Руководство по расширенной фильтрации и обработке данных в pandas с использованием loc, iloc, apply и lambda.

Ранее мы рассмотрели, как обрабатывать базовые данные с помощью Pandas. Иногда основы просто не подходят, поэтому могут пригодиться loc, iloc, метод apply и лямбда-функции.
Следуя нашему путешествию с данными об убыли (кому не захочется углубляться в мелкие грязные подробности историй увольняющихся сотрудников), предположим, что некоторые из людей, интересующихся базовыми данными вашего красивого резюме, теперь хотели бы скорректировать данные слегка просто так, чтобы они больше отражали то, как, по их мнению, должны выглядеть данные.
В этой статье я буду использовать Набор данных IBM HR Analytics о сокращении и производительности сотрудников от Kaggle.
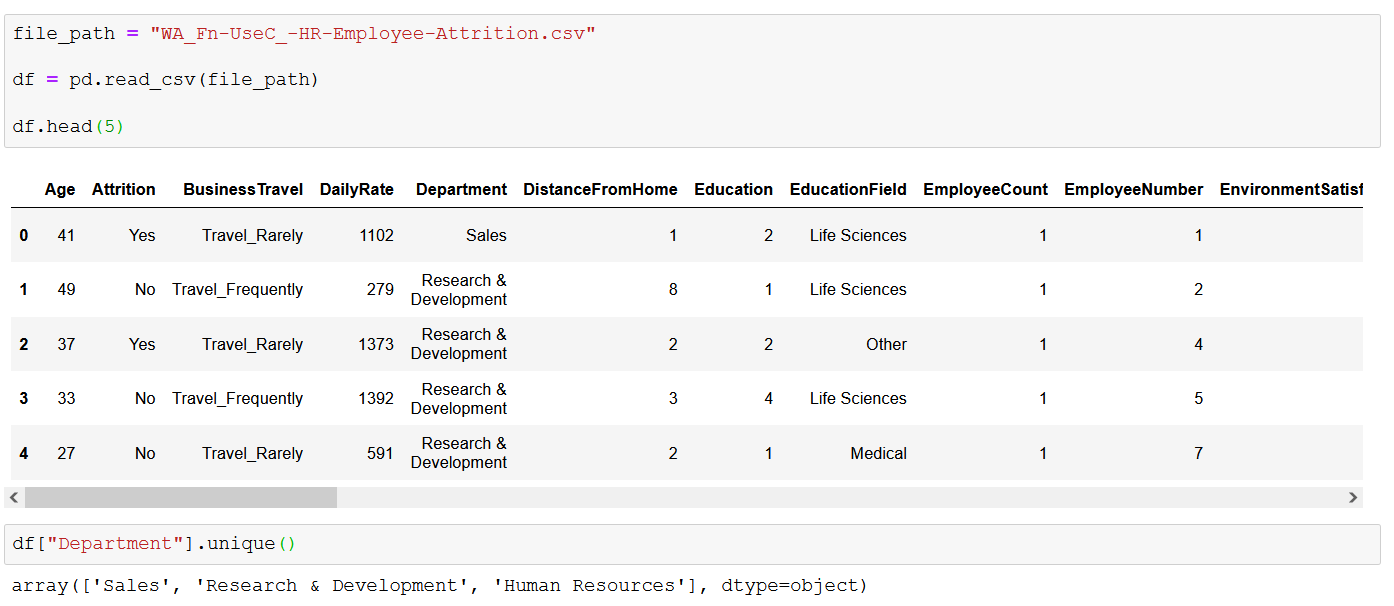
Здесь у нас есть исходные данные об истощении IBM с перечислением уникальных названий отделов. Наша первая задача — переименовать значения «Исследования и разработки» в «Исследования и разработки», чтобы все было кратко и понятно. Давайте воспользуемся loc, чтобы быстро решить эту проблему.
DataFrame.loc
Вы можете использовать метод loc для доступа к определенным строкам и столбцам в DataFrame, используя либо метки, либо логический массив. Простой пример — выбрать вторую строку (метка 1) и столбцы «Возраст», «Увольнение» и «Отдел» с помощью метода loc :

Как видите, первый аргумент — это метка индекса, которую мы хотим получить, а второй — столбец/список интересующих нас столбцов. Конечно, вы можете выбрать несколько строк либо со списком меток, либо даже с диапазонами:


Обратите внимание, что при выборе среза 1:5 также включается 5-й индекс (6-я строка), в отличие от обычного среза в Python, где верхняя граница является исключающей.
Самое интересное начинается, когда вы понимаете, что можете использовать логический массив (по сути, список, содержащий только значения True/False) для фильтрации строк. Это позволяет вам писать логические операторы в вашем первом аргументе, возвращающем логическое значение — оператор будет оцениваться для всех строк, возвращая те, которые дают True:
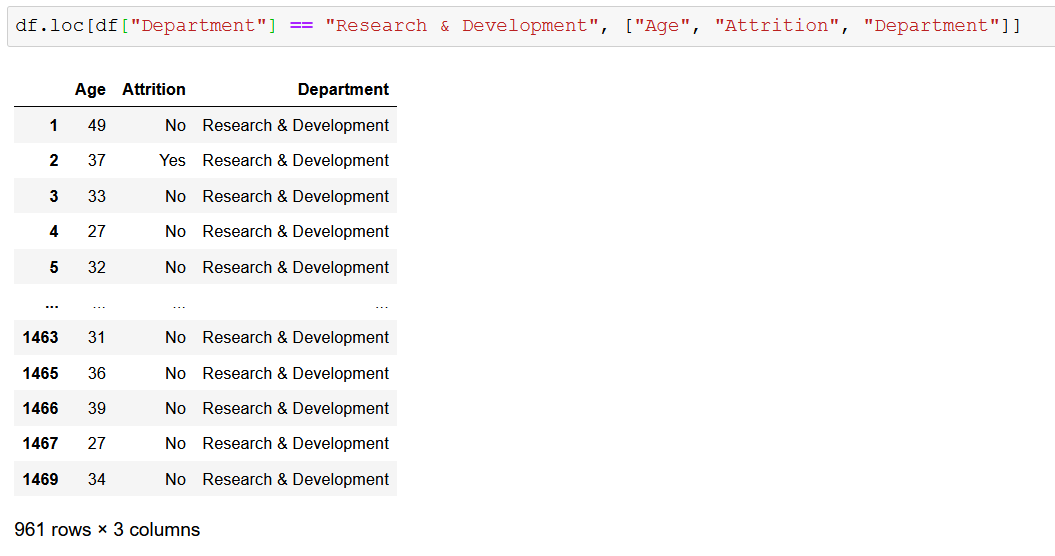
Еще одна настройка, и мы можем переименовать «Исследования и разработки» в «Исследования и разработки»: мы можем использовать loc для присвоения значений определенным полям строки/столбца, по которым мы фильтруем:
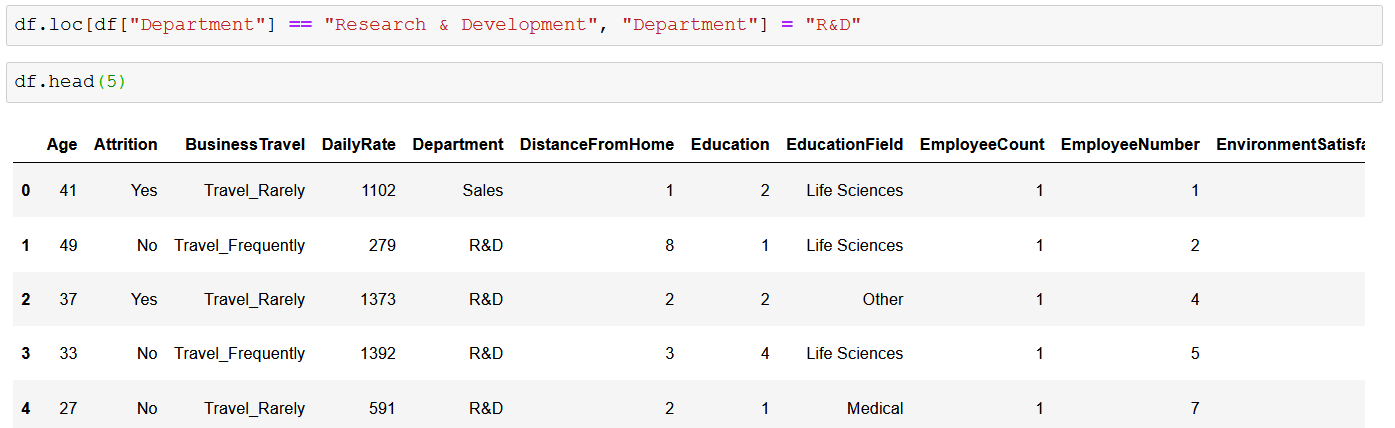
С помощью этого метода мы можем изменить несколько столбцов за один раз, просто нужно указать список столбцов и значений, которые мы хотели бы использовать:
Если вы хотите, чтобы я получал кофеин за создание большего количества подобного контента, пожалуйста, поддержите меня, просто выпив чашечку кофе.

Кадр данных.iloc
Идея iloc такая же, как и у loc, с той лишь разницей, что, как предполагает 'i' в названии, это полностью на основе целых чисел при предоставлении позиций для выбора. Первый аргумент — это строка (строки), второй — столбец (столбцы), который вы хотите выбрать. Обнуление на пересечении первой строки и третьего столбца будет выглядеть так:

Мы также можем использовать список целых чисел и слайсеров для выбора:
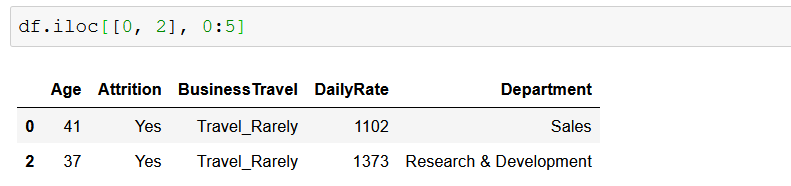
Можно применить и более сложную логику — представьте, что вы хотите вернуть столбцы только в том случае, если длина имени столбца четна. Впрочем, не спрашивайте, почему.
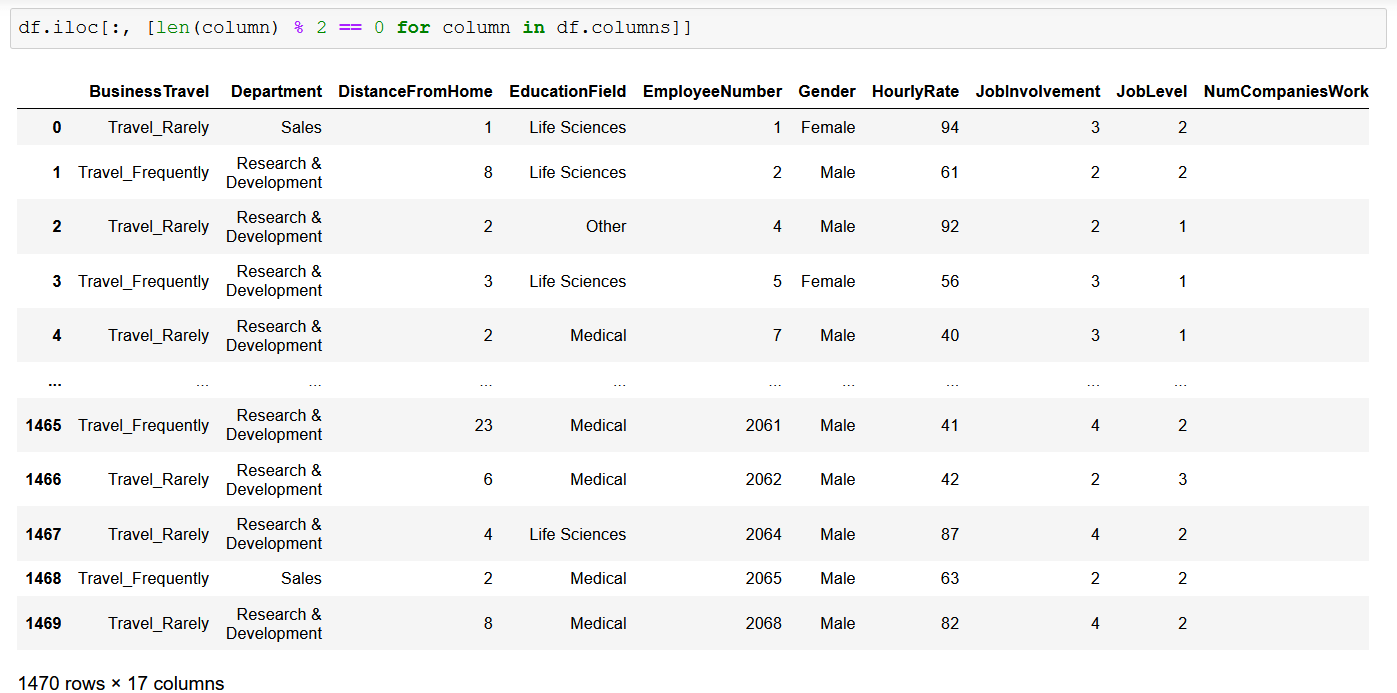
Обратите внимание: если вы хотите вернуть все строки, вы можете просто написать «:» в первом аргументе. Это верно для второго ввода (столбца), однако, если вы просто не предоставите его вообще, он все равно выберет все столбцы.
Применить функцию к сериям
Предположим, что мы хотели бы расширить измерение EducationalField, создав новый столбец, классифицирующий значения в нем — упростите его, скажем, «Инженер» или «Не инженер»: любой, у кого есть «Техническая степень», получает «Инженер» (я знаю Я знаю, но дайте мне веревку, пожалуйста, это просто пример).
Мы можем использовать метод apply, чтобы вызвать функцию для каждого значения столбца и присвоить возвращаемое значение этой функции новому столбцу:
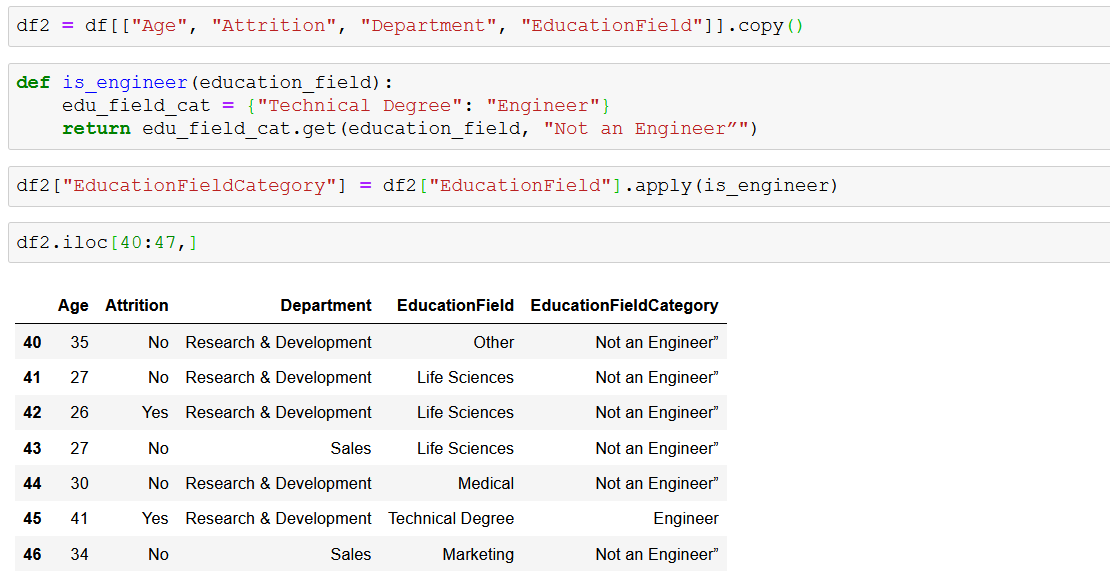
Я определил функцию is_engineer так, чтобы она возвращала «Инженер», когда входными данными является «Техническая степень», в любом другом случае возвращала «Не инженер» — словарь позволяет вам легко расширять классификацию в будущем, если хотите, и Dictionary.get() позволяет указать возвращаемое значение по умолчанию из словаря, если ключ отсутствует в коллекции. Обратите внимание, что вы не можете поставить () после имени функции, которое вы указали в качестве параметра для применения — вы не вызываете функцию при выполнении этой строки, это делает применение, поэтому достаточно указать только имя.
Остальная часть синтаксиса должна быть уже знакома: я определил новую серию, определив ее выражением в левой части присваивания, таким образом добавив новый столбец в наш DataFrame.
Лямбда-функции
Лямбда-выражения в Python — это анонимные функции, обычно небольшие фрагменты кода, выражающие логику, которая требует некоторой сложности, но не слишком большой, чтобы определить реальную функцию для дальнейшего использования. У RealPython есть классная статья на эту тему, если вы хотите узнать больше о лямбда-выражениях, помимо моего урезанного однострочника, чтобы охватить стоящую перед вами задачу, я предлагаю вам уделить ей 20 минут, это стоит вашего времени.
Давайте возьмем наш предыдущий пример и используем лямбда-функцию для решения задачи:
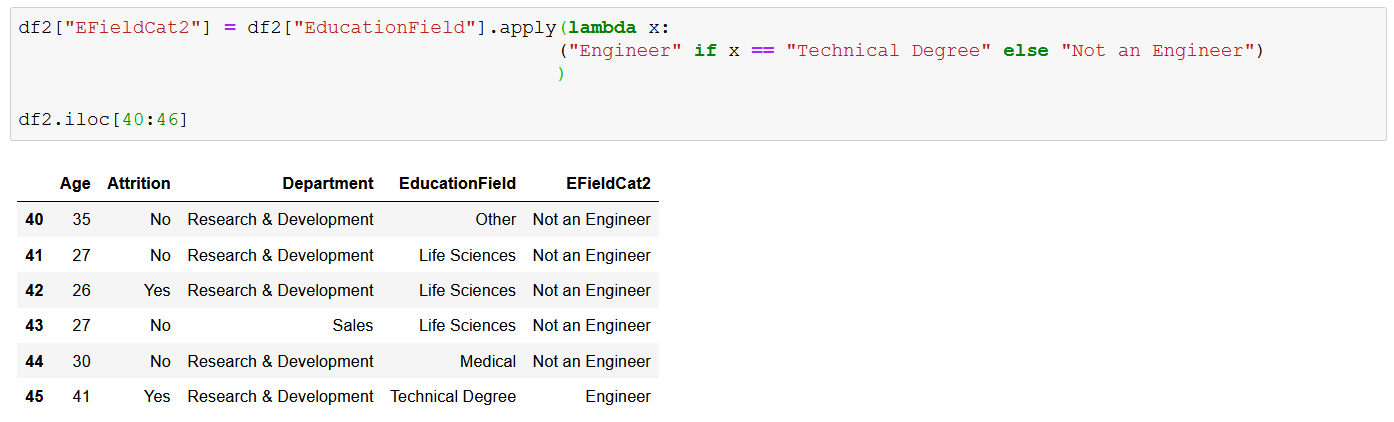
Теперь можно бесконечно спорить, какой подход лучше, в таких простых случаях все зависит от вашего вкуса и стиля. Однако более сложная логика потребует правильного определения имен функций: у лямбда-выражений есть ограничения, и удобочитаемость может быстро стать проблемой, если вы делаете сложные вещи.
Вышеописанные методы могут предоставить вам широкий спектр вариантов для дальнейшей работы с наборами данных, требующих большего, чем просто базовые манипуляции — варианты использования практически бесконечны, вам просто нужно почувствовать эти подходы, чтобы они могли быть естественными, когда нужный. Документация для loc и iloc настоятельно рекомендуется, не упустите возможность ознакомиться с ней.
Это для этой темы. Спасибо за чтение.