Это сообщение в блоге является частью серии сообщений на Kubeflow. Этот пост является продолжением первой и второй части. В этих первых двух частях мы изучили, как основные компоненты Kubeflow могут облегчить задачи инженера по машинному обучению на единой платформе. В этой третьей части мы рассмотрим конвейеры Kubeflow (KFP), которые были введены с Kubeflow v0.4.
Обратите внимание: не обязательно читать первую и вторую части перед чтением третьей части о конвейерах Kubeflow.
На изображении ниже показан график конвейера Kubeflow:
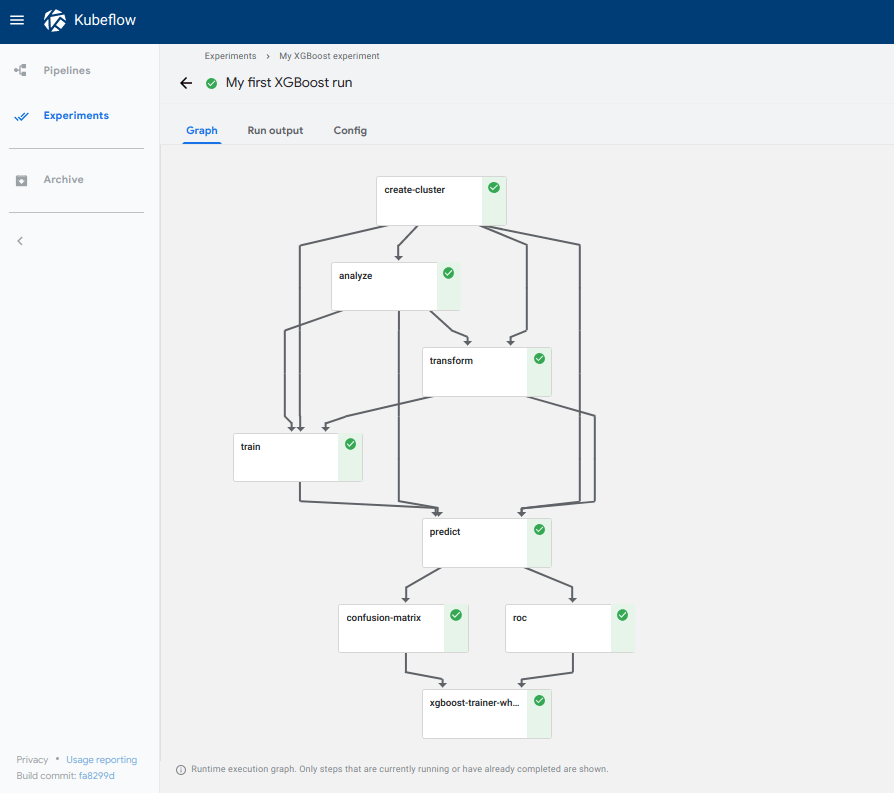
Почему
Часто рабочий процесс машинного обучения состоит из нескольких этапов, например: получение данных, предварительная обработка данных, обучение модели, обслуживание новых запросов и т. Д. В начале проекта вы можете выполнять эти действия вручную, но по мере того, как этапы становятся более зрелыми. , вы можете захотеть начать автоматизировать это по нескольким причинам (производительность, воспроизводимость и т. д.). Kubeflow Pipelines представляет собой элегантный способ решения этой проблемы автоматизации. По сути, каждый шаг рабочего процесса помещен в контейнеры, и Kubeflow Pipelines связывает их вместе. Kubeflow pipelines поставляется с пользовательским интерфейсом для отслеживания прогресса и проверки ваших результатов.
Настраивать
Вы можете использовать оболочку Google Cloud, чтобы выполнить шаги, описанные ниже. В качестве альтернативы вы можете работать из своей локальной среды, но в этом случае вам нужно будет убедиться, что вы установили требования:
Давайте сначала клонируем репозиторий:
$ git init $ git clone https://github.com/kubeflow/examples.git $ cd examples/
Разверните конвейеры Kubeflow в GKE
В этом сообщении блога мы решили развернуть только конвейеры Kubeflow в кластере Kubernetes вместо развертывания Kubeflow со всеми компонентами.
$ CLUSTERNAME=<your-cluster-name> $ ZONE=europe-west1-b $ gcloud beta container clusters create $CLUSTERNAME --enable-autoupgrade --zone $ZONE --scopes cloud-platform --enable-cloud-logging --enable-cloud-monitoring --machine-type n1-standard-1 --num-nodes 2
После создания кластера нам нужно будет настроить привязку ролей кластера, чтобы мы получили разрешение на развертывание загрузчика, который запустит необходимые компоненты Kubeflow Pipelines.
$ kubectl create clusterrolebinding ml-pipeline-admin-binding --clusterrole=cluster-admin --user=$(gcloud config get-value account)
Впоследствии мы можем развернуть загрузчик:
$ PIPELINE_VERSION=0.1.8 $ kubectl create -f https://storage.googleapis.com/ml-pipeline/release/$PIPELINE_VERSION/bootstrapper.yaml
При проверке модулей Kubernetes через kubectl get pods мы получаем:

Как только этот контейнер будет запущен, он начнет развертывание компонентов Kubeflow Pipelines в кластере Kubernetes в пространстве имен kubeflow.
Если вы хотите проверить прогресс, вы можете просто запустить kubectl get pods -n kubeflow:

Затем нам нужно создать корзину Google Cloud Storage, в которой будут храниться данные и модели.
$ BUCKET_NAME=<your-bucket-name> $ gsutil mb gs://$BUCKET_NAME/
Храните этапы конвейера в контейнерах
В предыдущей серии сообщений в блоге об этом сценарии использования финансовых временных рядов мы объединили предварительную обработку и обучение в одном скрипте, чтобы проиллюстрировать компонент TFJob в Kubeflow. На практике чаще всего этапы предварительной обработки и обучения разделены, и их нужно будет запускать последовательно каждый раз. Таким образом, мы отделяем предварительную обработку от обучения и можем быстрее выполнять итерации по различным экспериментам. Конвейеры Kubeflow предлагают простой способ связать эти шаги вместе, и мы это проиллюстрируем. Как видите, сценарий run_preprocess_and_train.py в tensorflow_model/ использует два базовых сценария run_preprocess.py и run_train.py. Идея здесь в том, что эти два шага будут контейнеризованы и связаны вместе конвейерами Kubeflow.
Поскольку эти два шага находятся в одном репозитории, мы можем создать один контейнер из репозитория и использовать один и тот же образ для двух шагов. Построим контейнер:
$ cd financial_time_series/tensorflow_model/
$ PROJECT_ID=<your-gcp-project-id>
$ IMAGE_NAME=pipeline-test
$ gcloud builds submit --tag gcr.io/$PROJECT_ID/$IMAGE_NAME:v1 .
Теперь нам нужно обновить код нашего конвейера ml_pipeline.py, чтобы он указывал на только что созданное изображение. Также обновите параметр значения сегмента до имени вашего сегмента (это не является строго необходимым, поскольку вы все равно можете установить этот параметр в пользовательском интерфейсе позже).
Построить трубопровод
Если вы проверите ml_pipeline.py, можно увидеть, что определение шагов конвейера несложно:
import kfp.dsl as dsl
class Preprocess(dsl.ContainerOp):
def __init__(self, name, bucket, cutoff_year):
super(Preprocess, self).__init__(
name=name,
# image needs to be a compile-time string
image='gcr.io/<project>/<image-name>/cpu:v1',
command=['python3', 'run_preprocess.py'],
arguments=[
'--bucket', bucket,
'--cutoff_year', cutoff_year,
'--kfp'
],
file_outputs={'blob-path': '/blob_path.txt'}
)
После определения отдельных шагов вы определяете фактические операции конвейера:
@dsl.pipeline(
name='financial time series',
description='Train Financial Time Series'
)
def train_and_deploy(
bucket=dsl.PipelineParam('bucket', value='<bucket>'),
cutoff_year=dsl.PipelineParam('cutoff-year', value='2010'),
version=dsl.PipelineParam('version', value='4'),
model=dsl.PipelineParam('model', value='DeepModel')
):
"""Pipeline to train financial time series model"""
preprocess_op = Preprocess('preprocess', bucket, cutoff_year)
train_op = Train('train and deploy', preprocess_op.output, version, bucket, model)
Следует упомянуть один важный аспект - это то, как контейнеры могут передавать параметры друг другу. Как видно из фрагментов кода выше, на этапе предварительной обработки выводится параметр blob-path, а значение - это каталог, в котором значение параметра было сохранено контейнером.
Если мы проверим run_preprocess.py, мы действительно заметим, что нам нужно записать файл в локальный каталог, чтобы передать этот параметр (! Это не происходит автоматически):
if args.kfp:
with open("/blob_path.txt", "w") as output_file:
output_file.write(file_path)
Обратите внимание, что локальный файл записывается только тогда, когда установлен аргумент «kfp», это необходимо для того, чтобы избежать этих локальных файлов при локальном запуске сценария.
Скомпилируйте конвейер
KFP просит нас скомпилировать наш файл конвейера Python3 на предметно-ориентированный язык. Мы делаем это с помощью инструмента под названием dsl-compile, который поставляется с Python3 SDK. Итак, сначала установите этот SDK:
$ pip3 install python-dateutil https://storage.googleapis.com/ml-pipeline/release/0.1.2/kfp.tar.gz --upgradeЧтобы фактически скомпилировать конвейер, вы можете запустить:
$ python3 ml_pipeline.pyЭто сгенерирует выходной файл, содержащий скомпилированный конвейер ml_pipeline.py.tar.gz. Если вы используете Google Cloud Shell, вам нужно будет загрузить ml_pipeline.py.tar.gz, чтобы вы могли загрузить его позже в пользовательском интерфейсе:

Запустите конвейер
Чтобы запустить конвейер, нам необходимо получить доступ к пользовательскому интерфейсу Kubeflow Pipelines и загрузить этот файл. Мы будем использовать переадресацию портов для подключения к пользовательскому интерфейсу Kubeflow Pipelines.
$ NAMESPACE=kubeflow
$ kubectl port-forward -n ${NAMESPACE} $(kubectl get pods -n ${NAMESPACE} --selector=service=ambassador -o jsonpath='{.items[0].metadata.name}') 8085:80Пользовательский интерфейс Kubeflow Pipelines теперь должен быть доступен по адресу http: // localhost: 8085 / pipeline /. Если вы используете Google Cloud Shell, вам нужно будет изменить порт предварительного просмотра на 8085 и настроить перенаправленный URL-адрес https: //8085-dot-…-dot-…-dot-devshell.appspot.com/edit/edit.html на https: //8085-dot-…-dot-…-dot-devshell.appspot.com/ pipeline.
Затем мы выбираем загрузку конвейера с помощью кнопки в правом верхнем углу.

После загрузки файла вы можете щелкнуть конвейер, и он покажет график, который визуализирует различные этапы конвейера.

Теперь мы создадим новый запуск и укажем наши параметры запуска.

Обратите внимание, что тип модели машинного обучения параметризован в нашем контейнере, поэтому мы можем передать его здесь как параметр запуска. Также мы можем поиграть с годом отсечения данных в качестве параметра времени выполнения. Практически каждый аргумент контейнера может иметь параметр конвейера, что позволяет очень легко повторно запускать рабочие процессы с другими параметрами.
После запуска конвейера конвейеры Kubeflow будут организовывать шаги за вас, и вы можете следить за прогрессом (включая журналы контейнера) в пользовательском интерфейсе.

Через несколько минут трубопровод должен быть завершен. Потенциально вы можете создать больше прогонов и поиграть с типом модели и годом отсечения данных, чтобы увидеть влияние на производительность.
Убираться
Чтобы очистить кластер, мы просто удалим его
$ gcloud container clusters delete $CLUSTERNAME --zone $ZONEПодробнее о Kubeflow Pipelines (KFP)
Если вы хотите узнать больше о конвейерах Kubeflow, обязательно загляните на сайт Kubeflow.
О ML6
Мы - команда экспертов в области ИИ и самая быстрорастущая компания в области ИИ в Бельгии. Имея офисы в Генте, Амстердаме, Берлине и Лондоне, мы создаем и внедряем системы самообучения в различных секторах, чтобы помочь нашим клиентам работать более эффективно. Мы делаем это, оставаясь на вершине исследований, инноваций и применяя наш опыт на практике. Чтобы узнать больше, посетите www.ml6.eu.