложениями в придачу.
На мой взгляд, самая лучшая функция Pocket — это возможность пометки статей. С Pocket вы можете создавать собственные тематические теги и управлять ими. Это дает вам возможность пометить столько тем в статье, сколько вы хотите, чтобы вы могли позже искать в своем личном архиве определенные темы. Эврика!!
ПРОБЛЕМА…
Так что все, что мне нужно сделать, это ввести все теги для нескольких статей, которые я сохраняю каждый день. Это просто. Например, я мог просто добавить тег Python в только что сохраненную новую статью RealPython.com.
Да, но также… Добавьте также тег SQL, потому что эта статья затрагивает этот вопрос.
Тип базы данных, вероятно, также должен быть помечен. И… у меня также есть специальный тег для RealPython.com.
Хм. Возможно, не хватает других тегов. Позвольте мне просто просмотреть мои 158 других потенциальных пользовательских тегов… О, о.
Вы видите проблему?
Естественно, после тысячи статей это становится очень трудоемким.
К счастью, хорошее начало — глубокое погружение в API разработчика Pocket. Оттуда опытный программист может использовать API для загрузки метаданных статей и начать процесс обработки данных, чтобы повысить ценность данных, помимо того, что изначально предоставляет Pocket.
ПРИМЕЧАНИЕ. Еще более важным для этой статьи является то, что специалист по науке о данных на этом этапе может представить себе весь потенциал интеллектуального анализа данных.
Теперь, когда у меня есть данные, как мне их хранить и запрашивать?
Ответ: Поместите это в базу данных!

ВВЕДИТЕ SQLite…
Вы можете создать собственное ETL-приложение для извлечения данных API, загрузки их в базу данных и нормализации, как это сделал я изначально, или сразу перейти к использованию отличного инструмента под названием pocket-to-sqlite от Саймон Уиллисон (соавтор Django и создатель проекта Dataset).
С другими работами Саймона Уиллисона можно ознакомиться в его блоге здесь.
Хорошо. Покажи мне вещи.
Данные:
- Моя личная коллекция из тысяч сохраненных веб-страниц блогов, учебных пособий, технических статей.
Модель:
- NLP: классификация текста с несколькими метками с помощью XGBoost
Инструменты:
- Приложение Карман
- Библиотека Python Pocket-to-SQLite
- Python (но, конечно)
- SQLite (для машинного обучения? да?)
- XGBoost
Цель:
- Автоматическая пометка статей по темам
- Группировка статей для будущей аналитики
Реализация:
- Сбор данных
- Очистка данных
- Машинное обучение: проектирование функций и обучение
- Сохранение, хранение и управление версиями моделей
- Просмотрите выходные данные модели
ВЫПОЛНЕНИЕ
Сбор данных:
Чтобы начать доступ к вашим метаданным Pocket, вам нужно будет взаимодействовать с Pocket API (при условии, конечно, что у вас уже есть учетная запись Pocket и приличная коллекция сохраненных блогов и статей).
Если вы хотите использовать инструмент pocket-to-sqlite (рекомендуется) — просто установите pip и вперед!
pip install pocket-to-sqlite
pocket-to-sqlite auth
pocket-to-sqlite fetch pocket.dbЯ настоятельно рекомендую этот вариант, потому что он выполняет всю работу по сбору и хранению данных за вас!
Если вы хотите создать собственное приложение ETL (более сложное) —то сначала вам нужно получить потребительский ключ Pocket API, выполнив шаги Создать новое приложение здесь. сильный>. Как только вы это сделаете, вам нужно будет сгенерировать связанный токен доступа.
Получение учетных данных Pocket API может быть немного болезненным. К счастью, Саймон Уиллисон снова предлагает инструмент расположенный здесь, который сделает всю работу за вас!
ПРИМЕЧАНИЕ. Имейте в виду, что следование этому второму методу будет означать, что схема и запросы в этой статье не будут соответствовать тому, что вы решите создать самостоятельно.
Чтобы дать некоторое представление о статьях/блогах/руководствах по макияжу, вот количество по тегам и частота ключевых слов среди статей.


Очистка данных
Поскольку это проект НЛП, вы будете работать с неструктурированными текстовыми данными, содержащимися в ваших метаданных Pocket. Вам нужно будет очистить, обработать и спроектировать функцию из ваших текстовых данных.
У меня есть несколько основных функций, которые выполняют дополнительный сбор данных и предварительную обработку данных для текстовых данных.
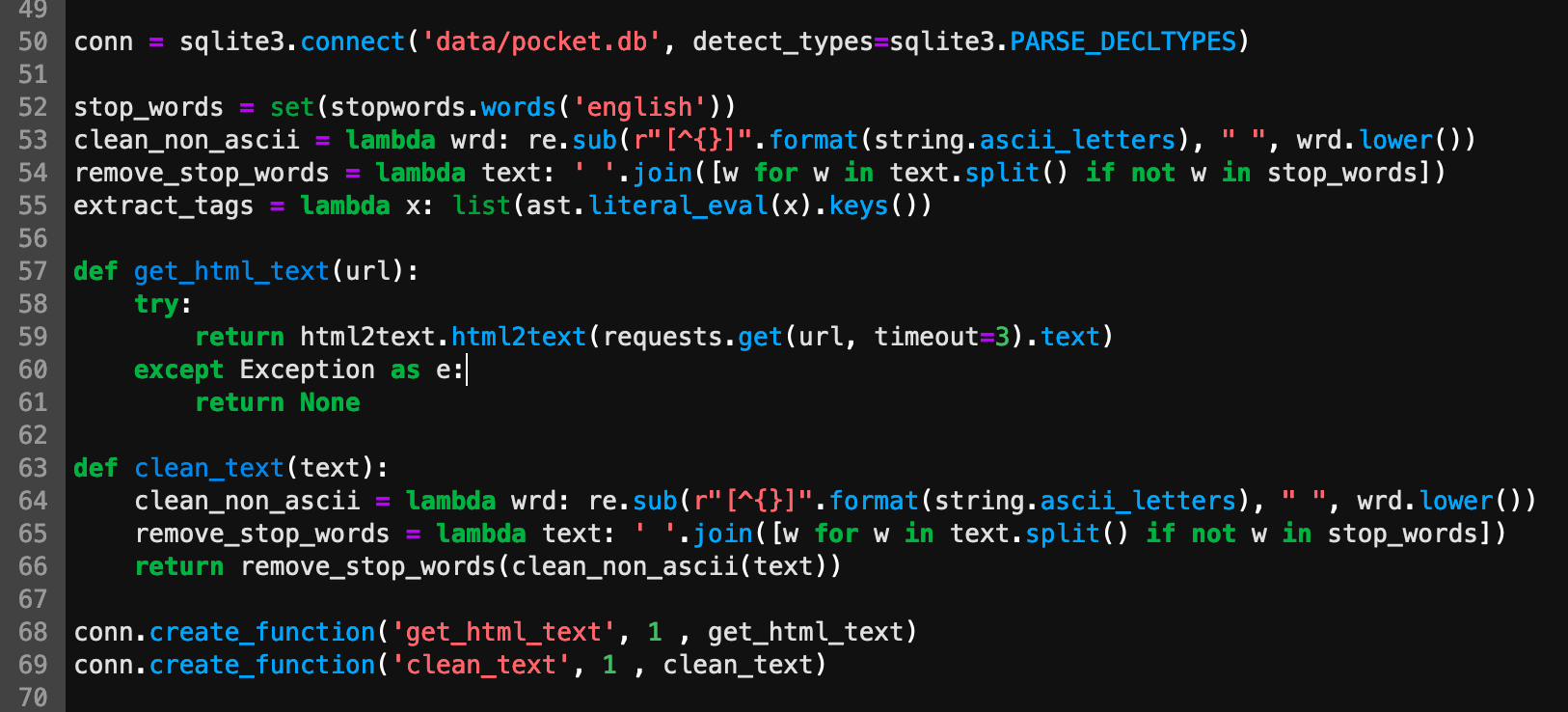
Конечно, вы можете выполнить эти функции в Python. Однако я решил предоставить эти функции Python механизму SQL, используя возможность «create_function» библиотеки SQLite3, и реализовать функции как триггеры SQLite.
conn.create_function('get_html_text', 1 , get_html_text)
conn.create_function('clean_text', 1 , clean_text)
Обратите внимание на модуль html2text. Как следует из названия, этот модуль автоматически извлекает любой текст из HTML-документов, что экономит нам массу работы.

Основное преимущество выполнения Python внутри механизма SQLite заключается в том, что когда я запускаю pocket-to-sqlite fetch pocket.db from внутри процесса Python, он автоматически выполняет функции предварительной обработки кода для вновь импортированных данных. Очень просто!



ПРИМЕЧАНИЕ:
Если вы попытаетесь запустить это вне процесса Python (например, не выполняя код SQLite из Python), это не сработает, потому что эта функция Python не выходит за пределы этого контекста.
Причина, по которой вы можете безошибочно создать триггер со встроенными функциями Python, в первую очередь заключается в том, что SQLite (в отличие от других механизмов SQL) не выполняет проверки программных объектов, таких как представления и триггеры, во время компиляции. Как удобно!👌
ЗАДЕРЖИВАТЬ! ЗАЧЕМ ВКЛАДЫВАТЬ КОД В БАЗУ ДАННЫХ?!
- Версии данных и моделей
- Нет доставки данных. Уменьшенный объем памяти, круговые обращения к БД, сетевая задержка и т. д.
- Возможность совместного использования, повторное использование навыков, повторное использование кода:
Демонстрация гибкости и мощности Python для обработки данных в аналитических рабочих процессах с преобладанием SQL. - Уменьшенная сериализация и переключение контекста:
позволяет избежать всего «несоответствия импеданса»:
ПРИМЕЧАНИЕ. Функциональность SQLite JSON и типы данных Python изначально совместимы с небольшим волшебством (см. ниже, как выполнить автоматическое преобразование типов данных с помощью модуля Python SQLite3).

Машинное обучение: разработка функций:
После того, как данные очищены, обработаны, лемматизированы и т. д., их все еще необходимо векторизовать и математически закодировать.
Существует множество библиотек, инструментов и методов, задействованных в обработке данных НЛП. Тем не менее, большинство из них связано с использованием Term-Frequency/Inverse Document Frequency (TF-IDF), который представляет собой метод взвешивания важности слова по его частоте в отдельных документах и в более крупном массиве текстовых документов.
ПРИМЕЧАНИЕ. TF-IDF также традиционно используется для поиска информации и поддержки функций поисковых систем.


Машинное обучение: Обучение:
Модель, выбранная для этого проекта, — классификатор XGBoost.
В то время как сравнивались другие модели, стало ясно, что обучение индивидуальной модели для каждого существующего тега было лучшим способом решения часто возникающей проблемы дисбаланса классов классификационные модели.
Спасибо за заслуги:после нескольких неудачных попыток итераций модели я пересмотрел и адаптировал некоторые из моих обучающих кодов из заявок на участие в соревнованиях Kaggle, которые легко решали проблемы, аналогичные моим собственным.
Одно предостережение при адаптации ваших собственных решений из фрагментов, которые вы найдете на Stack Overflow, Kaggle и т. д., заключается в том, что вам действительно нужно сначала понять, что делает их код и почему ваш код не работать раньше. В противном случае вы только обсчитываете свой рост как специалиста по науке о данных! Копипаста это плохо, ммкей?
При этом спасибо Kaggle чуваки!

ПРИМЕЧАНИЕ. Существует несколько других методов для решения проблемы дисбаланса классов, таких как избыточная выборка, недостаточная выборка, а также их дополнительные варианты. Однако сложность повторной выборки для более чем 158 тегов была довольно высокой, и обучение на моделях с несколькими тегами не было непосильным занятием.
Сохранение, хранение и управление версиями моделей:
Наконец, только что обученная модель обрабатывается и сохраняется в базе данных SQLite.
Принято считать, что практики должны сохранять BLOB (большие двоичные объекты) локально на диск, но чтение/запись BLOB в SQLite вместо файловой системы на 35% быстрее, чем на диск. Так что на самом деле это лучшая практика (особенно при работе с SQLite).
Кроме того, сохранение обработанных моделей, их метаданных и идентификаторов, которые связывают их с отдельными прогнозируемыми тегами статей, позволяет осуществлять продольное версионирование моделей, онлайн-мониторинг отклонений моделей, возможность отката или переключения моделей в рабочей среде, а также дополнительную аналитику моделей, такую как в качестве A/B-тестирования.
Все это возможно благодаря использованию модуля SQLite3 для создания пользовательских типов данных Python (см. ниже).


Просмотр вывода модели:
Я (несколько произвольно) выбрал пороговое значение для выходной вероятности модели, что каждый конкретный тег был связан со статьей.
Эта часть потребовала ручной выборочной проверки ряда вероятностей моделей для ряда статей, чтобы решить, какое значение тегов было точным.
CREATE VIEW v_new_tags as
with predicted_tags as (
select item_id,
key as tag --*
from json_each(m.model_probabilities), v_latest_predictions m
where cast(value as float) > 0.10
order by 1
),
existing_tags as (select item_id, key tag
from json_each(a.tags), articles a
where a.tags is not null),
new_tags as (select *
from (select *
from predicted_tags
except
select *
from existing_tags))
select *
from new_tags
Беглый взгляд на приведенный ниже рисунок интуитивно показывает, что предсказанные теги являются действительными и достаточно подробными, чтобы повысить реальную ценность решения моей проблемы!

ЭЛЬ ФИН.

Любые вопросы!?
Твиттер: @jmnickerson
Репозиторий Github: https://github.com/jmnickerson05/pocket_multi_label_tagger