Устранение ковариантного сдвига в глубоких сетях значительно улучшает обучение модели. Пакетная нормализованная сеть, когда она была представлена, превзошла лучшие опубликованные результаты в классификации ImageNet, превысив точность человеческих оценок.
Проблема. Системы обучения и их компоненты подвержены внутреннему ковариантному сдвигу. В контексте глубоких сетей это определяется как изменение распределения активации слоя из-за обновления параметров модели. Это проблема, потому что каждый слой должен адаптироваться к новому распределению своих входных данных. Решение этой проблемы положительно влияет на конвергенцию и производительность системы.
Подход. Нормализация выходных данных слоя перед применением нелинейности может изменить результирующее распределение так, чтобы оно было сосредоточено вокруг нуля с единичной дисперсией. Однако при наивной нормализации возникают две проблемы: параметры модели не сходятся, а вычислительные затраты резко возрастают. [1] Если среднее значение и дисперсия вычисляются за пределами шага градиентного спуска, параметр модели взрывается. Интуитивно нормализация отменит обновление параметра. Для решения этой проблемы градиент потерь по параметрам модели должен учитывать нормировку (и ее зависимость от параметров модели). [2] Поскольку нормализация зависит не только от данной обучающей выборки, но и от всех обучающих выборок, каждая из которых зависит от параметров всех предыдущих слоев, вычисление двух моментов становится дорогостоящим в вычислительном отношении. Авторы предлагают альтернативу, в которой нормализация является дифференцируемой и не требует анализа всей обучающей выборки после каждого обновления параметра. Каждая скалярная функция нормализуется независимо, а математическое ожидание и дисперсия аппроксимируются на основе мини-пакета. Кроме того, чтобы убедиться, что преобразование, вставленное в сеть, может представлять преобразование идентичности и, таким образом, сохранить пропускную способность сети, вводится пара обучаемых параметров γ и β для масштабирования и сдвига нормализованных значений. Это изученное аффинное преобразование позволяет сети легко восстановить первоначальную активацию, если это окажется оптимальным.

Следует отметить, что BN не обрабатывает активацию в каждом обучающем примере независимо. BN зависит от данного обучающего примера и других примеров, присутствующих в мини-пакете.
Забрать. Для любого слоя, состоящего из аффинного преобразования (FC, CNN), за которым следует поэлементная нелинейность (ReLu, сигмовидная), BN более эффективен перед нелинейностью. Действительно, результат аффинного преобразования, скорее всего, будет иметь неразреженное и гауссово распределение, которое при нормализации дает более стабильное распределение. Обратите внимание, что смещение любого такого слоя можно безопасно игнорировать благодаря введению параметра масштабирования β. Когда дело доходит до CNN, нормализация реализуется в соответствии со свойством свертки, поэтому γ и β изучаются для каждой карты функций, так что одно и то же аффинное преобразование применяется ко всем активациям в данной карте функций. BN очень помогает с исчезающим / взрывающимся градиентом, поскольку он позволяет входному сигналу более эффективно проходить через сеть. Шкала весов вызывает меньше беспокойства. Градиенты более стабильны, так как результирующий якобиан имеет сингулярные значения ближе к 1, что, как известно, полезно для обучения, поскольку сохраняет величину градиента во время обратного распространения. Наконец, сеть больше не выдает детерминированные значения для данной выборки. Вместо этого каждый образец отображается вместе с другими образцами в мини-пакете. Это упорядочивает сеть. В то время как обучение, систематическая ошибка и дисперсия могут быть оценены с использованием скользящего среднего для оценки его производительности на проверочном наборе. Во время вывода их можно оценить по всей обучающей выборке. Кроме того, вся нормализация реализована как одно линейное преобразование.
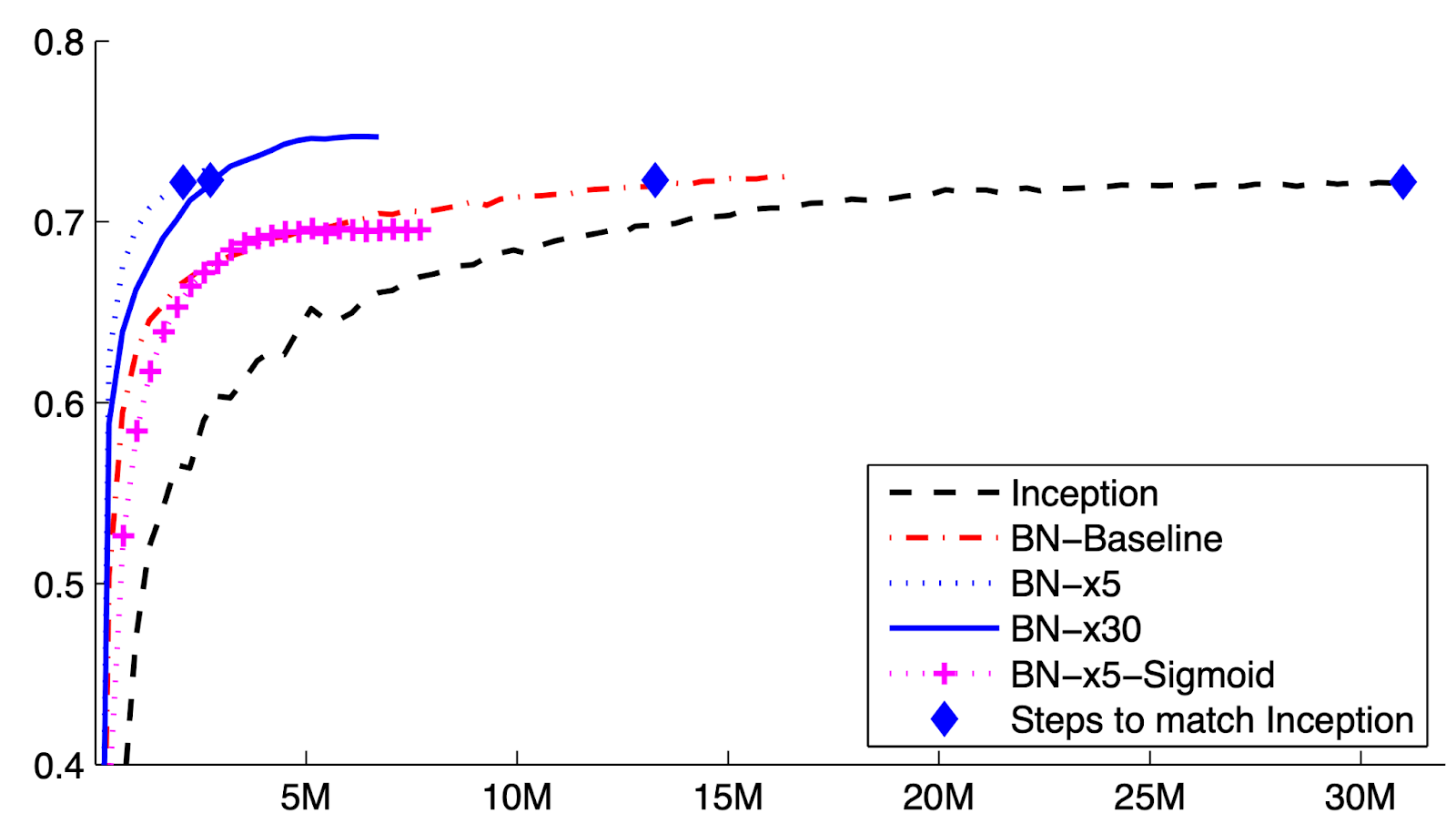
Результаты. BN — это дифференцируемое преобразование, которое вводит нормализованную активацию в сеть. Малые MLP, а также большие CNN, такие как Inception, выигрывают от нормализации. Полный потенциал методов раскрывается при выполнении следующих действий: увеличить скорость обучения, убрать отсев, уменьшить регуляризацию L2, ускорить затухание скорости обучения, убрать локальную нормализацию отклика, тщательно перетасовать и уменьшить фотометрические искажения. На приведенном выше рисунке видно, что BN-x30 достигает аналогичной точности (72%) за в 10 раз меньше шагов и в конечном итоге превосходит базовый уровень на несколько процентных пунктов. При использовании в ансамбле пакетной нормализованной модели они значительно превзошли современные модели.

Источник. Дополнительную информацию см. в [бумаге]. Все цифры взяты из бумаги.