
Прогнозирование данных временных рядов может быть трудным. Определенно сложно предсказать многомерные данные временных рядов. Прогнозирование многомерных данных временных рядов, где разные переменные являются разными типами данных, представляет собой уникальную и интересную задачу, которую я и мой партнер недавно предприняли с отличными результатами.
Многовариантные временные ряды отчасти усложняются тем, что не существует окончательного лучшего способа их решения. Например, для такой задачи, как классификация изображений, все согласны с тем, что некоторая версия сверточных нейронных сетей будет лучшим инструментом для этой работы. Для данных временных рядов существуют различные авторегрессивные модели (арима, сарима и т. Д.) И существуют глубокие нейронные подходы (RNN, LSTM, Rocket и т. Д.), Но у каждого метода есть свои плюсы и минусы, поэтому четкой оптимальной стратегии пока не существует. Одна из самых многообещающих моделей для прогнозирования временных рядов - это преобразователь. Изначально трансформеры были разработаны для НЛП и с момента их создания в значительной степени взяли на себя всю языковую обработку и создали несколько невероятных крупномасштабных моделей (например, BERT, GPT-2/3). После некоторой работы ту же самую архитектуру преобразователя можно применить к временным рядам.

Когда прогнозирование временного ряда изображается, как правило, его приложения находятся в прогнозировании запасов, прогнозировании погоды, логистическом анализе и т. Д. Вас простят за то, что вы подумали, что рисунок кошки следует рассматривать как изображение, а не как временной ряд. Однако рисунок создается человеком, перемещающим перо в определенной последовательности на странице. Фактическое время не имеет такого значения, как тот факт, что рисунок представляет собой упорядоченный набор точек, на самом деле, прежде чем мы пойдем дальше, нам нужно будет внимательнее взглянуть на данные, с которыми мы работаем.
Данные
Несколько лет назад Google выпустил забавную маленькую игру под названием Quick, Draw! Пользователь рисует простое изображение, а серверная нейронная сеть пытается угадать, что это правильно. Затем рисунки помогают ИИ лучше учиться и делать более точные предположения для последующих пользователей. Это интересный способ провести пару минут. Но это стало еще интереснее, когда его не было на пару лет; были выпущены полные наборы данных чертежей, кроме того, Google выпустил то, что они назвали Sketch RNN. Архитектура повторяющейся нейронной сети, которая может анализировать рисунок для создания новых случайно сгенерированных рисунков и даже предсказывать, как рисунки могут быть завершены, если будет дан частичный рисунок. Это дало очень хорошие результаты и имеет очень интересную архитектуру автокодировщика, но если вы знаете о RNN, у них есть много ограничений и проблем. Проблемы, которых нет у трансформаторов. Итак, давайте взглянем на данные и посмотрим, можем ли мы использовать трансформаторы (если вы читаете его, то уже знаете, что мы можем и использовали).
Наборы данных разделены по классам для серверной части классификатора, которую использует Google, например, кошка, автобус, бутылка вина или Мона Лиза. Каждый из этих наборов содержит около 70 000 уникальных рисунков, выполненных пользователями Quick, Draw. В отличие от традиционного файла изображения, каждый рисунок сохраняется в виде упорядоченного списка штрихов, используемых для создания этого изображения, каждый штрих состоит из координатных точек вдоль линии штриха пера. Чтобы эти данные были в наилучшей форме, а не в абсолютных координатах, лучше использовать смещения от последней точки, и вместо разделения штрихов новой записью в списке они определяют переменную для каждой точки смещения, называемую «состояние пера». Состояния пера - это набор из трех двоичных переменных (на самом деле одна трехзначная, поскольку они зависят друг от друга). [1, 0, 0], если перо опущено и рисует. [0, 1, 0], если перо вверх, т. Е. Один штрих пера закончился, а значение смещения представляет собой расстояние до того, когда начнется следующий штрих пера. [0, 0, 1], так как после завершения всего рисования рисование больше не будет происходить. Таким образом, в целом каждая точка данных имеет вид [x, y, p1, p2, p3], где x и y - смещения расстояния от последней точки в каждом измерении, а P (p1, p2, p3) - состояние пера. в таком случае.
Например, первые три точки рисунка кошки в наборе были: [[-18. 5. 1. 0. 0.], [-15. 16. 1. 0. 0.], [-7. 13. 1. 0. 0.]…] Рисунок перемещается на 18 пикселей влево и на 5 вверх, затем на 15 влево и 16 вверх, затем на 7 влево и 13 вверх. Перо все время опущено, поэтому рисунок связан между каждой из этих точек.
Это означает, что каждый рисунок представляет собой упорядоченный список из 5 измерений. Поскольку он упорядочен таким же образом, как пользователь рисовал точки, его можно рассматривать как последовательность последовательностей в 5 измерениях, и если мы можем учесть более высокую размерность, мы можем использовать преобразователи для прогнозирования этих последовательностей, тем самым прогнозируя остальную часть рисования. Но заставить его работать с трансформаторами - трудная часть.
Трансформеры и наша архитектура
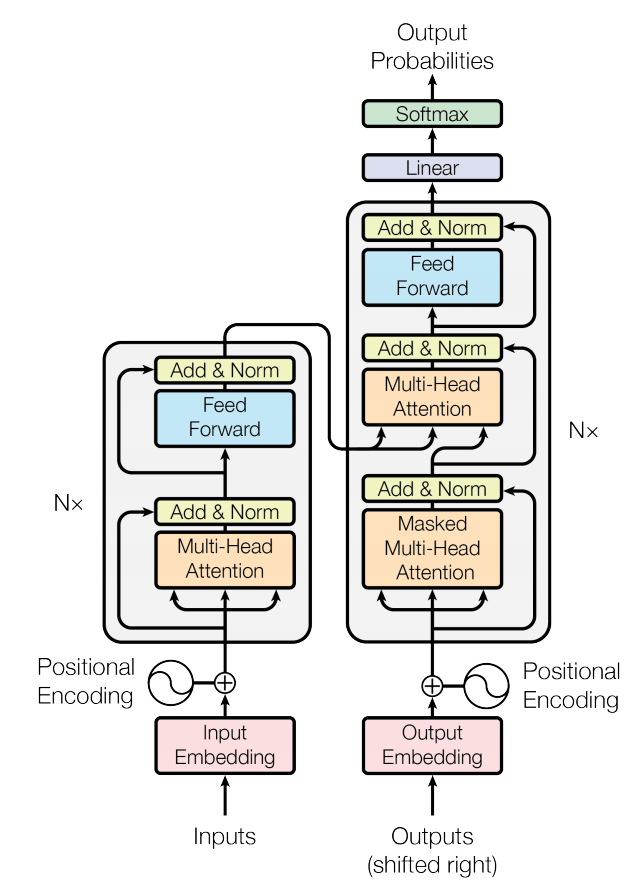
Я не буду вдаваться в подробности самих трансформаторов, потому что есть много замечательных ресурсов, на которых можно поучиться, если вы новичок в трансформаторах. Идея трансформаторов заключается в использовании так называемых блоков самовнимания для изучения взаимосвязи между различными точками последовательности. Кроме того, он полагается на позиционное кодирование, чтобы модель могла точно узнать, где в последовательности находится точка. Трансформаторы принимают два входа: саму входную последовательность (для языковой модели может быть английское предложение) и частичную выходную последовательность, которую они уже создали (однако большая часть английского предложения уже переведена на другой язык). Это означает, что трансформаторы используют тот факт, что знание частичного выхода может помочь в вашем последующем прогнозе. Например, легче перевести английское предложение на испанский, если вы уже знаете первое слово перевода предложения на испанский.
Для наших данных ввод и вывод имеют одну и ту же форму, мы хотим предсказать более поздние точки на чертеже, а не переводить эти точки в другую форму. Поскольку вход и выход одинаковы, нам не нужны и кодер, и декодер половины преобразователя, мы можем использовать только декодер, поскольку именно там находится блок замаскированного внимания, который нам нужен для прогнозирования следующих точек. (см. диаграмму выше для кодировщика и декодера). Обычный декодер имеет два сгруппированных набора блоков внимания, первый / нижний набор для замаскированного внимания и второй / более высокий набор для внимания между выходом замаскированного внимания и выходом блока кодера. Поскольку у нас не будет блока кодировщика, нам не понадобится второй / высший набор блоков внимания. Эта полностью декодирующая архитектура аналогична подходу, используемому в известных моделях GPT-2/3.
Изначально трансформеры были разработаны для НЛП, что означает, что они воспринимали слово в одном измерении. Хотя на практике требуется два измерения, потому что вложения слов обычно выполняются с помощью некоторой версии горячих векторов, два измерения все же меньше пяти, которые у нас есть для наших эскизных чертежей. Это следующее изменение, которое мы внесли в нашу модель, заменив слой внедрения на слой с линейной проекцией. Это проецирует данные в нужное пространство для перехода на следующие слои модели.
Это касается ввода, но нам также необходимо изменить вывод модели. Исходный преобразователь использует слой активации softmax, потому что для NLP он предсказывает следующее слово в последовательности. Для нашего у нас есть смесь точек смещения и меток пера. Естественный способ сделать это - иметь двойной выход, где точки смещения представляют собой просто линейный слой активации, а состояние пера - это слой активации softmax, а затем объединить эти два выхода. Если бы мы сделали это, только с этими изменениями вы могли бы дать модели входные данные и обучить их на основе этого, но результаты оставляют желать лучшего.
Проблема
Если мы это сделаем, нам придется создать собственную функцию потерь, в которой смещения используют среднеквадратичную ошибку, а состояние пера - перекрестную энтропию. Это очень логичный подход, потому что смещение - это мера расстояния, а состояние пера можно рассматривать как маркировку. Создание пользовательских функций потерь в Tensorflow / Keras не является сложной задачей, и комбинировать различные типы потерь таким образом относительно просто. Проблема возникает при обучении и использовании. Когда мы обучаем модель с помощью этой настраиваемой функции потерь, у нее будут проблемы с изучением состояния пера и смещения. Мы могли бы получить достойные результаты со смещением, например, он мог бы в конечном итоге выучить основную форму рисунка, как кошка, но тогда он не смог бы справиться с состоянием пера и обычно просто никогда не поднимал бы перо. Если мы настроим функцию потерь и / или гиперпараметры, чтобы узнать состояние пера, он может изменить состояние пера (то есть поднять перо), но тогда он не сможет изучить формы на рисунке. Чтобы решить эту проблему, нам пришлось реализовать разветвленную модель.
В этом контексте разветвленная модель означает, что мы разделили модель на полпути и получили две отдельные функции потерь, а не одну объединенную. Наша исходная модель будет использовать 6 стеков блоков декодера друг над другом. Для разветвленной реализации мы используем 4 наложенных друг на друга, затем модель «разветвляется» и разделяется на две части. Каждая из ветвей принимает один и тот же входной сигнал, который является выходом четырех предыдущих блоков декодера, а затем имеет еще 2 блока декодера и выход, соответствующий тому, какой это блок, один для смещений и один для состояния пера. Таким образом, всего это 8 блоков декодера, только два больше, но эта новая модель означает, что некоторые из блоков декодера предназначены только для изучения состояния пера, некоторые просто для смещения, а некоторые для обоих. При работе с такой разветвленной моделью функция потерь на самом деле представляет собой две функции потерь. Поскольку мы уменьшаем две отдельные потери, возможно, что уменьшение одного действительно может увеличить другое, но поскольку состояние пера и значение смещения должны быть коррелированы в целом, уменьшение одного также уменьшит другое.
Результаты

На практике эти изменения были именно тем, что требовалось для получения отличных результатов. Блоки декодера, выделенные для каждой конкретной части вывода, означают, что модель может более эффективно изучать шаблоны для этих переменных и может гораздо более надежно прогнозировать как смещение, так и состояние пера. Прогноз в этом контексте означает предсказание следующей точки рисунка, то есть, если мы начнем с очень малого, возможно, просто круга или первых 5–10 точек, модель должна быть в состоянии предсказать, как может выглядеть остальная часть рисунка. При небольшом обучении предсказания начинают точно напоминать кошек, при большем обучении (30 или более эпох) он начинает очень надежно рисовать узнаваемый образ кошки с помощью простого ввода.
Эти же методы можно применить к любым другим временным рядам и, вероятно, дать хорошие результаты при наличии правильных данных и гиперпараметров. В частности, аспект ветвления модели, вероятно, можно будет применить к широкому спектру наборов данных. Трансформеры произвели революцию в обработке естественного языка благодаря своей способности быстрее и точнее изучать и синтезировать данные о внимании. В будущем я полностью ожидаю, что трансформеры захватят многие области машинного обучения по тем же причинам.
Код и ссылки
мой сайт: https://mag389.github.io/
Наш код: https://github.com/95ktsmith/Sketch-Transformer
Быстро, рисовать данные: https://quickdraw.withgoogle.com/data
Sketch-rnn: https://arxiv.org/pdf/1704.03477.pdf
Оригинал статьи-трансформера: https://arxiv.org/abs/1706.03762