Вдохновленное мозгом машинное обучение без присмотра через конкуренцию, сотрудничество и адаптацию
1. Введение
Самоорганизующаяся карта (SOM) — это неконтролируемый алгоритм машинного обучения, представленный Теуво Кохоненом в 1980-х годах [1]. Как следует из названия, карта самоорганизуется без каких-либо инструкций со стороны других. Это модель, вдохновленная мозгом. Другая область коры головного мозга в нашем мозгу отвечает за определенные виды деятельности. Сенсорный ввод, такой как зрение, слух, обоняние и вкус, сопоставляется с нейронами соответствующей области коры через синапсы самоорганизующимся образом. Также известно, что нейроны с одинаковым выходом находятся рядом. SOM обучается через конкурентную нейронную сеть, однослойную сеть прямой связи, которая напоминает эти мозговые механизмы.
Алгоритм SOM относительно прост, но на первый взгляд может возникнуть некоторая путаница и трудности с пониманием того, как его применять на практике. Возможно, это связано с тем, что SOM можно понимать с разных точек зрения. Это похоже на анализ основных компонентов (PCA) для уменьшения размерности и визуализации. SOM также можно рассматривать как тип многообразного обучения, который обрабатывает нелинейное уменьшение размерности. SOM также используется в интеллектуальном анализе данных из-за его свойства векторного квантования [2]. Поезд может представлять многомерные наблюдаемые данные в скрытом пространстве более низкого измерения, как правило, в двумерной квадратной сетке, сохраняя при этом топологию исходного входного пространства. Но карту также можно использовать для проецирования новых точек данных и просмотра того, какой кластер принадлежит карте.
В этой статье объясняется базовая архитектура самоорганизующейся карты и ее алгоритм с упором на ее самоорганизующийся аспект. Мы кодируем SOM для решения проблемы кластеризации, используя набор данных, доступный в репозитории машинного обучения UCI [3] на Python. Затем мы увидим, как карта организует себя во время онлайн (последовательного) обучения. Наконец, мы оцениваем обученный SOM и обсуждаем его преимущества и ограничения. SOM — не самый популярный метод машинного обучения, и его нечасто можно встретить за пределами академической литературы; однако это не означает, что SOM не является эффективным инструментом для решения всех проблем. Обучить модель относительно легко, а визуализацию обученной модели можно использовать для эффективного объяснения нетехническим аудиторам. Мы увидим, что проблемы, с которыми сталкивается алгоритм, часто встречаются и среди других неконтролируемых методов.
2. Архитектура и алгоритм обучения
Нейронная сеть самоорганизующейся карты имеет один входной слой и один выходной слой. Второй слой обычно состоит из двумерной решетки из m x n нейронов. Каждый нейрон слоя карты тесно связан со всеми нейронами входного слоя, имеющими разные значения веса.
При конкурентном обучении нейроны в выходном слое конкурируют между собой за активацию. Победивший нейрон соревнования — единственный, который может быть запущен; следовательно, он называется нейроном «победитель получает все». В SOM конкурентный процесс заключается в поиске нейрона, наиболее похожего на входной паттерн; победитель называется Best Matching Unit (BMU).
Сходство как критерий выигрыша можно измерить несколькими способами. Чаще всего используется евклидово расстояние. Нейрон с кратчайшим расстоянием от входного сигнала становится BMU.
В SOM обучение предназначено не только для победителя, но и для нейронов, находящихся физически рядом с ним на карте. BMU разделяет привилегию со своими соседями учиться вместе. Определение окрестности определяется проектировщиком сети, а оптимальная близость зависит от других гиперпараметров. Если диапазон окрестностей слишком мал, обученная модель будет страдать от переобучения, и есть риск наличия некоторых мертвых нейронов, которые никогда не смогут измениться.
На этапе адаптации BMU и его соседи корректируют свой вес. Эффект обучения заключается в перемещении веса победивших и соседних нейронов ближе к входному шаблону. Например, если входной сигнал синего цвета, а нейрон BMU светло-голубого цвета, победитель становится несколько более синим, чем светло-голубым. Если соседи желтые, к их текущему цвету добавляется немного синевы.
Алгоритм обучения самоорганизующейся карты (онлайн-обучение) можно описать следующими 4 шагами.
1. Initialisation Weights of neurons in the map layer are initialised. 2. Competitive process Select one input sample and search the best matching unit among all neurons in n x m grid using distance measures. 3. Cooperative process Find the proximity neurons of BMU by neighbourhood function. 4. Adaptation process Update the BMU and neighbours' weights by shifting the values towards the input pattern. If the maximum count of training iteration is reached, exit. If not, increment the iteration count by 1 and repeat the process from 2.
3. Реализация
В этой статье SOM обучается с использованием набора данных для аутентификации банкнот, доступного на веб-сайте UCI ML Repository. Файл данных содержит 1372 строки, каждая с 4 функциями и 1 меткой. Все 4 функции являются числовыми значениями без нуля. Метка представляет собой двоичное целочисленное значение.
Во-первых, мы случайным образом разделяем данные на данные обучения и тестирования. Мы используем все 4 функции для обучения SOM с использованием алгоритма онлайн-обучения. Затем мы оцениваем обученный SOM, визуализируя карту, используя метку обучающих данных. Наконец, мы можем использовать тестовые данные для предсказания метки с помощью обученной карты.
Таким образом, мы можем продемонстрировать, что SOM, обученный неконтролируемым образом, может применяться для классификации с использованием размеченного набора данных.
Код Python
1. Импортировать библиотеки
2. Импорт набора данных
Файл CSV загружается с веб-сайта и сохраняется в каталоге. Мы используем первые 4 столбца для x и последний столбец для y.
3. Разделение данных обучения и тестирования
Данные разделены для обучения и тестирования в пропорции 0,8:0,2. Мы видим 1097 и 275 наблюдений соответственно.
4. Вспомогательные функции
minmax_scaler используется для нормализации входных данных между 0 и 1. Поскольку алгоритм вычисляет расстояние, мы должны масштабировать значения каждой функции в одном и том же диапазоне, чтобы ни одна из них не оказывала большего влияния на расчет расстояния, чем другие функции.
e_distance вычисляет евклидово расстояние между двумя точками. m_distance используется для получения манхэттенского расстояния между двумя точками сетки. В нашем примере евклидово расстояние используется для поиска нейрона-победителя, а манхэттенское расстояние используется для ограничения диапазона окрестности. Это упрощает вычисления, применяя прямоугольную функцию соседства, где нейроны, расположенные в пределах определенного манхэттенского расстояния от топологического местоположения BMU, активируются на одном уровне.
winning_neuron ищет в BMU образец данных t. Рассчитывается расстояние между входным сигналом и каждым нейроном в слое карты, и возвращается индекс строки и столбца сетки нейрона с кратчайшим расстоянием.
decay возвращает скорость обучения и диапазон окрестности после применения линейного затухания с использованием текущего шага обучения, максимального количества шагов обучения и максимального диапазона окрестности и скорости обучения.


5. Гиперпараметры
Гиперпараметры — это необучаемые параметры, которые необходимо выбрать перед обучением алгоритмов. Это количество нейронов, размер сетки SOM, количество шагов обучения, скорость обучения и диапазон окрестностей от BMU.
В этом примере мы устанавливаем меньшие числа для сетки (10 * 10), но есть эвристика для выбора гиперпараметров. Мы могли бы использовать формулу [5 * sqrt (количество обучающих выборок)] [4] для выбора количества нейронов. У нас есть 1097 обучающих выборок, поэтому в сетке можно создать 5 * sqrt (1097) = 165,60 нейронов. Поскольку у нас есть двумерная квадратная решетка, квадратный корень из числа предполагает, сколько нейронов у нас может быть для каждого измерения. Потолок sqrt(165.40) = 13, поэтому размеры карты могут быть 13*13.
Количество шагов обучения может потребовать не менее (500 *n строк * m столбцов) для сходимости. Мы можем установить количество шагов равным 500 * 13 * 13 = 84 500 для начала. Скорость обучения и диапазоны окрестности могут быть установлены большими числами и постепенно уменьшаться. Для улучшения рекомендуется поэкспериментировать с различными наборами гиперпараметров.
Начальное значение для максимального диапазона окрестности и скорости обучения может быть установлено большим числом. Если скорости слишком малы, это может привести к переоснащению и необходимости большего количества шагов обучения для обучения.
6. Обучение
После применения нормализации входных данных мы инициализируем карту случайными значениями от 0 до 1 для каждого нейрона в решетке. Затем скорость обучения и соседний диапазон вычисляются с использованием функции затухания. Выборочное входное наблюдение случайным образом выбирается из обучающих данных, и выполняется поиск наиболее подходящей единицы. На основе критерия манхэттенского расстояния для обучения выбираются соседи, включая победителя, и корректируются веса.
7. Показывать метки обученному SOM
На предыдущем шаге мы завершили обучение. Поскольку это неконтролируемое обучение, но для нашей задачи есть данные меток, теперь мы можем спроецировать метки на карту. Этот шаг состоит из двух частей. Сначала собираются метки для каждого нейрона. Во-вторых, одна метка проецируется на каждый нейрон для построения карты меток.
Мы создаем ту же сетку, что и SOM. Для каждых обучающих данных мы ищем нейрон-победитель и добавляем метку наблюдения в список для каждого BMU.
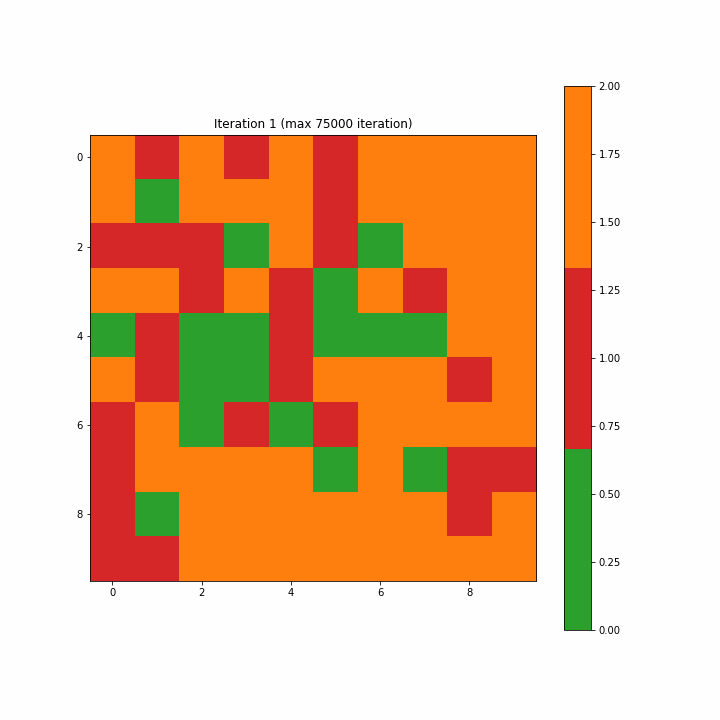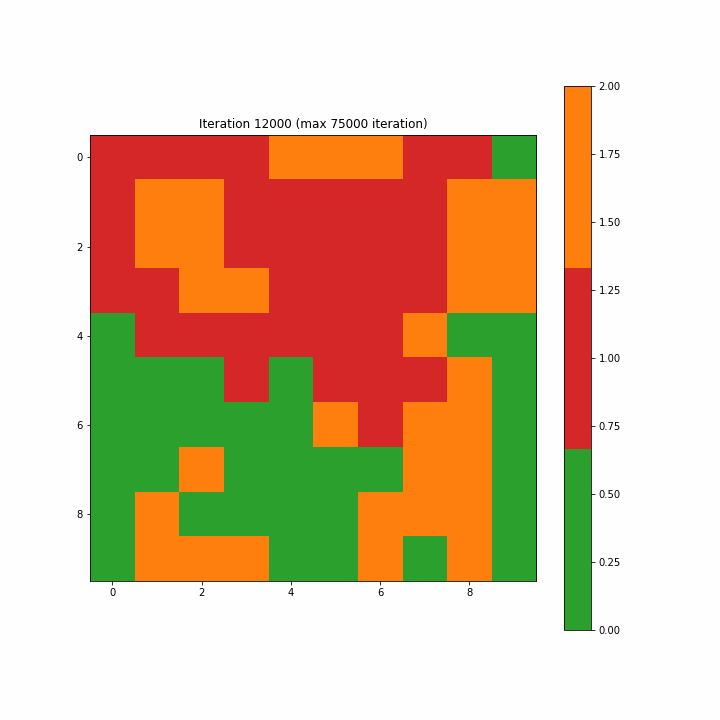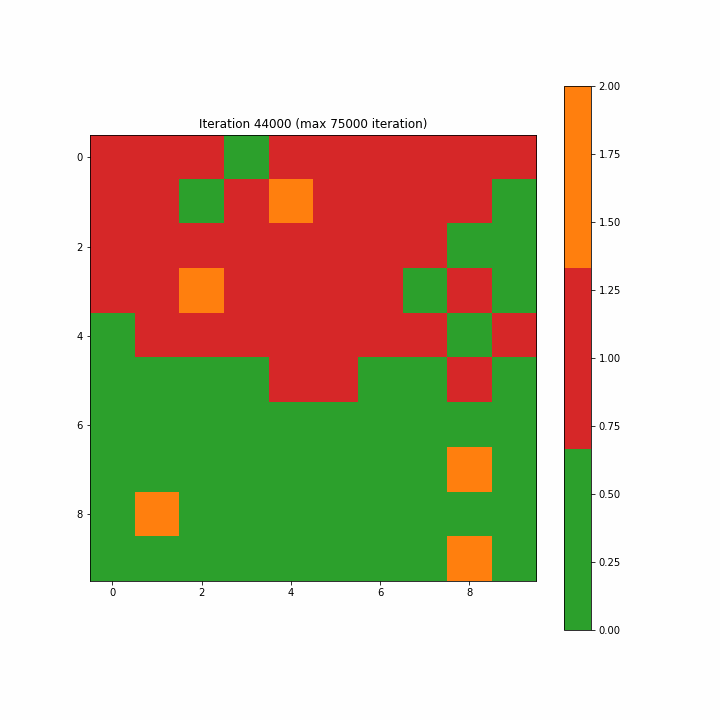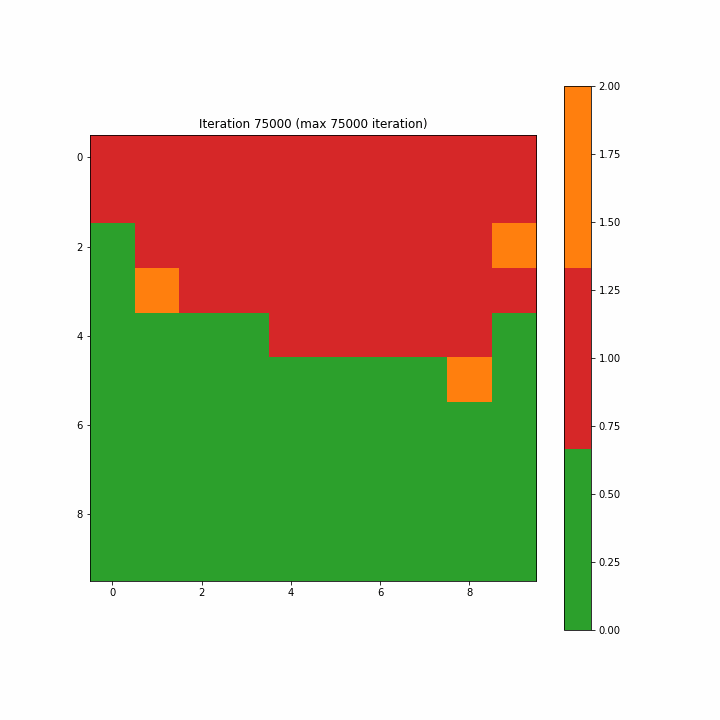
Чтобы построить карту меток, мы назначаем одну метку каждому нейрону на карте большинством голосов. В случае нейрона, где BMU не выбран, мы присвоили значение класса 2 как неидентифицируемое. На рисунках 3–7–1 и 3–7–2 показаны созданные карты меток для 1-й и последней итераций. Вначале многие нейроны не равны ни 0, ни 1, и метки классов кажутся разбросанными случайным образом; последняя итерация ясно показывает разделение областей между классами 0 и 1, хотя мы видим пару ячеек, которые не принадлежат ни к одному из классов на последней итерации.


Рисунок 3–7–3 представляет собой анимированный gif, показывающий эволюцию SOM от 1-го шага до максимального 75 000-го шага. Мы видим, что карта четко организована.
Чтобы создать анимированный gif, вы можете обратиться к моей предыдущей статье об оптимизации роя частиц для фрагмента кода Python с использованием библиотеки Matplotlib.
8. Прогнозирование меток набора тестов
Наконец, мы можем провести бинарную классификацию тестовых данных, используя обученную карту. Мы нормализуем тестовые данные x и ищем MBU для каждого наблюдения t. Возвращается метка, связанная с нейроном. Результат точности был возвращен, и наш пример показал очень хорошее число, как показано на рис. 3-8.

4. Оценка
В предыдущем разделе показано, как неконтролируемая самоорганизующаяся карта может быть реализована для задачи классификации. Мы обучили карту на наборе данных без меток и подтвердили результат обучения, спроецировав метки на карту. Как и ожидалось, мы могли наблюдать, что для каждого класса есть четкие области с нейронами, имеющими сходные признаки, расположенными ближе друг к другу. Наконец, мы протестировали карту с непредвиденным набором тестовых данных и измерили точность прогноза.
Данные, которые мы использовали для примера, представляют собой небольшой и чистый набор данных с ограниченным количеством наблюдений и признаков. В реальном сценарии проблемы, с которыми сталкиваются специалисты по данным, гораздо более масштабны, и помеченный набор данных не полностью доступен. Даже если они доступны, их качество может быть ненадежным. Например, при обнаружении злонамеренных транзакций для банка может быть разумно не ожидать, что все транзакции будут проверены на наличие положительных случаев; возможно, в реальном наборе данных отмечены лишь несколько положительных случаев.
У нас есть некоторые проблемы при применении самоорганизующейся карты к реальному сценарию. Во-первых, если у нас нет размеченного набора данных, мы не можем измерить потери. У нас нет возможности проверить, насколько надежна обученная карта. Качество карты во многом зависит от характеристик самих данных. Предварительная обработка данных путем нормализации важна для алгоритма, основанного на расстоянии. Предварительный анализ набора данных также важен для понимания распределения точек данных. Специально для данных высокой размерности, где визуализация невозможна, мы можем использовать другие методы уменьшения размерности, такие как PCA и разложение по сингулярным значениям (SVD).
Кроме того, обучение может не увенчаться успехом, если форма топологической карты не имеет отношения к распределению точек данных в скрытом пространстве. Хотя в нашем примере мы использовали квадратную сетку, мы должны тщательно продумать построение карты. Один из рекомендуемых подходов заключается в использовании отношения объясненных отклонений от первых двух основных компонентов PCA. Однако, если позволяет время, стоит попробовать разные гиперпараметры для тонкой токарной обработки.
С точки зрения вычислительной стоимости алгоритма сложность времени обучения зависит от количества итераций, количества признаков и количества нейронов. Первоначально SOM предназначен для последовательного обучения, но есть случаи, когда предпочтительным является метод пакетного обучения. По мере увеличения размера данных для больших данных может потребоваться исследование более эффективных алгоритмов обучения. В нашем примере мы использовали прямоугольную функцию соседства, называемую для упрощения пузырьком. Для итераций обучения мы могли бы отслеживать формирование самоорганизующихся карт и изучать, как карта изучается во время цикла. Сокращение количества шагов обучения напрямую влияет на количество вычислений.
Наконец, в этой статье не рассматривается алгоритм пакетного обучения. Если для задачи имеются конечные данные, рекомендуется использовать пакетный алгоритм. Фактически, Кохонен утверждает, что пакетный алгоритм эффективен и рекомендуется для практических приложений [5]. Мы хотели бы завершить эту статью, оставив ссылку на статью Кохонена «Основы самоорганизующейся карты» для дальнейшего чтения.
Ссылка
[1] Т. Кохонен, «Самоорганизованное формирование топологически правильных карт признаков», Биологическая кибернетика, т. 1, с. 43, нет. 1, стр. 59–69, 1982, doi: 10.1007/bf00337288.
[2] де Бодт, Э., Коттрелл, М., Летреми, П. и Верлейсен, М., 2004. Об использовании самоорганизующихся карт для ускорения векторного квантования. Нейрокомпьютинг, 56, стр. 187–203.
[3] Дуа, Д. и Графф, К. (2019). Репозиторий машинного обучения UCI [http://archive.ics.uci.edu/ml]. Ирвин, Калифорния: Калифорнийский университет, Школа информационных и компьютерных наук.
[4] Дж. Тиан, М. Х. Азарян и М. Пехт, «Обнаружение аномалий с использованием алгоритма K-ближайших соседей на основе самоорганизующихся карт», PHME_CONF, том. 2, нет. 1 июля 2014 г.
[5] Т. Кохонен, «Основы самоорганизующейся карты», Neural Networks, vol. 37, стр. 52–65, январь 2013 г., doi: 10.1016/j.neunet.2012.09.018.