Прелесть алгоритмов машинного обучения в том, что они могут настраиваться во время обучения в соответствии с заданной стратегией оптимизации. Вообще говоря, стратегии оптимизации направлены на минимизацию ошибки, обусловленной разницей между реальной целью и результатом алгоритма. Для каждой итерации обучения алгоритм будет вычислять эту ошибку и повторно откалибровать свой параметр, чтобы на следующей итерации ошибка была уменьшена.
Нейронные сети, типичные алгоритмы, используемые в задачах глубокого обучения, следуют той же процедуре, которая называется обратным распространением, и это тема, которую мы собираемся обсудить в этой статье. Поскольку я не собираюсь здесь объяснять функционирование NN, я рекомендую вам прочитать мою предыдущую статью, где я объясняю, как построить NN с нуля.
Перед тем как начать, вспомним структуру НС:

Итак, у нас есть входные данные или функции, затем некоторые математические операции, одна или несколько функций активации и наши выходные данные. Этап вычисления выходных данных называется прямым распространением. Напротив, сейчас мы продолжим движение в обратном направлении, чтобы оценить наши результаты и перенастроить веса.
Идея Backpropagation заключается в том, что мы можем улучшить нашу модель путем повторной калибровки весов нашей NN, чтобы результат был все ближе и ближе к реальной цели.
Как мы можем реализовать эту процедуру? Ответ - концепция градиентного спуска. Идея состоит в том, что мы можем представить на графике потерю нашего алгоритма по отношению к весам. А именно, если перед нами модель только с одним весом, у нас будет что-то вроде этого:
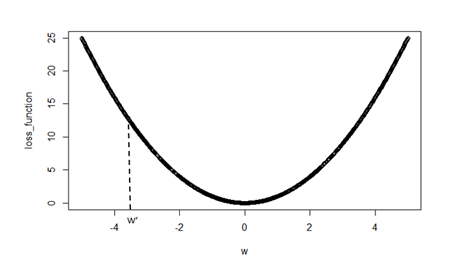
Как видите, текущее значение w ’не минимизирует потери. В идеале мы хотели бы изменить наш вес на 0, поскольку это значение, при котором потери минимизированы. Процедура градиентного спуска сообщает нам, что новый вес будет равен:
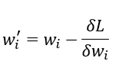
По сути, он изменится на член, равный первой производной потери по отношению к этому весу. В многомерной задаче каждый вес будет изменяться на частную производную функции потерь по этому весу.
Теперь подумайте о приведенном выше примере:

Мы хотим, чтобы наш вес соскользнул «вправо», чтобы он увеличивался. Поскольку производная будет отрицательной (интуиция: наклон касательной в этой точке отрицательный), приведенная выше формула увеличит наш вес на производную функции потерь (по отношению к этому весу).
Давайте посмотрим, как это рассуждение справедливо для следующей НС:

Допустим, мы хотим вычислить изменение в w7. Для этого нам нужно вычислить частную производную функции потерь по w7. Благодаря цепному правилу мы можем разложить это вычисление следующим образом:

Теперь, если мы установим нашу функцию потерь равной MSE:

Мы можем вычислить каждый компонент нашей производной:

Обратите внимание, что производная сигмовидной функции (вторая строка) равна умножению между самой функцией и (1-функцией).
Теперь, применяя цепное правило, получаем:

Теперь давайте применим это рассуждение к некоторым числам.
Для этой цели я собираюсь использовать тот же пример из моей предыдущей статьи, где мы должны предсказать результат экзамена на основе часов обучения и среднего успеваемости данного студента:

Как видите, это задача двоичной классификации, поэтому мы собираемся закодировать нашу целевую переменную 'pass' или 'fail' с помощью соответственно 1 и 0. Теперь рассмотрим следующую NN, где веса были инициализированы случайным образом и функция активации - сигмовидная:

Для простоты я буду использовать ту же функцию потерь, что и раньше (MSE). Однако учтите, что такая функция обычно используется в задачах регрессии, тогда как при классификации мы обычно используем функцию потерь кросс-энтропии.

Исходя из этого результата, мы можем сделать вывод, что наш вес должен увеличиться, чтобы соскользнуть к минимуму, поскольку его частная производная отрицательна. Действительно:

Если вы повторите те же рассуждения со всеми весами, в конце вашего обратного распространения у вас будет новый набор весов, который приведет к результату, более близкому к реальной цели.