Как новичок в R, вместо того, чтобы быть шокированным перьями и способностями R, я стремлюсь применить то, что я узнал, для анализа данных в реальном мире. Недавно я получил набор данных от Kaggle House Prices и обнаружил, что это отличный шанс для меня использовать свои навыки R для анализа данных. Как начать наше путешествие.
Для начала предлагаю сначала скачать набор данных, а также посмотреть его описания полей. Кратко рассмотрим набор данных. Прочитайте данные, как показано ниже.
> train <- fread(‘train.csv’,colClasses=c(‘MiscFeature’ = “character”, ‘PoolQC’ = ‘character’, ‘Alley’ = ‘character’)) > dim(train) [1] 1460 81
В этом наборе данных 81 столбец и 1460 строк. Количество столбцов довольно велико, и начать с этого числа довольно сложно. Не беспокойтесь, пусть разделит столбцы по числовым и символьным.
> sapply(train, is.character)
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities LotConfig LandSlope
FALSE FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Neighborhood Condition1 Condition2 BldgType HouseStyle OverallQual OverallCond YearBuilt YearRemodAdd RoofStyle RoofMatl Exterior1st
TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
Exterior2nd MasVnrType MasVnrArea ExterQual ExterCond Foundation BsmtQual BsmtCond BsmtExposure BsmtFinType1 BsmtFinSF1 BsmtFinType2
TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE TRUE
BsmtFinSF2 BsmtUnfSF TotalBsmtSF Heating HeatingQC CentralAir Electrical 1stFlrSF 2ndFlrSF LowQualFinSF GrLivArea BsmtFullBath
FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
BsmtHalfBath FullBath HalfBath BedroomAbvGr KitchenAbvGr KitchenQual TotRmsAbvGrd Functional Fireplaces FireplaceQu GarageType GarageYrBlt
FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE
GarageFinish GarageCars GarageArea GarageQual GarageCond PavedDrive WoodDeckSF OpenPorchSF EnclosedPorch 3SsnPorch ScreenPorch PoolArea
TRUE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice
TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE FALSE
Приведенная выше команда сообщает вам, является ли столбец символьным или нет. Нам нужно взять все столбцы, которые отмечены как TRUE. К счастью, R предоставляет нам удобный способ сделать это:
> charColumns <- colnames(train)[which(sapply(train, is.character))] > charColumns [1] "MSZoning" "Street" "Alley" "LotShape" "LandContour" "Utilities" "LotConfig" "LandSlope" "Neighborhood" "Condition1" [11] "Condition2" "BldgType" "HouseStyle" "RoofStyle" "RoofMatl" "Exterior1st" "Exterior2nd" "MasVnrType" "ExterQual" "ExterCond" [21] "Foundation" "BsmtQual" "BsmtCond" "BsmtExposure" "BsmtFinType1" "BsmtFinType2" "Heating" "HeatingQC" "CentralAir" "Electrical" [31] "KitchenQual" "Functional" "FireplaceQu" "GarageType" "GarageFinish" "GarageQual" "GarageCond" "PavedDrive" "PoolQC" "Fence" [41] "MiscFeature" "SaleType" "SaleCondition"
Команда which дает вам индексы логического объекта и получает совпадающие имена столбцов, комбинируя его вывод с массивом из colnames(train). Теперь давайте сделаем то же самое, чтобы найти все числовые столбцы:
> numColumns <- colnames(train)[which(sapply(train, is.numeric))] > numColumns [1] "Id" "MSSubClass" "LotFrontage" "LotArea" "OverallQual" "OverallCond" "YearBuilt" "YearRemodAdd" "MasVnrArea" "BsmtFinSF1" [11] "BsmtFinSF2" "BsmtUnfSF" "TotalBsmtSF" "1stFlrSF" "2ndFlrSF" "LowQualFinSF" "GrLivArea" "BsmtFullBath" "BsmtHalfBath" "FullBath" [21] "HalfBath" "BedroomAbvGr" "KitchenAbvGr" "TotRmsAbvGrd" "Fireplaces" "GarageYrBlt" "GarageCars" "GarageArea" "WoodDeckSF" "OpenPorchSF" [31] "EnclosedPorch" "3SsnPorch" "ScreenPorch" "PoolArea" "MiscVal" "MoSold" "YrSold" "SalePrice"
`charColumns` и numColumns хранят имена столбцов для символьных и числовых значений. Нам нужно взять значения из этих столбцов. Это где .SD и .SDcols вступают в игру.
> numTrain <- train[, .SD, .SDcols=numColumns] > charTrain <- train[, .SD, .SDcols=charColumns]
.SD обозначает данные подмножества. .SDcols дает столбец в возвращаемом значении. Поскольку мы уже разделили набор данных поезда на числовой и символьный. Далее мы нанесем каждый из них в виде столбца символов на ggplot.
Барплотс Сюжет
Поскольку мы разделили набор данных на символьный (переменная категории) и числовой (переменная плотности). Позвольте построить их в этом разделе.
> df <- data.frame(value=charTrain[[1]]) > ggplot(data=df, aes(x=factor(value))) + stat_count()
Первое, что нам нужно сделать, это создать фрейм данных из обучающего набора и присвоить его переменной df. В этом примере я выбрал первый столбец, который является MSZonin, из набора данныхcharTrain. Затем используйте ggplot для построения значения в виде гистограммы, как показано ниже.

Чтобы убедиться, что график имеет правильное значение. Давайте проверим количество каждого значения в этом фрейме данных.
> length(df[df['value']=='RL']) [1] 1151 > length(df[df['value']=='FV']) [1] 65 > length(df[df['value']=='C (all)']) [1] 10 > length(df[df['value']=='RM']) [1] 218 > length(df[df['value']=='RH']) [1] 16
Это довольно близко к тому, что мы наметили. Вы можете построить несколько столбцов из набора данных поезда. Возьмем еще один столбец из charTrai, это Neightbarhood.
> ndf <- data.frame(Neighborhood=charTrain[['Neighborhood']]) > ggplot(data=ndf, aes(x=Neighborhood)) + stat_count()

Ой, метки на x axial выглядят не очень красиво. Используйте приведенный ниже код, чтобы отрегулировать метку по оси X на 90 градусов.
> ggplot(data=ndf, aes(x=Neighborhood)) + stat_count() + xlab(colnames(ndf)) + theme_light() + theme(axis.text.x = element_text(angle = 90, hjust =1))

Плотность График
Для числовых переменных обычно используется график плотности для представления.
> den <- data.frame(x=numTrain[['MSSubClass']], SalePrice=numTrain$SalePrice)
> ggplot(data=den) + geom_line(aes(x=x), stat='density', size=1, alpha=1.0) + xlab('MSSubClass')
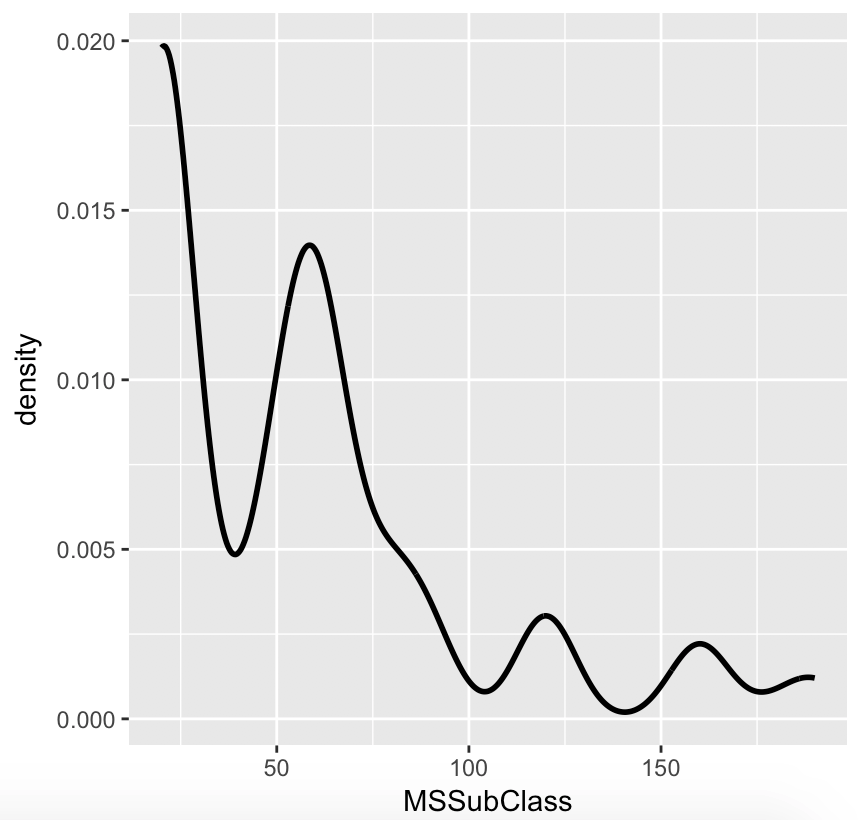
MSSubClassиспользуется в этом примере. Вы можете построить другие переменные на основе приведенного выше кода.
Ссылка
Подробный исследовательский анализ данных с использованием R | Kaggle
Изменить описаниеwww.kaggle.com