
Локально-линейное вложение (LLE) - это метод уменьшения нелинейной размерности, предложенный Сэмом Т. Роуисом и Лоуренсом К. Саулом в 2000 году в их статье Уменьшение нелинейной размерности с помощью локально-линейного вложения. Эта статья основана на нескольких источниках, упомянутых в разделе ссылок. Проект Дженнифер Чу помог мне лучше понять LLE.
Алгоритмы машинного обучения используют функции, которым они обучены, для прогнозирования результатов. Например, в случае задачи прогнозирования цен на жилье может быть ряд характеристик, таких как размер дома, количество спален, количество ванных комнат и т. Д., Которые обучаются с использованием некоторой модели машинного обучения, чтобы попытаться предсказать цена дома максимально точно. Одной из основных проблем, с которыми сталкиваются многие алгоритмы машинного обучения при этом, является проблема переобучения, когда модель настолько хорошо соответствует обучающим данным, что не может точно предсказать данные реальных испытаний. Это проблема, поскольку это делает алгоритм очень эффективным.
Снижение размерности помогает снизить сложность модели машинного обучения, что в некоторой степени снижает переоснащение. Это происходит потому, что чем больше функций мы используем, тем сложнее становится модель, и это может привести к тому, что модель будет слишком хорошо соответствовать данным, что приведет к переобучению. Также могут использоваться функции, которые не помогают определить метку вывода, что может не помочь в реальной жизни. Например, в задаче прогнозирования цен на жилье у нас может быть такая особенность, как возраст продавца, которая никоим образом не может повлиять на цену дома. Снижение размерности помогает нам сохранить наиболее важные функции в наборе функций, уменьшая количество функций, необходимых для прогнозирования выходных данных.

Локально линейное встраивание (LLE)
Наборы данных часто могут быть представлены в n-мерном пространстве признаков, при этом каждое измерение используется для определенного объекта.
Алгоритм LLE - это неконтролируемый метод уменьшения размерности. Он пытается уменьшить эти n-измерения, пытаясь сохранить геометрические элементы исходной нелинейной структуры элементов. Например, на иллюстрации ниже мы отлили структуру швейцарского рулона в плоскость меньшего размера, сохраняя при этом его геометрическую структуру.
Короче говоря, если у нас есть D-измерения для данных X1, мы пытаемся уменьшить X1 до X2 в пространстве признаков с d-измерениями.
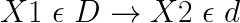
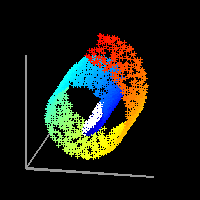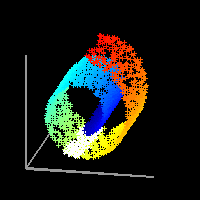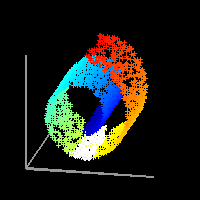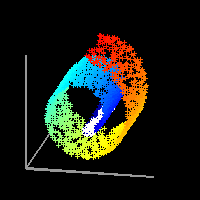
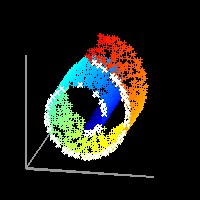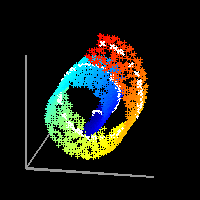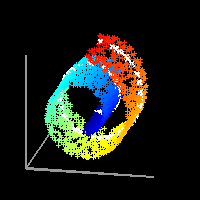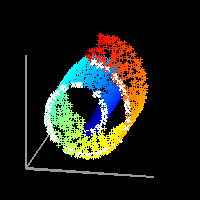
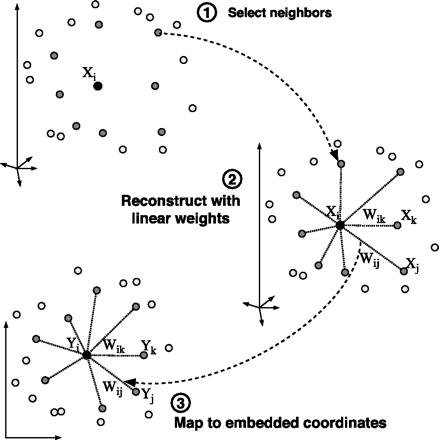
LLE сначала находит k-ближайших соседей точек. Затем он аппроксимирует каждый вектор данных как взвешенную линейную комбинацию своих k-ближайших соседей. Наконец, он вычисляет веса, которые лучше всего восстанавливают векторы от своих соседей, а затем производит векторы малой размерности, лучше всего восстанавливаемые с помощью этих весов [6].
- Нахождение K ближайших соседей.
Одним из преимуществ алгоритма LLE является то, что существует только один параметр, который нужно настроить, а именно значение K или количество ближайших соседей, которые следует рассматривать как часть кластера. Если K выбран слишком маленьким или слишком большим, он не сможет вместить геометрию исходных данных.
Здесь для каждой точки данных, которые у нас есть, мы вычисляем K ближайших соседей. - Мы производим взвешенное агрегирование соседей каждой точки, чтобы построить новую точку. Мы пытаемся минимизировать функцию стоимости, где j-й ближайший сосед для точки Xi.
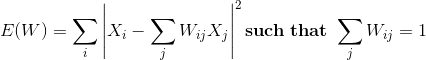
3. Теперь мы определяем новое векторное пространство Y таким образом, чтобы минимизировать стоимость Y как новых точек.
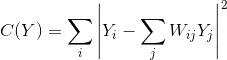
Подробный псевдокод этого алгоритма можно найти здесь.
Преимущества LLE перед другими алгоритмами уменьшения размерности
- Учет нелинейности структуры
LLE выходит за рамки методов моделирования плотности, таких как локальный PCA или смеси анализаторов факторов. Модели плотности не обеспечивают согласованного набора глобальных координат, которые включают наблюдения по всему многообразию; поэтому их нельзя использовать, например, для визуализации низкоразмерных проекций исходного набора данных. Они могут обнаруживать только линейные объекты, как показано на изображении ниже. Он плохо справляется с обнаружением изогнутого рисунка под ним, который LLE может обнаружить.
Точно так же другие методы, такие как Kernel PCA, Isomap, также не могут обнаруживать функции, которые обнаруживает LLE.
В На изображениях ниже мы видим, что окрестности локальных точек были сохранены LLE, но не другими алгоритмами.

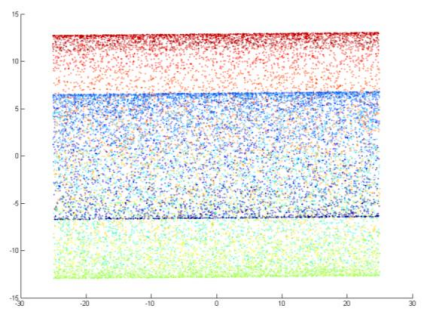

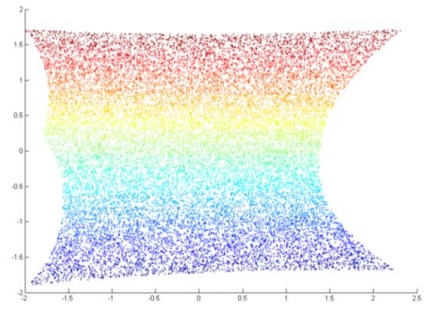
2. Лучшее время вычислений
Поскольку LLE имеет тенденцию накапливать разреженные матрицы, он более эффективен, чем другие алгоритмы, с точки зрения вычислительного пространства и времени.
Ссылки
- Http://www.math.sjsu.edu/~gchen/Math285F15/285%20Final%20Project%20-%20LLE.pdf
- Https://cs.nyu.edu/~roweis/lle/
- Https://www.geeksforgeeks.org/dimensionality-reduction/
- Https://towardsdatascience.com/dimensionality-reduction-for-machine-learning-80a46c2ebb7e
- Https://towardsdatascience.com/principal-component-analysis-for-dimensionality-reduction-115a3d157bad
- Https://www.youtube.com/watch?v=scMntW3s-Wk&t=27s