
Backpropagation (обратное распространение ошибок) - широко используемый алгоритм при обучении сетей прямого распространения. Он вычисляет градиент функции потерь по отношению к весам сети. Основная идея состоит в том, чтобы разбить большие функции на мелкие части и использовать частные производные для получения производной функции с помощью правила цепочки.
Таким образом, обучение модели в основном решает это уравнение:
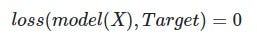
И поскольку решение этой задачи может быть очень сложной, здесь возникает обратное распространение и градиентный спуск (обновление весов на небольшую величину на основе градиента для перемещения в направлении минимизации потерь).
Все это основано на простом правиле цепочки дифференцирования:

Например, у нас есть простая функция с 2 узлами (операция):
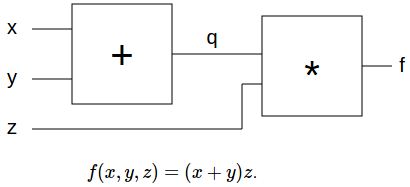
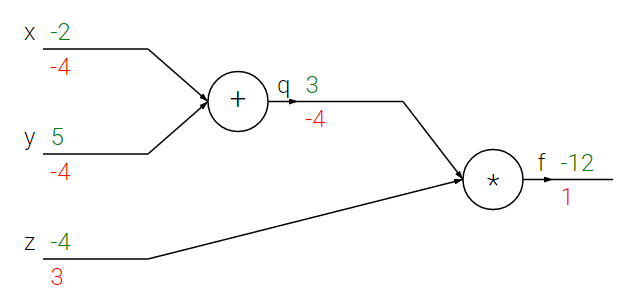
Допустим, у нас есть 3 переменные x = -2, y = 5, z = -4, результат будет f = -12, а наша цель для обучения - -13. Простая потеря = f-цель = 1.
Теперь нам нужно распространить нашу ошибку (1) обратно на x, y, z. Для этого нам потребуется вычислить частные производные для каждой функции (операции):
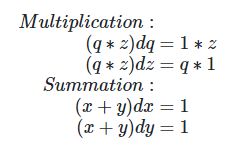
И наша цепочка:

Давайте создадим простой пример Autograd
Здесь мы построим простой пример автоматического дифференцирования из приведенных выше формул.
Теперь посмотрим, что будет
Проверка с помощью PyTorch Autograd
Как видите, мы получили те же градиенты, что и в нашем простом решении Autograd.
Построим нейронные сети и решим 2 простые задачи.
Для простоты мы не будем использовать здесь Autograd и будем решать производную для каждого слоя.
Запуск простой точечной интерполяции
Классификация MNIST с помощью нашей настраиваемой сети
Теперь давайте решим некоторую задачу классификации набора данных MNIST. Мы будем использовать некоторые утилиты PyTorch, чтобы упростить задачу.
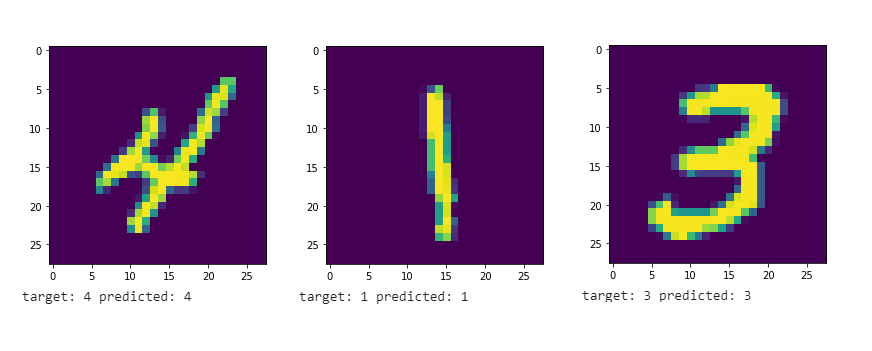
И это все. Не забывайте, что вы можете запустить этот код в Google Colab