
Оглавление
RCNN

Богатые иерархии функций для точного обнаружения объектов и семантической сегментации
Архитектура
RCCN состоит из трех модулей:
- Первый генерирует независимые от категорий предложения регионов. Эти предложения определяют набор обнаружений-кандидатов, доступных нашему детектору.
- Второй модуль — это большая сверточная нейронная сеть, которая извлекает вектор признаков фиксированной длины из каждой области.
- Третий модуль представляет собой набор линейных SVM для конкретных классов.
В то время как R-CNN не зависит от метода предложения конкретного региона, выборочный поиск является наиболее часто используемым методом для обеспечения контролируемого сравнения с предыдущей работой по обнаружению.
Выполнение
Во время тестирования мы запускаем выборочный поиск изображений, чтобы извлечь около 2000 предложений по регионам. Мы деформируем каждое предложение и передаем его через CNN для вычисления характеристик. Затем для каждого класса мы оцениваем каждый извлеченный вектор признаков, используя SVM, обученный для этого класса. Учитывая все оцененные области в изображении, мы применяем жадное немаксимальное подавление (для каждого класса независимо), которое отклоняет область, если она имеет пересечение над объединением (IoU), перекрывающееся с выбранной областью с более высокой оценкой, превышающей изученный порог.
Быстрый RCNN

Ограничения RCNN и SPPnets
- Обучение представляет собой многоэтапный конвейер: R-CNN сначала настраивает ConvNet на предложениях объектов, используя потерю журнала. Затем он приспосабливает SVM к функциям ConvNet. Эти SVM действуют как детекторы объектов, заменяя классификатор softmax, полученный путем точной настройки. На третьем этапе обучения изучаются регрессоры ограничивающей рамки.
- Обучение занимает много места и времени: для обучения SVM и регрессора с ограничивающей рамкой функции извлекаются из каждого предложения объекта в каждом изображении и записываются на диск. Для этих функций требуются сотни гигабайт дискового пространства.
- Обнаружение объектов происходит медленно: во время тестирования функции извлекаются из каждого предложения объекта в каждом тестовом изображении.
R-CNN работает медленно, поскольку выполняет прямой проход ConvNet для каждого предложения объекта без совместного использования вычислений.
Сети объединения пространственных пирамид (SPPnets) были предложены для ускорения R-CNN за счет совместного использования вычислений. Метод SPPnet вычисляет карту сверточных признаков для всего входного изображения, а затем классифицирует каждое предложение объекта, используя вектор признаков, извлеченный из общей карты признаков.
Быстрая архитектура RCNN
Сеть Fast R-CNN принимает в качестве входных данных все изображение и набор предложений объектов. Сеть сначала обрабатывает все изображение с помощью нескольких слоев свертки (conv) и максимального пула, чтобы создать карту объектов conv.
Затем для каждого предлагаемого объекта слой объединения области интереса (RoI) извлекает вектор признаков фиксированной длины из карты признаков.
Каждый вектор признаков передается в последовательность полностью связанных (fc) слоев, которые в конечном итоге разветвляются на два родственных выходных слоя: один, который производит оценки вероятности softmax для K классов объектов плюс универсальный «фоновый» класс, и другой слой, который выводит четыре реальных -значные числа для каждого из K классов объектов. Каждый набор из 4 значений кодирует уточненные положения ограничительной рамки для одного из K классов.
Слой объединения областей интереса
Слой объединения RoI использует максимальное объединение для преобразования объектов внутри любой допустимой интересующей области в небольшую карту объектов с фиксированным пространственным размером H × W (например, 7 × 7), где H и W — гиперпараметры слоя, которые независимо от какой-либо конкретной RoI.
Каждая RoI определяется четырьмя кортежами (r, c, h, w), которые определяют ее верхний левый угол (r, c), а также ее высоту и ширину (h, w).
Максимальный пул RoI работает путем разделения окна RoI размером h × w на сетку H × W подокон приблизительного размера h/H × w/W, а затем максимального объединения значений в каждом подокне в соответствующую ячейку выходной сетки. . Объединение применяется независимо к каждому каналу карты объектов, как и при стандартном максимальном объединении.
Инициализация из предварительно обученных сетей
Когда предварительно обученная сеть инициализирует сеть Fast R-CNN, она претерпевает три преобразования:
- Последний уровень максимального пула заменяется уровнем пула RoI, который настраивается путем установки H и W для совместимости с первым полносвязным уровнем сети (например, H = W = 7 для VGG16).
- Последний полностью подключенный слой сети и softmax заменяются двумя родственными уровнями (полностью подключенный слой и softmax по K + 1 категориям и регрессорам ограничительной рамки для конкретных категорий).
- Сеть модифицируется для приема двух входных данных: списка изображений и списка областей интереса на этих изображениях.
Быстрее RCNN

Быстрее R-CNN: к обнаружению объектов в реальном времени с сетями региональных предложений
Faster R-CNN состоит из двух модулей.
Первый модуль — это глубокая полностью сверточная сеть, которая предлагает регионы, а второй модуль — это детектор Fast R-CNN, который использует предложенные регионы. Вся система представляет собой единую унифицированную сеть обнаружения объектов.
Региональная сеть предложений
Чтобы сгенерировать предложения по регионам, мы перемещаем небольшую сеть по сверточной карте объектов, выводимой последним общим сверточным слоем. Эта небольшая сеть принимает в качестве входных данных пространственное окно n × n входной сверточной карты признаков. Каждое скользящее окно сопоставляется с функцией более низкого измерения.
Эта функция передается в два одноуровневых полностью связанных слоя — слой регрессии блоков (reg) и слой классификации блоков (cls).
Якоря
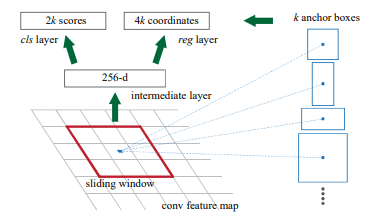
В каждом местоположении скользящего окна мы одновременно предсказываем несколько предложений по региону, где количество максимально возможных предложений для каждого местоположения обозначается как k. Таким образом, слой reg имеет 4k выходных данных, кодирующих координаты k ящиков, а слой cls выводит 2k оценок, которые оценивают вероятность объекта или не объекта для каждого предложения. K предложений параметризуются относительно k эталонных блоков, которые мы называем якорями. Якорь располагается по центру рассматриваемого скользящего окна и связан с масштабом и соотношением сторон (рис. 3, слева). По умолчанию мы используем 3 масштаба и 3 соотношения сторон, что дает k = 9 якорей в каждой скользящей позиции. Для сверточной карты признаков размером W × H (обычно ~ 2400) всего имеется W H k якорей.
Функция потерь
Для обучения RPN мы назначаем бинарную метку класса (является объектом или нет) каждому якорю. Мы присваиваем положительную метку двум видам якорей:
- Якорь/якоря с наивысшим значением Intersection-overUnion (IoU) перекрываются с полем достоверности.
- Якорь, который имеет перекрытие IoU выше 0,7 с любым полем достоверности.
Обратите внимание, что один блок истинности может назначать положительные метки нескольким якорям.
Общие функции для RPN и Fast R-CNN
В соответствии с экспериментами, упомянутыми в исходной статье, мы сначала обучаем RPN, а затем используем предложения для обучения Fast R-CNN. Сеть, настроенная Fast R-CNN, затем используется для инициализации RPN, и этот процесс повторяется.
Маска RCNN

Faster R-CNN состоит из двух этапов. На первом этапе, называемом сетью предложений регионов (RPN), предлагаются ограничивающие рамки объектов-кандидатов. Второй этап, который по сути является Fast R-CNN, извлекает функции с использованием RoIPool из каждого блока-кандидата и выполняет классификацию и регрессию ограничивающей рамки.
Mask R-CNN использует ту же двухэтапную процедуру с идентичным первым этапом (которым является RPN). На втором этапе, параллельно с прогнозированием класса и смещения поля, Mask R-CNN также выводит двоичную маску для каждой области интереса.
Формально во время обучения мы определяем многозадачную потерю для каждой выбранной области интереса как L = Lcls + Lbox + Lmask.
Ветвь маски имеет размерность Km² для каждой области интереса, которая кодирует K двоичных масок с разрешением m × m, по одной для каждого из K классов. К этому мы применяем сигмоид для каждого пикселя и определяем Lmask как среднюю бинарную кросс-энтропийную потерю. Для области интереса, связанной с классом достоверности k, Lmask определяется только для k-й маски (выходные данные других масок не влияют на потери).
Рекомендации
- Богатые иерархии функций для точного обнаружения объектов и семантической сегментации
- Быстрый R-CNN
- Быстрее R-CNN: к обнаружению объектов в реальном времени с сетями региональных предложений
- Маска R-CNN
Просмотреть все темы этой серии здесь