
Объяснение машины опорных векторов
Итак, вы, должно быть, уже прошли через логистическую регрессию. Предположение, которое мы делаем в логистической регрессии, заключается в том, что данные должны быть линейно разделяемыми. Давайте поговорим о другом простом и элегантном алгоритме, SVM (Support Vector Machine). SVM можно использовать как в случае регрессии, так и в случае классификации.
Что такое машина опорных векторов?
Машина опорных векторов в основном используется в задачах классификации. Цель / ключевая идея классификатора SVM - найти гиперплоскость, которая четко классифицирует все точки в n-мерном пространстве (n соответствует количеству функций). Давайте посмотрим на геометрическую интуицию SVM.
Геометрическая интуиция
Здесь мы будем рассматривать проблему классификации на два класса, в которой нам нужно отделить положительные моменты от отрицательных.

Таким образом, интуитивно мы должны найти гиперплоскость π такую, что π + пересекает ближайшую положительную точку, а π- пересекает ближайшую отрицательную точку (π + и π - параллельны π) таким образом, чтобы расстояние между π + и π- было максимальным. Когда это расстояние максимизировано, положительные точки и отрицательные точки находятся вдали от вашей реальной разделяющей гиперплоскости π. SVM попытайтесь найти гиперплоскость, которая максимизирует маржу (по мере увеличения маржи наша точность обобщения также увеличивается)
Входные векторы (точки), которые только касаются границы поля, называются опорными векторами.
Что такое опорные векторы?
• Опорные векторы - это элементы обучающего набора, которые при удалении изменили бы положение разделяющей гиперплоскости.

Таким образом, учитывая новую точку запроса во время выполнения, мы будем использовать нашу гиперплоскость π (нашу максимизирующую маржу), чтобы классифицировать точку как положительную или отрицательную. Как видно на рисунке ниже.

Математическая формулировка SVM

В SVM мы заботимся о марже. Используя простую координатную геометрию, мы можем доказать, что Margin: d = 2 / || w ||

Вот как выглядит классификатор SVM для линейных разделяемых данных в 2D:

Изучение SVM можно сформулировать как задачу оптимизации, в которой мы должны максимизировать запас, чтобы получить лучшую гиперплоскость:

Или, что то же самое

Эта формулировка SVM известна как Hard-SVM. Но это можно применить только в том случае, если наши данные линейно разделимы, поскольку эта формулировка не учитывает какие-либо неправильно классифицированные точки, что означает, что эта формулировка не будет работать, если ваши данные не являются линейно разделимыми.
Давайте посмотрим на другую формулировку SVM, которая может обрабатывать почти линейно разделяемые данные, также известную как Soft-Margin SVM.
Soft-Margin SVM
Здесь мы видим, что это почти линейно разделяемые данные с несколькими неверно классифицированными точками.

Выше я показал расстояние трех засекреченных точек, две из которых были классифицированы нами неправильно. Итак, давайте представим новую переменную «резерв» ξ i.

Для каждой точки xi у нас есть переменная ξ i такая, что:

ξ i всегда ≥ 0
Здесь задача оптимизации, которую нам необходимо сформулировать, выглядит следующим образом:

C - здесь гиперпараметр (параметр регуляризации). По мере увеличения C модель имеет тенденцию к переоснащению и по мере уменьшения C модель имеет тенденцию к недостаточному соответствию. Мы можем найти наилучшее значение C с помощью перекрестной проверки
Примечание. ξ i = 1- yi (w.xi + b), что может интерпретироваться как потеря на шарнире.
Потеря на шарнире приблизительно равна (0–1) потере. Зеленая линия на рисунке ниже представляет потерю на шарнире.
Для yi (w.xi + b) ≥ 1; потеря петли = 0
и
для yi (w.xi + b) ‹1; потеря петли = 1-yi (w.xi + b)
В качестве альтернативы потерю шарнира можно записать как max (0, 1-yi (w.xi + b))

SVM изучает линейный классификатор:

формулируется как решение задачи оптимизации по w:

Здесь ξ I = max (0, 1-yif (xi)) (потеря шарнира)
Это задача квадратичной оптимизации, известная как Первичная проблема. Soft Margin SVM также известен как Primal Of SVM.
Давайте посмотрим на еще одну элегантную форму SVM, которая делает его одним из самых популярных алгоритмов Двойная форма SVM.
Двойная форма SVM
Это известно как двойная проблема.
SVM изучает линейный классификатор

формулируется как решение задачи оптимизации по αi:

Да, эта формулировка кажется очень запутанной и сложной ... Но поверьте мне, что это не так, все ваши сомнения рассеются через несколько минут. Это одна из самых красивых концепций, с которыми мне приходилось сталкиваться.
Итак, давайте посмотрим, как мы пришли к этой формулировке:
Лагранжиан SVM с жесткими границами:

Теорема о представителе утверждает, что решение w всегда можно записать как линейную комбинацию обучающих данных:

Рассчитаем норму || 𝑤 || ²

Теперь подстановка в ∑i 𝛼𝑖 [𝑦𝑖 (⟨𝑤, 𝑥𝑖⟩ + 𝑏) −1] может выполняться по частям:

средний член равен 0, поскольку первое ограничение нашей задачи оптимизации состоит в том, что ∑𝑖𝛼𝑖𝑦𝑖 = 0. Последний член, очевидно, равен −∑𝑖 𝑎𝑖. Подставляя здесь первый член:

Подставив это в уравнение 2, мы получим:

Теперь подставим уравнение 1 и уравнение 3 в лагранжиан SVM с жесткими границами.

который можно записать как

Комбинируя это с ограничениями αi ≥ 0, мы получаем следующую двойную задачу оптимизации:

Таким образом, мы получили двойную проблему :)
При выводе двойной формы, представленной до сих пор, предполагалось, что данные являются линейно разделяемыми. Чтобы алгоритм работал для нелинейно разделяемых наборов данных, а также был менее чувствительным к выбросам , мы переформулируем нашу задачу оптимизации следующим образом:

Как и раньше, мы можем сформировать лагранжиан как:

Здесь αi и ri - наши множители Лагранжа. Мы не будем повторять вывод двойственной снова, но после упрощения мы получим следующую двойственную форму задачи:

Единственное изменение в двойной задаче состоит в том, что то, что изначально было ограничением 0 ≤ αi, теперь стало 0 ≤ αi ≤ C.
Здесь, в двойной задаче SVM, αi ›0 для опорных векторов и αi = 0 для опорных векторов.
Вы, должно быть, задаетесь вопросом, зачем нам двойная форма SVM, когда у нас уже есть первичная форма. Итак, давайте разберемся, зачем они нам нужны и в чем их преимущества.
Взглянем еще раз на классификатор и формулировку:
Классификатор:

Проблема оптимизации:
Обратите внимание, что (x) встречается только парами (xj). (Xi). Это можно рассматривать как сходство между xi и xj. Это можно записать как K (xi, xj), где k называется функцией ядра.
Классификатор:

Проблема оптимизации:

Уловка с ядром
Это самая важная идея в SVM, где классификатор может быть изучен и применен без явного вычисления Φ (x).
Когда вы применяете линейную SVM и логистическую регрессию, результаты чаще всего выглядят очень похожими, потому что линейная SVM теоретически является очень хорошей идеей, но на практике это не так важно.

Кернелизация - самая важная идея в SVM. Кернелизация заставляет SVM обрабатывать нелинейно разделимые данные. Нелинейные данные можно обрабатывать в логистической регрессии только после применения преобразований функций, но здесь, в Kernel SVM, вам не нужно применять какое-либо преобразование функций, оно сделает всю работу за вас. Используя ядра, мы выполняем неявное преобразование функции и неявно преобразуем d-мерный элемент в d ^ -мерный элемент, так что (d ^ ›d). Есть очень хорошая теорема, называемая теорема Мерсера. Теорема Мерсера определяет, какие функции могут использоваться в качестве функций ядра. Центральная идея, лежащая в основе так называемого «ядра» Уловка »заключается в том, что закрытая форма ядра Mercer позволяет эффективно решать множество задач нелинейной оптимизации. В сообществе машинного обучения хорошо известно, что ядра связаны с «картами функций», и процедура на основе ядра может интерпретироваться как отображение данных из исходного входного пространства в потенциально более высокое размерное «пространство функций», где линейные методы могут тогда можно использовать.
Если вы хотите узнать больше о теореме Мерсера, посетите эту ссылку http://people.cs.uchicago.edu/~niyogi/papersps/MinNiyYao06.pdf
Используя трюк с ядром, классификаторы могут быть изучены для пространств многомерных функций без необходимости отображать точки в многомерные пространства. Выглядит интересно? Давайте изучим это подробнее
Полиномиальные ядра
Полиномиальное ядро определяется как
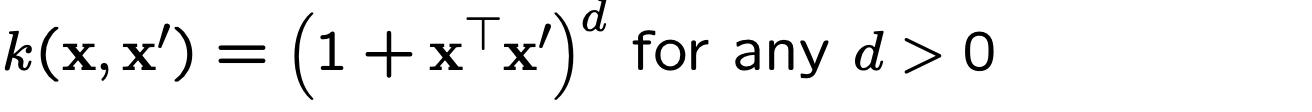
Давайте посмотрим на пример квадратичного ядра:
k(x1,x2)=(c+x1.x2)²

Посмотрите, как квадратичное ядро разделяет нелинейные данные

Ядро радиальной базисной функции
Во всей литературе по SVM наиболее популярным ядром общего назначения является ядро RBF.

Здесь σ - гиперпараметр, σ работает так же, как K в алгоритме KNN. При увеличении σ модель k (x1, x2) увеличивается, а при уменьшении σ k (x1, x2) уменьшается. Как обсуждалось ранее, мы можем интерпретировать k (x1, x2) как подобие, поэтому с увеличением значения σ подобие увеличивается

Ядро Гаусса

Ядро для конкретного домена
Конкретные ядра предназначены для специальных доменов.
Пример: для классификации текста используется Строковое ядро , для данных генома используется Ядро генома.
Если вы не знаете, какое ядро лучше всего использовать, выберите RBF Kernel.