В этой статье мы обсудим сходство косинусов с примерами его применения к сопоставлению произведений в Python.
Оглавление:
- Введение
- Косинусное подобие (обзор)
- Сходство продуктов с использованием Python (пример)
- Вывод
Введение
Многие интересные кейсы и проекты в области рекомендательных систем в значительной степени зависят от правильного определения сходства между парами элементов и/или пользователей.
Существует несколько подходов к количественной оценке подобия, которые преследуют одну и ту же цель, но различаются подходом и математической формулировкой.
В этой статье мы рассмотрим один из этих методов количественной оценки, который представляет собой косинусное сходство. И мы расширим изученную теорию, применив ее к выборочным данным, пытаясь найти сходство пользователей.
Концепции, изученные в этой статье, затем можно применить к различным проектам: сопоставление документов, механизмы рекомендаций и т. д.
Косинусное подобие (обзор)
Косинусное сходство — это мера сходства между двумя ненулевыми векторами. Он рассчитывается как угол между этими векторами (который также совпадает с их внутренним произведением).
Ну, это звучало как много технической информации, которая может быть новой или сложной для учащегося. Мы разберем его по частям вместе с подробными визуализациями и примерами здесь.
Рассмотрим три вектора:

и построим их в декартовой системе координат:
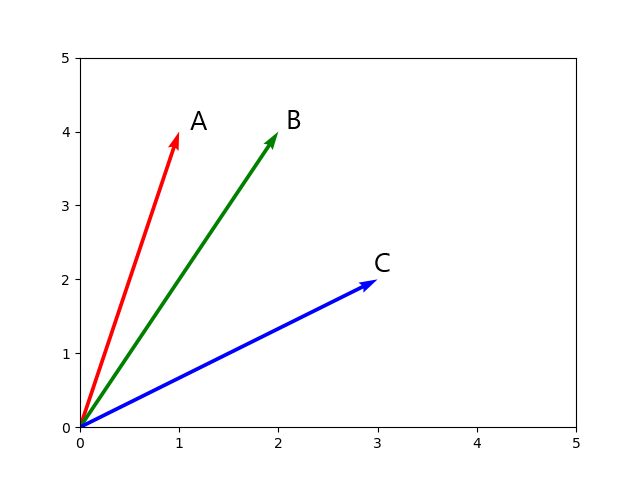
Из графика видно, что вектор A больше похож на вектор B, чем, например, на вектор C.
Но как мы могли сказать? Ну, просто взглянув на него, мы видим, что они A и B ближе друг к другу, чем A к C. . Математически говоря, угол A0B меньше, чем A0C.
Возвращаясь к математической формулировке (давайте рассмотрим вектор A и вектор B), косинус двух ненулевых векторов можно получить из евклидова скалярного произведения:

который решает для:

Решение для компонентов
Разберем приведенную выше формулу.
Шаг 1:
Начнем с номинатора:

где Ai и Bi — i-е элементы векторов A и B.
Для нашего случая имеем:

Отлично, мы нашли скалярное произведение векторов A и B.
Шаг 2:
Следующим шагом будет работа со знаменателем:

Мы рассматриваем произведение длин векторов. Простыми словами: длина вектора A умножается на длину вектора B.
Длина вектора может быть вычислена как:

где A_i — i-й элемент вектора A.
Для нашего случая имеем:

Шаг 3.
На данный момент у нас есть все компоненты для исходной формулы. Давайте подключим их и посмотрим, что мы получим:

Эти два вектора (вектор A и вектор B) имеют косинусное подобие 0,976. Обратите внимание, что этот алгоритм является симметричным, то есть сходство A и B такое же, как сходство B и A.
Сложение
Выполняя те же шаги, вы можете найти косинусное сходство между векторами A и C, что должно дать 0,740.
Это подтверждает то, что мы предположили, глядя на график: вектор A больше похож на вектор B, чем на вектор C. В примере, который мы создали в этом руководстве, мы работаем с очень простым случаем двумерного пространства, и вы можете легко увидеть различия на графиках. Однако в реальной ситуации все может быть не так просто. В большинстве случаев вы будете работать с наборами данных, которые имеют более двух признаков, создавая n-мерное пространство, визуализировать которое очень сложно без использования некоторых методов уменьшения размерности (PCA, tSNE).
Сходство продуктов с использованием Python (пример)
Примеры векторного пространства необходимы нам, чтобы понять логику и процедуру вычисления сходства косинусов. Теперь, как мы используем это в реальных задачах?
Давайте поместим приведенные выше векторные данные в какой-нибудь пример из реальной жизни. Предположим, мы работаем с некоторыми данными об одежде и хотим найти товары, похожие друг на друга. У нас есть три вида одежды: худи, свитер и кроп-топ. Доступные данные о продукте следующие:

Обратите внимание, что мы используем точно такие же данные, как и в теоретическом разделе. Но помещение в контекст значительно облегчает визуализацию вещей. Исходя из приведенного выше набора данных, мы связываем толстовку с капюшоном, которая больше похожа на свитер, чем на укороченный топ. На самом деле данные показывают нам то же самое.
Чтобы продолжить следовать этому руководству, нам понадобятся следующие библиотеки Python: pandas и sklearn.
Если он у вас не установлен, откройте «Командную строку» (в Windows) и установите его, используя следующий код:
pip install pandas
pip install sklearnПервый шаг, который мы сделаем, — создадим указанный выше набор данных в виде фрейма данных в Python (только со столбцами, содержащими числовые значения, которые мы будем использовать):
Мы должны получить:

Затем, используя метод cosine_similarity() из библиотеки sklearn, мы можем вычислить косинусное сходство между каждым элементом в приведенном выше кадре данных:
Выход представляет собой массив со сходствами между каждой из записей фрейма данных:

Для лучшего понимания приведенный выше массив можно отобразить как:

Обратите внимание, что результат вычислений идентичен ручному расчету в теоретическом разделе. Конечно данные здесь простые и только двухмерные, отсюда и высокие результаты. Но ту же методологию можно распространить на гораздо более сложные наборы данных.
Вывод
В этой статье мы обсудили сходство косинусов с примерами его применения для сопоставления произведений в Python.
Многие из вышеперечисленных материалов являются основой сложных рекомендательных движков и алгоритмов прогнозирования.
Я также рекомендую вам ознакомиться с другими моими сообщениями о Машинном обучении.
Не стесняйтесь оставлять комментарии ниже, если у вас есть какие-либо вопросы или предложения по некоторым изменениям.
Первоначально опубликовано на https://pyshark.com 27 октября 2020 г.