
Введение и обзор проблемы:
Индекс качества воздуха (AQI) — это инструмент для демонстрации состояния качества воздуха. Он преобразует комплексные данные о качестве воздуха по различным загрязнителям в одно число и цвет. AQI имеет шесть категорий качества воздуха. Это: «хорошо», «удовлетворительно», «умеренно загрязнено», «плохо», «очень плохо» и «тяжело». Каждая из этих категорий определяется на основе значений концентрации загрязнителей воздуха в окружающей среде и их вероятного воздействия на здоровье. По мере увеличения AQI все больший процент населения, вероятно, будет испытывать последствия для здоровья.
Постановка задачи:
Создайте модель для прогнозирования уровней PM2,5.
Сбор данных:
Сначала я соберу данные с помощью веб-скраппинга. Я извлекаю данные из http://en.tutiempo.net/
С помощью этого веб-скраппинга я могу извлечь независимые функции, которые имеют средние данные за каждый день.
Теперь я собираюсь собрать PM2.5, который является зависимой функцией с 2013 по 2018 год. Итак, для PM2.5 я могу получить данные с Weathermap.com.
Но при извлечении PM2.5 я могу получать данные за каждый час. Итак, я объединим данные и возьму среднее значение за день. И данные не чистые, я тоже собираюсь заняться очисткой.
Я также могу построить график между PM2.5 и Day.

Я собираюсь импортировать файл Plot_AQI.py в свой следующий BeautifulSoup, чтобы извлечь данные из html.
Я буду комбинировать как независимые, так и зависимые переменные.
Итак, наши данные будут выглядеть примерно так.

Мы прекрасно можем удалить зависимые и независимые переменные.
Исследовательский анализ данных (EDA):
Исследовательский анализ данных или (EDA) - это понимание наборов данных путем суммирования их основных характеристик, часто отображающих их визуально. Этот шаг очень важен, особенно когда мы приходим к моделированию данных для применения машинного обучения.
Импорт необходимых библиотек для EDA:
Загрузка данных во фрейм данных:

Проверка нулевых значений:

Удаление отсутствующих значений:
После удаления значений:

Разделение независимых и зависимых функций:


Парный сюжет:
Pair Plot создает матрицу взаимосвязей между каждой переменной в ваших данных для мгновенного изучения наших данных.


Корреляционная матрица с тепловой картой
Корреляция указывает, как объекты связаны друг с другом или с целевой переменной.
Корреляция может быть положительной (увеличение одного значения признака увеличивает значение целевой переменной) или отрицательной (увеличение одного значения признака уменьшает значение целевой переменной).
Тепловая карта позволяет легко определить, какие функции больше всего связаны с целевой переменной, мы построим тепловую карту коррелированных функций, используя библиотеку seaborn.

Index(['T', 'TM', 'Tm', 'SLP', 'H', 'VV', 'V', 'VM', 'PM 2.5'], dtype='object')
Важность функции
Вы можете получить важность каждой функции вашего набора данных, используя свойство важности функции модели.
Важность функции дает вам оценку для каждой функции ваших данных, чем выше оценка, тем важнее или релевантнее функция по отношению к вашей выходной переменной.
Важность функций — это встроенный класс, который поставляется с регрессором на основе дерева. Мы будем использовать дополнительный регрессор дерева для извлечения 10 лучших функций для набора данных.
ExtraTreesRegressor()

[0.19026977 0.10797685 0.18725173 0.14832213 0.08656328 0.18485114 0.05135576 0.04340933]

Тренировочный тестовый сплит
Выбор и обучение моделей машинного обучения:
Поскольку это проблема регрессии, я решил обучить следующие модели:
- Линейная регрессия
- Регрессор дерева решений
- Регрессор случайного леса
- Регрессор XGBOOST
- ЭНН
Это простой 4-этапный процесс:
- Создайте экземпляр класса модели.
- Обучите модель с помощью метода fit().
- Делать предсказания.
- Оценка модели с использованием средней абсолютной ошибки (MAE), среднеквадратичной ошибки (MSE), среднеквадратичной ошибки (RMSE).
Линейная регрессия

LinearRegression()
array([ -2.69090829, 0.46219975, -3.86705184, -0.04494855,
-1.21193616, -40.11490762, -2.53563257, 0.56148181])
448.11616967588736
Получение частоты ошибок относительно x_train и y_train.
Coefficient of determination R^2 <-- on train set: 0.551516808175875
Получение частоты ошибок относительно x_test и y_test.
Coefficient of determination R^2 <-- on train set: 0.4852533130856792
0.4710569304807392
Оценка модели
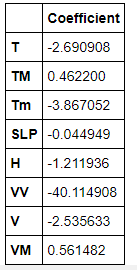
Интерпретация коэффициентов:
При фиксированных всех других характеристиках увеличение T на 1 единицу связано со снижением AQI PM2.5 на 2,690.
Удерживая все остальные характеристики фиксированными, увеличение TM на 1 единицу связано с увеличением AQI PM 2,5 на 0,46.

Разница между y_test и предсказанием выглядит почти хорошо.

MAE: 44.836241266286365 MSE: 3687.5430309324165 RMSE: 60.72514331751236
Создание файла pickle для развертывания:
Сравнение линейной, гребенчатой и лассо-регрессии
Линейная регрессия
-3686.201777339885
Ридж-регрессия
Я собираюсь реализовать регрессию Риджа и посмотреть, смогу ли я получить значение, которое намного ближе к нулю, по сравнению с линейной регрессией.
Предположим, что если я получу значение -3500, которое намного ближе к нулю, я выберу модель гребневой регрессии.
GridSearchCV(cv=5, estimator=Ridge(),
param_grid={'alpha': [1e-15, 1e-10, 1e-08, 0.001, 0.01, 1, 5, 10,
20, 30, 35, 40]},
scoring='neg_mean_squared_error')
{'alpha': 40}
-3664.3648996071743
Лассо-регрессия
Лассо-регрессия похожа на гребенчатую регрессию, но немного лучше, чем гребневая.
GridSearchCV(cv=5, estimator=Lasso(),
param_grid={'alpha': [1e-15, 1e-10, 1e-08, 0.001, 0.01, 1, 5, 10,
20, 30, 35, 40]},
scoring='neg_mean_squared_error')
{'alpha': 1}
-3666.78325343702
Оценка модели


MAE: 44.50831198875126 MSE: 3627.8109390424697 RMSE: 60.2313119485411
Создание файла pickle для развертывания:
Регрессия дерева решений
DecisionTreeRegressor()
Coefficient of determination R^2 <-- on train set: 1.0
Coefficient of determination R^2 <-- on test set: 0.6836721835465965
0.4315969249390227
Поскольку мы видим, что наша модель переоснащается, мы выполним настройку гиперпараметров.
Визуализация дерева
['T', 'TM', 'Tm', 'SLP', 'H', 'VV', 'V', 'VM']
Оценка модели

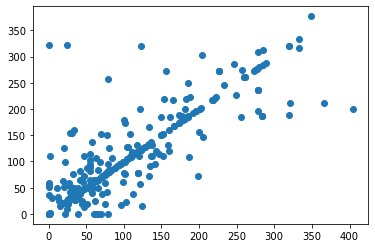
Регрессор дерева решений по настройке гиперпараметров
Fitting 10 folds for each of 10240 candidates, totalling 102400 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 4 concurrent workers. [Parallel(n_jobs=-1)]: Done 24 tasks | elapsed: 3.1s [Parallel(n_jobs=-1)]: Done 1108 tasks | elapsed: 6.3s [Parallel(n_jobs=-1)]: Done 3668 tasks | elapsed: 13.1s [Parallel(n_jobs=-1)]: Done 7252 tasks | elapsed: 21.8s [Parallel(n_jobs=-1)]: Done 11860 tasks | elapsed: 33.0s [Parallel(n_jobs=-1)]: Done 17492 tasks | elapsed: 47.9s [Parallel(n_jobs=-1)]: Done 24148 tasks | elapsed: 1.1min [Parallel(n_jobs=-1)]: Done 31828 tasks | elapsed: 1.5min [Parallel(n_jobs=-1)]: Done 40532 tasks | elapsed: 2.0min [Parallel(n_jobs=-1)]: Done 50260 tasks | elapsed: 2.4min [Parallel(n_jobs=-1)]: Done 61012 tasks | elapsed: 3.0min [Parallel(n_jobs=-1)]: Done 72788 tasks | elapsed: 3.6min [Parallel(n_jobs=-1)]: Done 85588 tasks | elapsed: 4.3min [Parallel(n_jobs=-1)]: Done 99412 tasks | elapsed: 5.0min [Parallel(n_jobs=-1)]: Done 102400 out of 102400 | elapsed: 5.1min finished Time taken: 0 hours 5 minutes and 8.58 seconds.
{'max_depth': 8,
'max_features': None,
'max_leaf_nodes': 20,
'min_samples_leaf': 4,
'min_weight_fraction_leaf': 0.1,
'splitter': 'best'}
-3131.6489619178874

MAE: 23.674504573170733 MSE: 2266.109651031081 RMSE: 47.60367266326287
Создание файла pickle для развертывания:
Регрессор случайного леса
RandomForestRegressor()
Coefficient of determination R^2 <-- on train set: 0.9737825275525134
Coefficient of determination R^2 <-- on train set: 0.7790383481598548
0.7298539095199639
Оценка модели

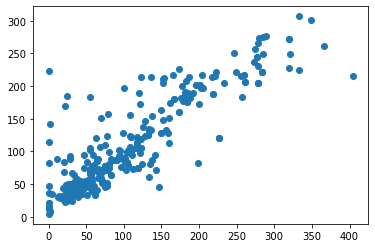
Настройка гиперпараметров
[100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200]
{'n_estimators': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200], 'max_features': ['auto', 'sqrt'], 'max_depth': [5, 10, 15, 20, 25, 30], 'min_samples_split': [2, 5, 10, 15, 100], 'min_samples_leaf': [1, 2, 5, 10]}
RandomizedSearchCV(cv=5, estimator=RandomForestRegressor(), n_iter=100,
n_jobs=1,
param_distributions={'max_depth': [5, 10, 15, 20, 25, 30],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 5, 10],
'min_samples_split': [2, 5, 10, 15,
100],
'n_estimators': [100, 200, 300, 400,
500, 600, 700, 800,
900, 1000, 1100,
1200]},
random_state=42, scoring='neg_mean_squared_error',
verbose=2)
{'n_estimators': 500,
'min_samples_split': 2,
'min_samples_leaf': 1,
'max_features': 'sqrt',
'max_depth': 15}
-1541.722112688083

MAE: 24.300982342479678 MSE: 1582.925388467951 RMSE: 39.78599487844876
Создание файла pickle для развертывания:
Регрессор XGBOOST
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
Coefficient of determination R^2 <-- on train set: 0.9997717196147036
Coefficient of determination R^2 <-- on train set: 0.8123312956923813
0.725127678258157
Оценка модели


Настройка гиперпараметров
[100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200]
{'n_estimators': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200], 'learning_rate': ['0.05', '0.1', '0.2', '0.3', '0.5', '0.6'], 'max_depth': [5, 10, 15, 20, 25, 30], 'subsample': [0.7, 0.6, 0.8], 'min_child_weight': [3, 4, 5, 6, 7]}
RandomizedSearchCV(cv=5,
estimator=XGBRegressor(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, gamma=None,
gpu_id=None, importance_type='gain',
interaction_constraints=None,
learning_rate=None,
max_delta_step=None, max_depth=None,
min_child_weight=None, missing=nan,
monotone_constraints=None,
n_estimators=100, n...
validate_parameters=None,
verbosity=None),
n_iter=100, n_jobs=1,
param_distributions={'learning_rate': ['0.05', '0.1', '0.2',
'0.3', '0.5', '0.6'],
'max_depth': [5, 10, 15, 20, 25, 30],
'min_child_weight': [3, 4, 5, 6, 7],
'n_estimators': [100, 200, 300, 400,
500, 600, 700, 800,
900, 1000, 1100,
1200],
'subsample': [0.7, 0.6, 0.8]},
random_state=42, scoring='neg_mean_squared_error',
verbose=2)
{'subsample': 0.8,
'n_estimators': 1100,
'min_child_weight': 3,
'max_depth': 30,
'learning_rate': '0.05'}
-1380.5446667169047


MAE: 19.580280400079683 MSE: 1344.4213246754996 RMSE: 36.66635139573475
Создание файла pickle для развертывания:
АНЯ

Оценка модели


MAE: 25.245581808943093 MSE: 1681.8142776645072 RMSE: 41.009929013161035
Таким образом, XGBOOST Regressor показывает хорошие результаты среди всех моделей.
Теперь мы собираемся развернуть нашу модель на Heroku.
Настройка для развертывания
Это папка, которую мы хотим развернуть на Heroku.

Статический каталог содержит ваши файлы CSS, а шаблон содержит файл HTML, который используется для рендеринга.
Создайте файл app.py:
Ниже показано, как выглядит мой файл result.html.
Мы почти закончили с частью кодирования, и теперь пришло время развернуть наше приложение flask.
Перед развертыванием приложения сначала проверьте приложение flask на локальном хосте.
Шаги развертывания
- Войдите в свою учетную запись Heroku с помощью интерфейса командной строки
логин героку
2. Создайте веб-приложение на Heroku
Мы можем создать новое приложение на Heroku, используя следующую команду
heroku создайте your_app_name
3. Создайте файл requirements.txt в том же каталоге проекта.
4. Создайте Procfile
Procfile – это файл процесса, необходимый для всех приложений Heroku.
Procfile указывает команды, которые выполняются приложением при запуске.
5. Теперь нажмите на опцию Github и выберите проект из github, а затем разверните его.
Наше приложение запущено. Теперь мы можем увидеть наше веб-приложение, используя сгенерированный URL.
https://airqualityprediction20.herokuapp.com/
Исходный код доступен на Github https://github.com/INZA111/Air-Quality-Index.