
Машинное обучение - это область, в которой данные считаются благом для отрасли. В машинном обучении слишком много данных иногда может привести к плохим результатам. В какой-то момент наличие большего количества функций (размеров) в ваших данных может снизить качество вашей модели. Этот термин известен как проклятие размерности в науке о данных.
Что такое уменьшение размерности?
С ростом индустрии данных и пользователей Интернета каждый день генерируется огромное количество данных. Многонациональные компании заинтересованы в сборе все большего и большего количества данных о пользователях, чтобы улучшить их пользовательский опыт, лучше понять их. можно сказать, что большинство компаний сейчас становятся своего рода компаниями, управляемыми данными, чтобы стать лучшими в своей отрасли. Для этого они продолжают собирать данные, которые день ото дня сильно увеличиваются.
Принято считать, что не все данные будут полезны для обучения моделей ИИ. Многие неважные параметры удаляются на начальных этапах с помощью визуализаций, которые не оказывают существенного влияния на результаты.
Кроме того, размерность уменьшается с помощью методов уменьшения размерности.
Почему?
- Меньшее количество измерений приводит к меньшему времени обучения.
- Он учитывает фактор мультиколлинеарности и удаляет лишние функции.
- Легко визуализировать менее размерные данные.
И двумя важными и современными методами уменьшения размерности являются PCA (анализ главных компонентов) и TSNE (T-распределенное стохастическое соседнее вложение). В этом блоге я расскажу обо всех теоретических концепциях PCA.
Это просто. Так что задержите дыхание и давайте начнем 📖
Анализ главных компонентов
это метод неконтролируемого линейного преобразования, который в основном используется для выделения признаков и уменьшения размеров. Без присмотра, поскольку он находит закономерности и закономерности без какого-либо контроля, то есть самостоятельно.
В основе анализа главных компонентов лежат стандартные статистические операции. В основном - среднее значение, ковариация, собственные векторы, собственные значения.
Итак, прежде чем приступить к пониманию и расчетам, давайте разберемся на части, что мы собираемся делать:
- Стандартизируйте d -мерный набор данных и получите среднее значение для каждого измерения.
- Вычислите матрицу ковариации.
- Вычисление собственных значений из ковариационной матрицы.
- Вычислить собственные векторы по собственным значениям.
- Выберите k собственных векторов, которые соответствуют k наибольшим собственным значениям, где k - это измерение, до которого вы хотите уменьшить набор данных (k ≤ d) .
- Главный компонент или матрица проекции из выбранных собственных векторов.
- Преобразуйте d -мерный входной набор данных, используя матрицу проекции, чтобы получить новый k -мерный набор данных.
Вот и все
Я объясню все это на случайном двумерном примере, который в дальнейшем можно применить к любому многомерному набору данных для уменьшения размеров.
Итак, приступим, ребята… .📑
Так, например, возьмем эти простые двухмерные данные с двумя столбцами X и Y.
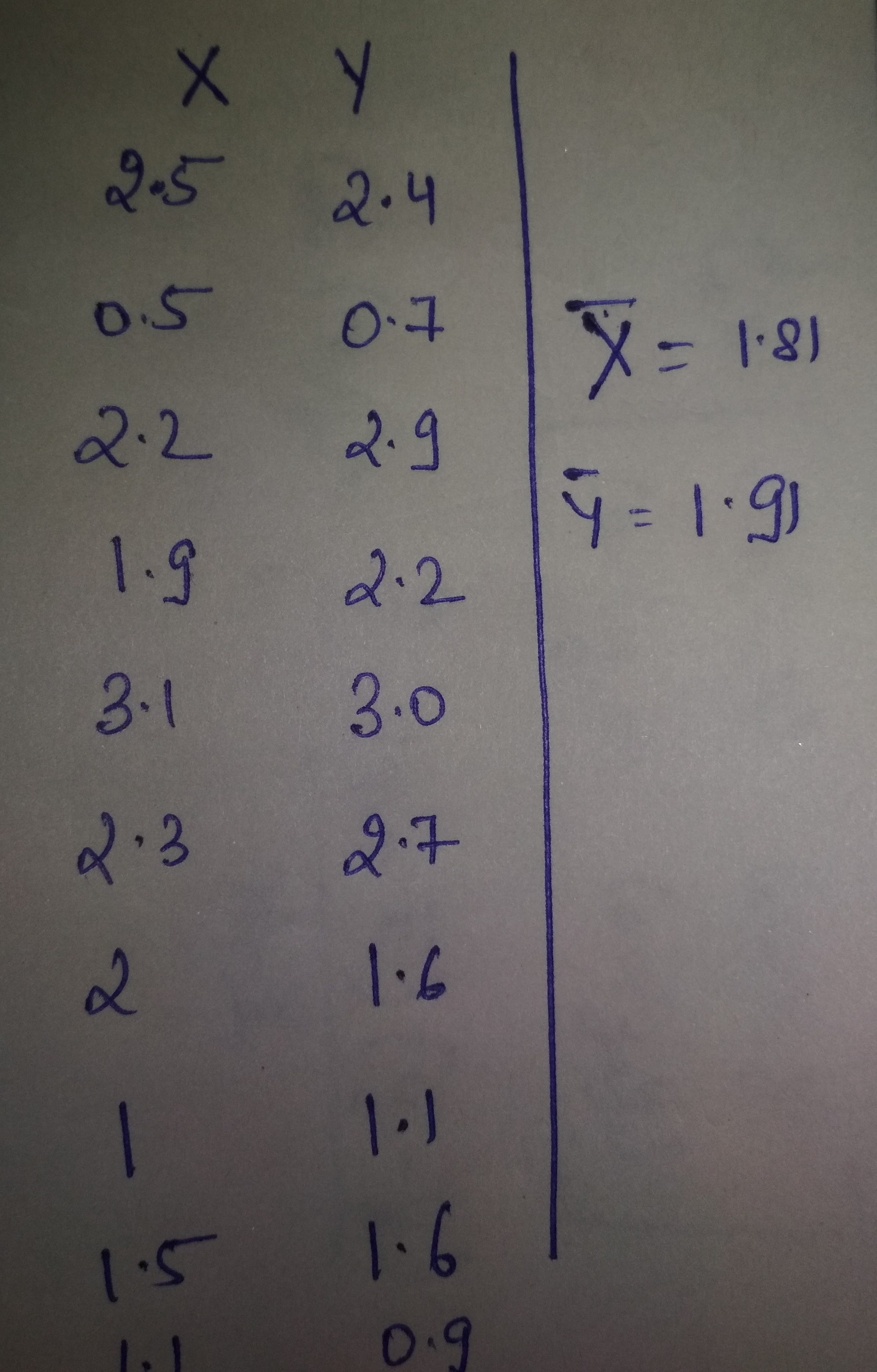
Итак, наш первый и основной шаг - вычислить среднее значение каждого столбца, как вычислено на изображении выше mean_X = 1.81 и mean_Y = 1.91.
Есть два варианта: вы можете сначала стандартизировать данные или просто начать со среднего значения, и оно будет сбалансировано в вычислении матрицы ковариации.

C - это основная ковариационная матрица, которую нам нужно вычислить. Примечание. Поскольку у нас есть два столбца, его размер составляет 2 x 2. Если у нас будет больше столбцов, он соответственно увеличится.
Для полной матрицы ковариации нам необходимо вычислить ковариацию различных комбинаций. Формула этого приведена выше, то есть Cov.
Пример →

Таким образом, мы рассчитаем нашу полную матрицу ковариации, и окончательная матрица будет выглядеть так →
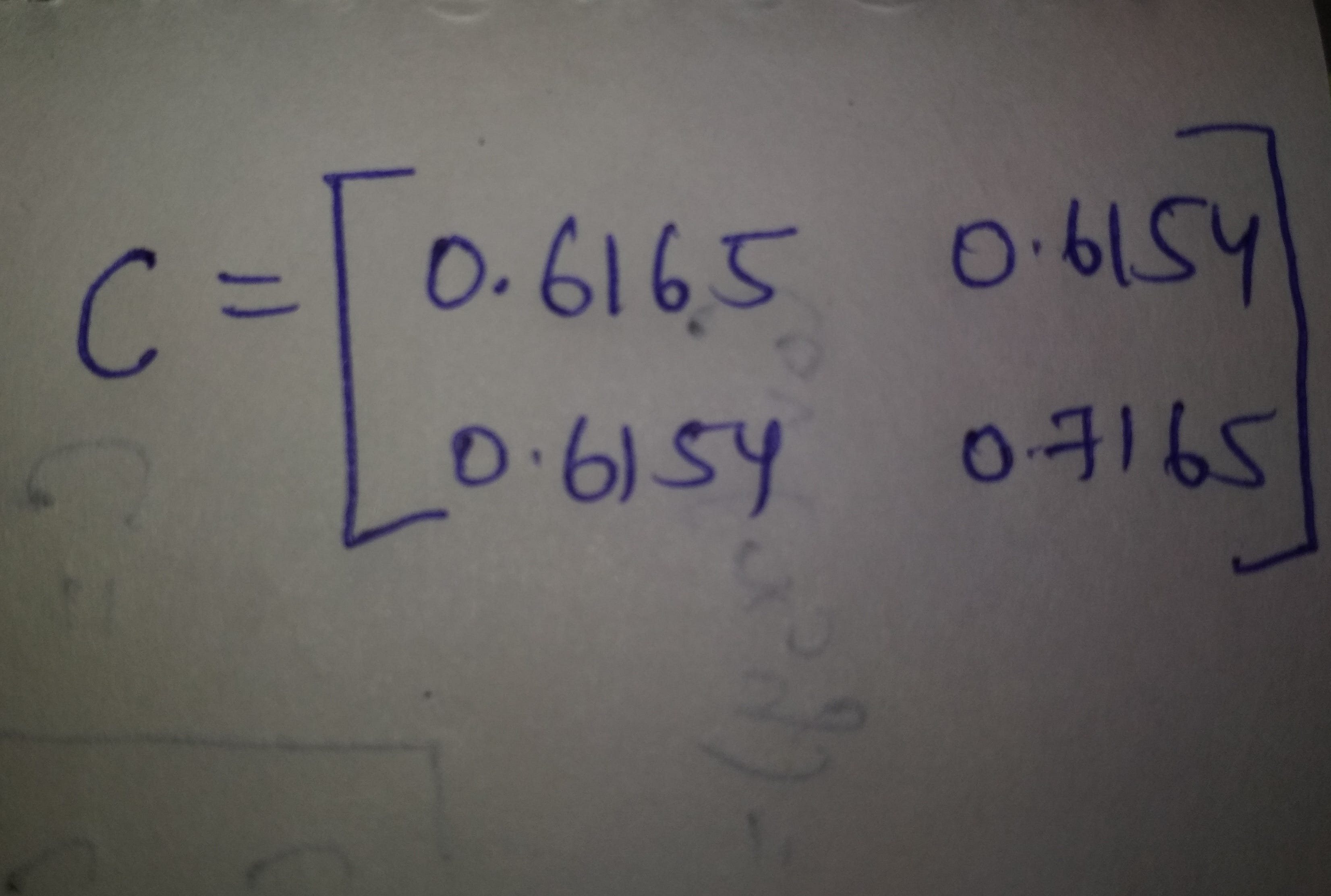
Теперь мы выполнили половину нашей задачи по вычислению главного компонента. Теперь нам нужно вычислить собственные векторы. Для этого мы используем формулу.
C — λ I = 0
где C - это матрица ковариации, которую мы вычислили, а I - матрица идентичности. λ даст нам наши собственные значения.

При использовании данной формулы будет сформирована матрица, и после вычисления определителя матрицы мы получим квадратное уравнение относительно λ. Таким образом, мы можем вычислить два собственных значения.
После этого наступает важный шаг по вычислению собственных векторов по этим собственным значениям.
Теперь мы поместим разные собственные значения в предыдущее уравнение, чтобы вычислить разные собственные векторы. Нравится.

Мы получим два уравнения, как указано выше, для 1 собственного значения, с помощью которых мы можем вычислить конкретный собственный вектор. Таким образом, мы можем вычислить два собственных вектора для двух собственных значений для этого примера. Тогда те же собственные векторы показаны ниже в матричной форме.

Уменьшили ли мы наши размеры 🤔
Очевидно, нет !! до настоящего времени.
До сих пор мы рассчитывали только собственные векторы. Во-первых, нам нужно вычислить наш главный компонент, чтобы уменьшить размерность.
Итак, как рассчитать главную составляющую?
Для этого нам сначала нужно сосредоточиться на собственных значениях. Большое собственное значение имеет большее значение, поэтому вектор, относящийся к этому конкретному собственному значению, будет иметь большее значение, чем другое.
Мы взяли только два измерения. Но в обобщенном виде мы можем сказать, что для уменьшения размерности до k мы возьмем только верхние k важных собственных векторов. Что будет вычислять нашу главную составляющую. Остальное оставим.
Что делать после получения главного компонента?
Имея k собственных векторов, мы получили нашу главную компоненту или так называемую матрицу проекции. Теперь просто преобразуйте d -мерный входной набор данных X с помощью матрицы проекции, чтобы получить новую k -мерную функцию. подпространство.
На этом мы завершили сокращение размеров с помощью PCA.
Где сейчас?
Как теперь вы узнали об уменьшении размеров с помощью PCA. Теперь я посоветую вам немного запачкать руки и запрограммировать это. Я расскажу о коде в своем следующем сообщении в блоге.
Вы также должны знать алгоритм TSNE для уменьшения размерности. Поскольку PCA я считал немного устаревшим алгоритмом. Но TSNE - новейший и к тому же широко используемый. Я расскажу о концепциях TSNE в своих будущих блогах.
До тех пор счастливого обучения и оставайтесь в безопасности !!
Пожалуйста, хлопайте в ладоши, если вам это нравится 👏👏.
Также ознакомьтесь с моими предыдущими сообщениями в блоге.