BigQuery - это полностью управляемое хранилище данных, предоставляемое Google Cloud Platform. Это один из самых популярных инструментов в арсенале Google, и то, как он масштабируется до петабайтной шкалы за несколько секунд, просто волшебство. Пользователи пишут свои запросы на знакомом языке SQL, и запросы обрабатываются для них прозрачно.
BigQuery состоит из двух компонентов: 1.) Хранилище (Colossus) 2.) Механизм запросов (Dremel). Оба этих компонента соединены друг с другом с помощью очень быстрого сетевого уровня под названием Jupiter, который обеспечивает двухсекционную пропускную способность до 10 Гбит / с. Colossus - это высокооптимизированное столбчатое хранилище, в котором хранятся сжатые данные и оптимизировано для невероятно быстрого извлечения структурированных данных. Dremel, механизм выполнения, преобразует ваш SQL в дерево выполнения и разбивает вычисления на слоты и микшеры. Слоты - это конечные узлы дерева, которые считывают данные из Colossus, а узлы микшера обрабатывают агрегаты. Подробнее об архитектуре BigQuery можно прочитать здесь.
Я не знал, что BigQuery также имеет интерфейс машинного обучения. Он позволяет создавать модели машинного обучения с комфортом SQL. В настоящее время BigQuery ML (BQML) поддерживает только линейную регрессию, двоичную и многоклассовую логистическую регрессию, а также кластеризацию K-средних.
В этом посте я расскажу вам о простом примере бинарной логистической регрессии, в котором мы можем предсказать, страдает ли человек диабетом, не основываясь на определенных характеристиках.
Итак, приступим.
Скачать набор данных
Мы будем использовать набор данных под названием "Диабет индейцев пима", предоставленный UCI. Вы можете бесплатно скачать его с kaggle здесь. Этот набор данных позволяет прогнозировать наличие у человека диабета на основе 8 характеристик (Беременность, Уровень глюкозы, Кровяное давление, Толщина кожи, Инсулин, ИМТ, Функция диабета, Родословная, Возраст). Результат - это столбец с меткой, который указывает, болен ли человек диабетом или нет. Во время обучения модели мы будем использовать столбец результат для обучения, а во время прогнозирования мы будем прогнозировать значение выходного столбца.
Загрузка набора данных в BigQuery
Перейти к большим данным ›Big Query в консоли.
Создайте набор данных, если у вас его еще нет. В BigQuery каждая таблица должна принадлежать к набору данных.
Нажмите кнопку создать набор данных и введите имя набора данных. Назовем это прима_индийский_диабет.

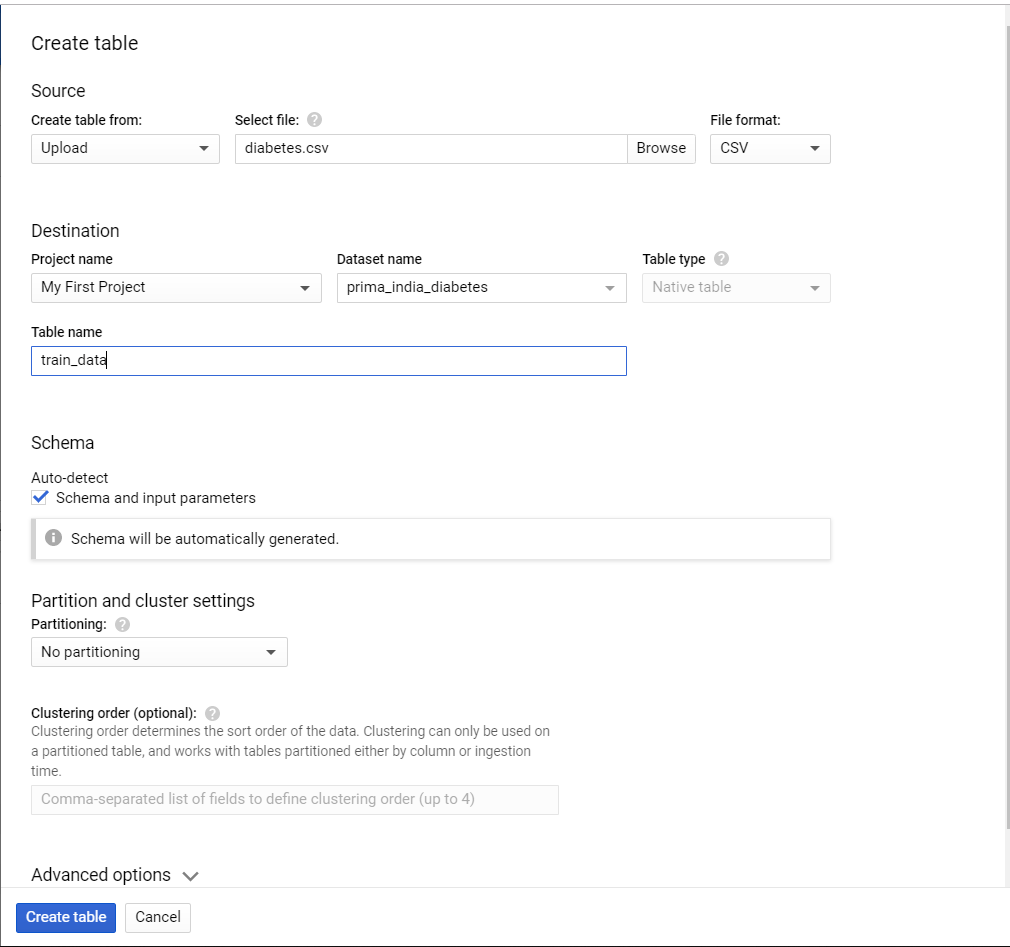
Затем мы создадим таблицу с загруженным CSV-файлом. Выберите только что созданный набор данных на левой панели и нажмите кнопку Создать таблицу.

Выберите источник как Загрузить и загрузите CSV-файл, который мы скачали. Дайте название своему столу. Я назову его train_data. Выберите Автоопределение для схемы. В нашем CSV-файле есть заголовки, которые будут обнаружены автоматически. Оставьте все остальные параметры по умолчанию. Хит создать таблицу.
Для завершения импорта потребуется несколько секунд. По завершении проверьте схему таблицы. Как видите, все столбцы импортируются с правильными типами данных.

Подходит для модели
BigQuery автоматически разделяет ваши данные по цепочке и удерживает набор, чтобы модель не переборщилась.
Тренировка тестового сплита
Мы создадим разделение «поезд-тест» из 75–25, чтобы мы могли оценить нашу модель, как только она будет готова. Мы создадим отпечаток пальца каждой строки, объединив все столбцы, и назначим ROW_SPLIT_ID между [0,3]. Затем мы выберем ROW_SPLIT_ID в (0,1,2) для обучения и 3 для оценки.
Подгонка модели
Вставьте запрос выше и нажмите "Выполнить". Подгонка модели должна начаться. Выполнение запроса займет 1-2 минуты. Теперь вы должны увидеть свою модель в наборе данных. Вы можете проверить статистику модели, нажав на нее.

Оценка модели
Теперь давайте оценим модель с помощью нашего набора данных проверки, используя метод ML.EVALUATE. ML.EVALUATE принимает два параметра: МОДЕЛЬ и набор данных.
Вышеупомянутый запрос вернет следующие параметры оценки:
Точность, отзыв, точность, площадь под кривой ROC, LogLoss и F1-Score.

У нас AUC составляет 86%, что неплохо с учетом того количества настроек (или их отсутствия), которые мы сделали. Вы можете прочитать документ CREATE MODEL здесь и настроить создание модели с помощью OPTIONS во время создания модели.
Бонус
Прогнозирование с использованием модели.
Мы будем использовать метод ML.PREDICT (имеющий такую же сигнатуру, что и ML.EVALUATE), чтобы предсказать результат.
Вставьте приведенный выше запрос и нажмите "Выполнить". Вы получите таблицу с вероятностями для каждого класса (0/1), основанными на этих вероятностях, predicted_outcome.

И вот она, модель двоичной логистической регрессии, полностью написанная на SQL, менее чем за 15 минут.
Если вы обнаружите какие-либо ошибки в коде или у вас есть сомнения, не стесняйтесь оставлять комментарий.
А до тех пор счастливого кодирования :)