
Я думал об обратном распространении, и в традиционной нейронной сети кажется, что мы всегда линейно выполняем операции прямого и обратного распространения. (Как в соотношении 1: 1) Но я подумал про себя, что на самом деле нам не нужно этого делать. Итак, я хотел провести несколько экспериментов.
Случай a) Обратное распространение (без увеличения данных)
Случай b) Обратное распространение (увеличение данных)
Случай c) Недобросовестная обратная поддержка (со спины) (без увеличения данных)
Случай d) Недобросовестная задняя опора (сзади) (Увеличение данных)
Случай e) Недобросовестная задняя опора (спереди) (Нет увеличения данных)
Случай f) Недобросовестная задняя опора (спереди) (Увеличение данных)
Обратите внимание, что этот пост предназначен для развлечения и для выражения моего творчества. Следовательно, не ориентирован на производительность.
Сетевая архитектура / набор данных / типичное обратное распространение
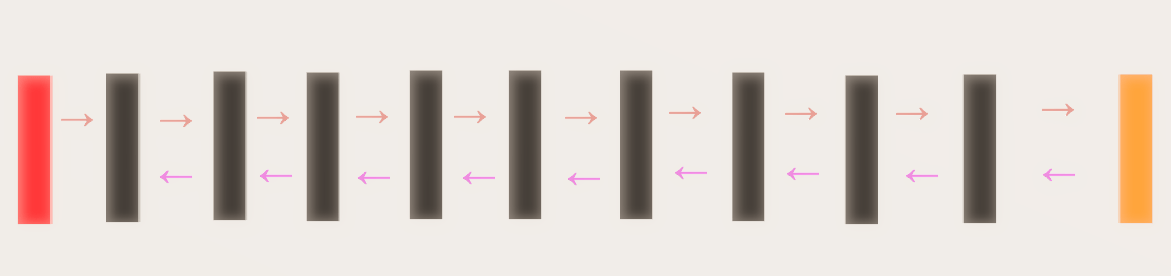
Красный квадрат → Пакет входного изображения
Черный квадрат → Слой свертки со средним объединением или без него
Оранжевый квадрат → слой Softmax для классификации
Оранжевая стрелка → Направление прямой связи
Пурпурная стрелка → Направление обратного распространения.
Как видно выше, мы собираемся использовать базовую сеть из моего старого поста All Convolutional Net, которая представляет собой всего лишь 9-уровневую сеть, состоящую только из операции свертки. Дополнительно мы собираемся использовать Набор данных CIFAR 10.
Несправедливое противодействие

Теперь, чтобы объяснить концепцию несправедливого обратного распространения, давайте сначала предположим, что мы только что закончили нашу операцию прямой связи (как показано выше). Глядя на розовую стрелку, мы уже можем сказать, что мы вернулись к 9-му слою.

Теперь вместо того, чтобы продолжать обратное распространение на восьмой уровень и так далее, мы можем снова выполнить операцию прямого распространения, чтобы получить еще один раунд классификации. (Но на этот раз 9-й слой уже обновил свои веса один раз.)

Мы можем повторить этот процесс еще раз, но на этот раз мы также обновим веса 8-го слоя.

И мы можем следовать этой концепции снова и снова. Пока мы не дойдем до 1-го слоя, мы закончим обратное распространение в целом. В заключение, мы несправедливы по отношению к начальным уровням нашей сети, поскольку последние части будут обновляться больше. Мы видим разницу и в формате GIF.

Наконец, мы можем взять понятие несправедливости по отношению к начальной части нашей сети и перевернуть ее, будучи несправедливым по отношению к последней части нашей сети. (Другими словами, обновление начальной части нашей сети больше, чем последних.)

Результаты: случай а) обратное распространение (без увеличения данных) (эпоха 50)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Как видно выше, точность сети для тестирования изображений начала стагнировать примерно на 83 процента. Однако здесь следует отметить тот факт, что сети потребовалось 13 эпох, чтобы точность тестирования изображений достигла более 80 процентов.

Окончательная точность составила 98 процентов на обучающих изображениях, а 83 процента на тестовых изображениях, что указывает на то, что сеть страдает от чрезмерной подгонки.


Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
И, как видно выше, весь диапазон веса увеличился с -0,1 / 0,1 до -0,5 / 0,5.
Результаты: случай b) обратное распространение (увеличение данных) (10 эпох)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Теперь, когда мы выполнили увеличение данных, мы можем четко наблюдать снижение точности обучающих изображений (поскольку в данных намного больше разброса).

Как видно выше, после 10 эпохи обучения сеть показала точность 79% (при тестировании изображений). К счастью, сеть не страдает от переоборудования.

Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
Как и в случае, когда мы не выполняли увеличение данных, диапазон весов увеличился.
Результаты: случай c) Недобросовестная поддержка (со спины) (без увеличения данных) (эпоха 10)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Сеть работала намного лучше по сравнению с той, которая была обучена нормальному (типичному) методу обратного распространения. Завершение обучения с точностью около 82 процентов на тестовых изображениях и 89 на обучающих изображениях. Это указывает на то, что все еще существует переоснащение, но не так много по сравнению со случаем а).

Довольно удивительно наблюдать тот факт, что несправедливое обратное распространение, похоже, имеет некоторый эффект регуляризации.

Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
Безусловно, самым интересным наблюдением была гистограмма весов. Как видно выше, когда мы фокусируем наше внимание на сгенерированной гистограмме последних слоев сети, мы можем заметить, что гистограмма смещена в одну сторону. (-0,5 в левом диапазоне, а 0,5 в правом.) Это указывает на то, что симметрия распределения несколько нарушена. То же самое касается гистограммы средних слоев.
Результаты: случай d) недобросовестная поддержка (со спины) (расширение данных) (эпоха 10)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Опять же, когда мы выполняем увеличение данных, мы можем наблюдать снижение точности обучающих изображений.

И при сравнении результатов из случая b) (опора Normal Back для 10 эпох) мы можем наблюдать тот факт, что точность обучающих изображений схожа друг с другом (49 процентов). Однако по какой-то причине сеть, обученная недобросовестной опорой, имела более высокую точность при тестировании изображений.

Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
В отличие от случая c) мы можем наблюдать некоторую симметрию распределения весов для этого случая.
Результаты: случай e) Недобросовестная обратная поддержка (спереди) (без увеличения данных) (эпоха 10)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Наконец, я хотел посмотреть, есть ли разница, когда мы несправедливо относимся к последней части нашей сети. И, судя по всему, лучше быть несправедливым по отношению к начальной части нашей сети, чем ко второй части.

Одна из причин, по которой я говорю это, - это окончательная точность тестовых изображений. Мы можем заметить, что точность обучающих изображений аналогична, но эта сеть имела более низкую точность при тестировании изображений.

Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
Интересно, что распределение весов похоже, независимо от того, несправедливо ли мы поступаем в начале или в последней части нашей сети.
Результаты: случай f) Недобросовестная обратная поддержка (спереди) (расширение данных) (эпоха 10)


Левое изображение → Точность / Стоимость тестовых изображений с течением времени
Правое изображение → Точность / Стоимость обучающих изображений с течением времени
Наконец, я выполнил увеличение данных во время обучения той же сети из случая e.

И, как видно выше, здесь также наблюдается отсутствие повышения точности.

Изображение слева → Гистограмма веса после тренировки
Изображение справа → Гистограмма веса до тренировки
Аналогичные результаты и для распределения весов. В обычной CNN мы знаем, что последние уровни захватывают функции более высокого уровня. Подозреваю, что сети лучше потренироваться? захват функций более высокого уровня.
Интерактивный код

Для Google Colab вам потребуется учетная запись Google для просмотра кодов, а также вы не можете запускать сценарии только для чтения в Google Colab, поэтому сделайте копию на своем игровом поле. Наконец, я никогда не буду спрашивать разрешения на доступ к вашим файлам на Google Диске, просто к сведению. Удачного кодирования! Также для наглядности я загрузил все журналы обучения на свой github.
Чтобы получить доступ к коду для случая a, нажмите здесь, для журналов нажмите здесь.
Чтобы получить доступ к коду для случая b, нажмите здесь , для журналов нажмите здесь .
Чтобы получить доступ к коду для случая c, нажмите здесь , для журналов нажмите здесь.
Чтобы получить доступ к коду для случая d, нажмите здесь , для журналов нажмите здесь .
Чтобы получить доступ к коду для случая e, пожалуйста, нажмите здесь , для журналов нажмите здесь.
Чтобы получить доступ к коду для случая f, нажмите здесь , для журналов нажмите здесь .
Заключительные слова
На самом деле у меня есть более глубокая причина, по которой я сделал этот пост в блоге, и скоро она будет раскрыта. Эта идея непропорционального обратного распространения действительно интересна мне.
Если будут обнаружены какие-либо ошибки, напишите мне на [email protected], если вы хотите увидеть список всех моих писем, пожалуйста, просмотрите мой сайт здесь.
Тем временем подпишитесь на меня в моем твиттере здесь и посетите мой веб-сайт или мой канал Youtube для получения дополнительной информации. Я также реализовал Широкие остаточные сети, пожалуйста, нажмите здесь, чтобы просмотреть пост блога t.
Ссылка
- tf.cond | TensorFlow. (2018). TensorFlow. Получено 17 июня 2018 г. с сайта https://www.tensorflow.org/api_docs/python/tf/cond.
- TensorFlow ?, Х. (2018). Как распечатать значение объекта Tensor в TensorFlow ?. Переполнение стека. Получено 17 июня 2018 г. из https://stackoverflow.com/questions/33633370/how-to-print-the-value-of-a-tensor-object-in-tensorflow
- Математика | TensorFlow. (2018). TensorFlow. Получено 17 июня 2018 г. с сайта https://www.tensorflow.org/api_guides/python/math_ops.
- tf.floormod | TensorFlow. (2018). TensorFlow. Получено 17 июня 2018 г. с сайта https://www.tensorflow.org/api_docs/python/tf/floormod.
- tf.cond | TensorFlow. (2018). TensorFlow. Получено 17 июня 2018 г. с сайта https://www.tensorflow.org/api_docs/python/tf/cond.
- Использование tf.Print () в TensorFlow - На пути к науке о данных. (2018). К науке о данных. Получено 17 июня 2018 г. с сайта https://towardsdatascience.com/using-tf-print-in-tensorflow-aa26e1cff11e.
- Tensorflow ?, Х. (2018). Как передать параметры в функции внутри tf.cond в Tensorflow ?. Переполнение стека. Получено 17 июня 2018 г. из https://stackoverflow.com/questions/38697045/how-to-pass-parmeters-to-functions-inside-tf-cond-in-tensorflow
- TensorFlow ?, Х. (2018). Как распечатать значение объекта Tensor в TensorFlow ?. Переполнение стека. Получено 17 июня 2018 г. из https://stackoverflow.com/questions/33633370/how-to-print-the-value-of-a-tensor-object-in-tensorflow
- Нормализованный Адам, сохраняющий направление, переход от Адама к SGD, и Нестеров Momentum Adam с…. (2018). К науке о данных. Получено 17 июня 2018 г. с сайта https://towardsdatascience.com/normalized-direction-preserving-adam-switching-from-adam-to-sgd-and-nesterov-momentum-adam-with-460be5ddf686.
- Google Colaboratory. (2018). Colab.research.google.com. Получено 17 июня 2018 г. с сайта https://colab.research.google.com/drive/1Okr4jfqBMoQ8q4ctZdJMp8jqeA4XDQbK.
- Обратное распространение | Блестящая вики по математике и науке. (2018). Brilliant.org. Получено 17 июня 2018 г. с сайта https://brilliant.org/wiki/backpropagation/.
- tf. while_loop, I. (2018). Возможно ли иметь несколько условий, определенных в tf. while_loop. Переполнение стека. Получено 17 июня 2018 г. с сайта https://stackoverflow.com/questions/45595419/is-it-possible-to-have-multiple-conditions-defined-in-tf- while-loop.
- Питон, Э. (2018). Выполнять оператор каждые N итераций в Python. Переполнение стека. Получено 17 июня 2018 г. с сайта https://stackoverflow.com/questions/5628055/execute-statement-every-n-iterations-in-python.
- Примеры: Основы - документация imgaug 0.2.5. (2018). Imgaug.readthedocs.io. Получено 18 июня 2018 г. с сайта http://imgaug.readthedocs.io/en/latest/source/examples_basics.html.
- Наборы данных CIFAR-10 и CIFAR-100. (2018). Cs.toronto.edu. Получено 19 июня 2018 г. с сайта https://www.cs.toronto.edu/~kriz/cifar.html.
- [ICLR 2015] Стремление к простоте: сверточная сеть с интерактивным кодом [Руководство…. (2018). К науке о данных. Получено 19 июня 2018 г. с сайта https://towardsdatascience.com/iclr-2015-striving-for-simplicity-the-all-convolutional-net-with-interactive-code-manual-b4976e206760.