Погружение в литературу - что мы знаем?

Мы все (примерно) умеем естественно разговаривать друг с другом. Это в основном подсознательно и действительно заметно только в том случае, если взаимодействие отличается от того, что большинство считает «нормальным». В большинстве случаев это просто незначительные отличия, например, кто-то говорит слишком близко или перебивает чаще, чем обычно.
Однако более значительные различия в разговоре могут возникнуть, когда части мозга начинают снижаться.
СОДЕРЖАНИЕ
Введение
Обзор деменции
Охваченные статьи
Мотивация - почему речь?
Наборы данных
Модели
Важные особенности языка
Заключение
Вступление
В настоящее время я работаю над созданием более естественного диалогового агента (такого как Siri, Alexa и т. Д.) Для людей с когнитивными нарушениями, которым эти системы потенциально могут принести максимальную пользу. В настоящее время мы должны адаптировать то, как мы общаемся с этими системами, и должны точно знать, как запрашивать определенные функции. Для тех, кто изо всех сил пытается адаптироваться, я надеюсь снизить некоторые из этих барьеров, чтобы они могли жить более независимо и дольше. Если вы хотите узнать больше о проекте в целом, то я рассказал о нем более подробно в интервью здесь.
Чтобы начать этот проект с Wallscope и The Data Lab, я сначала исследовал некоторые из исследований, посвященных воссозданию естественного разговора с диалоговыми агентами. Все это исследование относилось к здоровому населению, но возник вопрос: меняются ли некоторые из этих явлений при разговоре с людьми, у которых есть формы когнитивных нарушений?
В моей предыдущей статье я рассмотрел две статьи, в которых обсуждается прогнозирование в конце хода. Они создали блестящие модели, чтобы предсказать, когда кто-то закончит свою очередь, чтобы заменить модели, которые просто ждут некоторого времени молчания.
Если кому-то с деменцией требуется немного больше времени, чтобы запомнить слово (слова), которые он ищет, модели порога молчания, используемые в существующих системах, прервут его. Я подозреваю, что исследовательские модели также будут работать хуже, чем со здоровым населением, поэтому я собираю корпус, чтобы исследовать это.
Поскольку моя конечная цель - сделать разговорные агенты более удобными для людей с деменцией, в этой статье я расскажу о некоторых исследованиях по теме.
Обзор деменции
Я ни в коем случае не эксперт по деменции, поэтому вся эта информация была собрана из удивительной серии видео Обществом Альцгеймера.

Деменция - это не болезнь, а название группы симптомов, которые обычно включают проблемы с:
- объем памяти
- Мышление
- Решение проблем
- Язык
- Зрительное восприятие
У людей с деменцией эти симптомы прогрессируют достаточно, чтобы повлиять на повседневную жизнь, и не являются естественной частью старения, поскольку вызваны различными заболеваниями (некоторые из них я выделяю ниже).
Все эти заболевания вызывают потерю нервных клеток, и со временем ситуация постепенно ухудшается, так как эти нервные клетки невозможно заменить.
По мере того, как умирает все больше и больше клеток, мозг сокращается (атрофируется) и симптомы обостряются. Какие симптомы проявятся первыми, зависит от того, какая часть головного мозга атрофируется, поэтому на людей воздействуют по-разному.
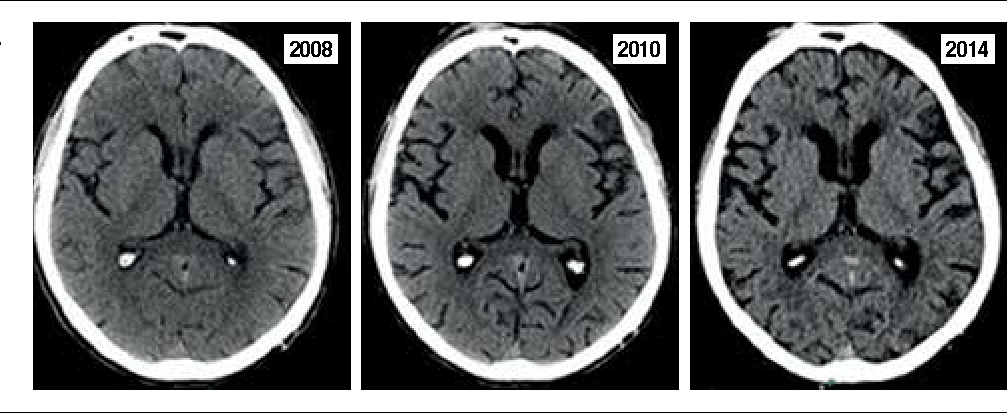
Например, если затылочная доля начинает опускаться, тогда зрительные симптомы будут прогрессировать, а потеря височной доли вызовет языковые проблемы ...
Другие общие симптомы влияют:
- Повседневная память
- Концентрация
- Организация
- Планирование
- Язык
- Зрительное восприятие
- Настроение
В настоящее время лекарства нет…
Прежде чем перейти к недавним исследованиям языковых проблем, важно не понимать, что большинство исследований посвящено конкретным заболеваниям. Поэтому я кратко расскажу о четырех типах деменции.
Вся эта информация снова исходит из серии видеороликов, созданных Обществом Альцгеймера.
Болезнь Альцгеймера
Самым распространенным типом деменции является болезнь Альцгеймера (БА), и по этой причине он также является наиболее изученным (вы заметите это в исследовании).
Здоровый мозг содержит белки (два из которых называются амилоидом и тау), но если мозг начинает работать ненормально, эти белки образуют аномальные отложения, называемые бляшками и клубками.
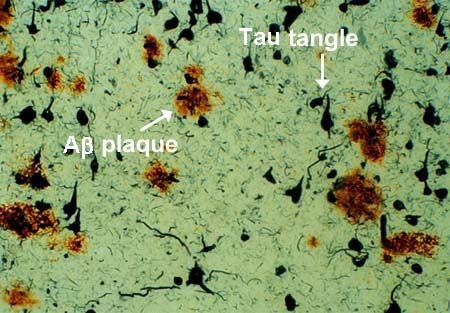
Эти бляшки и клубки повреждают нервные клетки, что приводит к их гибели и сокращению мозга, как показано выше.
Гиппокамп обычно является первой областью мозга, работоспособность которой снижается, когда у кого-то есть БА. К сожалению, именно здесь формируются воспоминания, поэтому люди часто забывают, что они только что сделали, и поэтому могут повторяться в разговоре.
Сначала теряются недавние воспоминания, тогда как детские воспоминания все еще могут быть восстановлены, поскольку они меньше зависят от гиппокампа. Кроме того, обычно можно вспомнить эмоции, поскольку миндалевидное тело все еще не повреждено, тогда как факты, окружающие эти эмоции, могут быть потеряны.
БА постепенно прогрессирует, поэтому симптомы со временем ухудшаются и становятся более многочисленными.
Сосудистая деменция
Второй по распространенности тип деменции - сосудистая деменция, вызванная проблемами с кровоснабжением головного мозга.
Нервным клеткам для выживания нужны кислород и питательные вещества, поэтому без них они повреждаются и умирают. Следовательно, когда кровоснабжение прерывается из-за закупорки или утечки, может быть нанесен значительный ущерб.
Как и при болезни Альцгеймера, симптомы зависят от того, какие части мозга поражены. Когда поврежденные части отвечают за память, мышление или язык, у человека будут проблемы с запоминанием, мышлением или речью.

Сосудистая деменция может быть вызвана инсультом. Иногда его может вызвать один серьезный инсульт, но в других случаях человек может страдать от нескольких более мелких инсультов, которые постепенно вызывают повреждение.
Наиболее частой причиной сосудистой деменции является заболевание мелких сосудов, которое постепенно сужает сосуды в головном мозге. По мере того, как сужение продолжается и распространяется, повреждается большая часть мозга.
Следовательно, сосудистая деменция может прогрессировать постепенно, как БА, или, если она вызвана инсультом, ступенчато, с ухудшением симптомов после каждого инсульта.
Деменция с тельцами Леви
Тесно связанный с БА, но реже, тип деменции, называемой деменцией с тельцами Леви.
Тельца Леви - это крошечные скопления белка, которые развиваются внутри нервных клеток головного мозга. Это препятствует общению между клетками, что приводит к их гибели.

Исследователи еще не определили, почему и как образуются тельца Леви. Однако мы знаем, что они могут образовываться в любой части мозга, что, опять же, приводит к различным симптомам.
У людей могут быть проблемы с концентрацией, движением, бдительностью и даже могут быть зрительные галлюцинации. Эти галлюцинации часто вызывают беспокойство и приводят к проблемам со сном.
Деменция с тельцами Леви прогрессирует постепенно и распространяется по мере повреждения нервных клеток, поэтому в конечном итоге всегда нарушается память.
Лобно-височная деменция
Последний тип деменции, о котором я расскажу, - это лобно-височная деменция (ЛВД), которая представляет собой ряд состояний, при которых повреждаются клетки лобных и височных долей мозга.
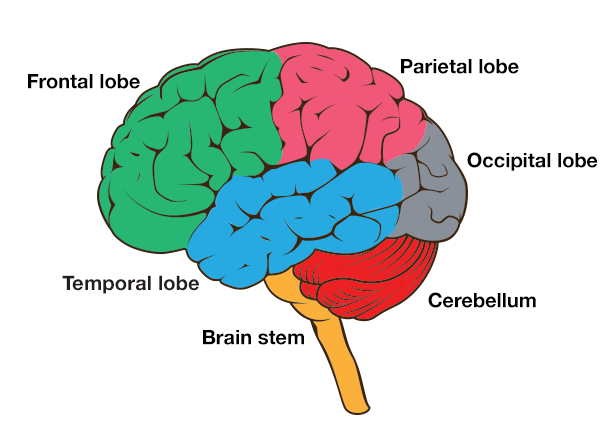
ЛВД снова является менее распространенным типом деменции, но, как ни странно, чаще поражает молодых людей (младше 65 лет).
Лобная и височная доли мозга контролируют поведение, эмоции и язык, а симптомы возникают в обратном порядке, в зависимости от того, какая доля затронута первой.
Лобная доля обычно первой теряет работоспособность, поэтому изменения начинают проявляться в личности человека, его поведении и запретах.
В качестве альтернативы, когда сначала затрагивается височная доля, человек будет бороться с речью. Например, они могут с трудом подобрать правильное слово.
Считается, что FTD возникает, когда белки, такие как тау, накапливаются в нервных клетках, но, в отличие от других причин, это, вероятно, наследственное.
В конце концов, по мере прогрессирования ЛВД симптомы лобного и височного повреждения накладываются друг на друга, и возникают оба.
Бумаги покрытые
Этот обзор деменции был довольно подробным, поэтому теперь у нас должна быть общая основа для этой статьи и всех последующих статей.
Как мы теперь знаем, трудности с речью - распространенный симптом слабоумия, поэтому, чтобы понять, как они меняются, я рассмотрю четыре статьи, в которых исследуется этот вопрос. К ним относятся следующие:
[1]
Инструмент распознавания речи для раннего выявления болезни Альцгеймера Брианны Марлен Бродерик, Си Лонг Ту и Эмили Мауэр Провост
[2]
Метод анализа речи пациента в диалоге для выявления деменции Сатурнино Луз, София де ла Фуэнте и Пьер Альбер
[3]
Обработка речи для ранней диагностики болезни Альцгеймера: подход, основанный на машинном обучении Ранда Бан Аммар и Ясин Бен Айед
[4]
Выявление когнитивных нарушений путем согласования интерпретации языковых особенностей Зининга Чжу, Екатерины Новиковой и Франк Рудзич
Примечание. С этого момента я буду называть каждую статью соответствующим номером.
Мотивация - почему речь?
Эти четыре статьи имеют общую мотивацию: выявить деменцию более экономичным и менее навязчивым способом.
В этих статьях основное внимание уделяется болезни Альцгеймера (БА), потому что, как упоминается в [3], 60–80% случаев деменции вызваны БА. Я бы добавил, что, вероятно, именно поэтому AD больше всего присутствует в существующих наборах данных.
Современные методы обнаружения
[1] указывает на то, что деменцию относительно сложно диагностировать, поскольку ее прогрессирование и симптомы сильно различаются. Поэтому диагностические процессы сложны, и из-за этого деменция часто не диагностируется.
[2] объясняет, что визуализация (например, ПЭТ или МРТ) и анализ спинномозговой жидкости могут использоваться для очень точного обнаружения БА, но эти методы дороги и чрезвычайно инвазивны. Люмбальная пункция необходима, например, для сбора спинномозговой жидкости.

[2] также указывает на то, что были разработаны нейропсихологические методы обнаружения, которые могут с разной степенью точности обнаруживать признаки БА. [1] добавляет, что они часто требуют повторного тестирования и, следовательно, отнимают много времени и вызывают дополнительный стресс и замешательство у пациента.
Как упоминалось выше, [1] утверждает, что деменция часто не диагностируется из-за этих недостатков. [2] согласны с тем, что было бы полезно обнаружить патологию БА задолго до того, как кому-то будет поставлен диагноз, чтобы внедрить вторичную профилактику.
Поможет ли анализ речи?
Как неоднократно упоминалось в приведенном выше обзоре деменции, известно, что на язык влияют различные признаки, такие как борьба с поиском слов, трудности с пониманием и повторение. [3] указывает, что язык в значительной степени зависит от памяти, и по этой причине один из самых ранних признаков БА может быть в речи человека.
[2] усиливает этот момент, подчеркивая тот факт, что для успешного общения человек должен уметь принимать сложные решения, планировать стратегию, предвидеть последствия и решать проблемы. Все они ухудшаются по мере прогрессирования деменции.
На практике [2] заявляет, что речь легко усваивается и извлекается, поэтому они (вместе с [1], [3] и [4]) предлагают использовать речь для диагностики деменции с помощью экономически эффективных, не требующих больших затрат средств. инвазивным и своевременным образом.
Чтобы начать расследование, нам нужны данные.
Наборы данных
Как вы понимаете, нелегко собрать подходящие наборы данных для изучения этого. По этой причине [1], [3] и [4] использовали тот же набор данных из DementiaBank (репозиторий в TalkBank) под названием Pitt Corpus. Этот корпус содержит аудио и записи людей с БА и здоровых пожилых людей из контрольной группы.
Чтобы вызвать речь, участников (обе группы) попросили описать фотографию стимула Cookie Theft:

У некоторых участников было несколько посещений, поэтому [1], [3] и [4] имели аудиозаписи и транскрипции для 223 контрольных интервью и 234 интервью AD (эти числа немного различаются между ними из-за предварительной обработки, я полагаю).
[1] указывает, что задача описания изображения обеспечивает управление словарным запасом и вызванной речью в контексте, но [2] хотел исследовать другой тип речи.
Вместо повествования или речи с описанием картинок [2] для создания своих моделей использовали данные спонтанного разговора из Коллекции разговоров Каролины (CCC).
Корпус содержит 21 интервью с пациентами с БА и 17 диалогов с контрольными пациентами. Эти пациенты из контрольной группы страдали другими заболеваниями, такими как диабет, проблемы с сердцем и т. Д. Однако ни у кого из них не было нейропсихологических заболеваний.
Автоматическое обнаружение AD, разработанное [2], было первым использованием данных низкоуровневого диалогового взаимодействия в качестве основы для обнаружения AD на спонтанной разговорной речи.
Модели
Если я хочу построить более естественную систему общения, то я должен знать о заметных различиях в речи людей с деменцией и здоровых людей из контрольной группы. Какие особенности информируют модели в этих статьях, должны указывать именно на это.
[1] извлеченные функции, на которые, как известно, влияет AD (я подробно расскажу о функциях в следующем разделе, так как это мой основной интерес). Они собрали множество функций на основе транскрипции и акустических характеристик, прежде чем использовать анализ главных компонентов (PCA), чтобы уменьшить общее количество функций для тренировки. Используя выбранные функции, они обучили KNN и SVM достижению F1 0,73 и, что важно, отзыв 0,83 в качестве ложноотрицательных результатов может быть опасным.
[2] решили полагаться только на функции без содержания, включая скорость речи, очередность и другие параметры. Они обнаружили, что когда они использовали шаблоны скорости речи и очередности для обучения алгоритма Real AdaBoost, они достигли точности 86,5%, а добавление дополнительных функций уменьшило количество ложных срабатываний. Они обнаружили, что другие модели работают сравнительно хорошо, но даже несмотря на то, что Real AdaDoost и деревья решений достигли точности 86,5%, они говорят, что еще есть возможности для улучшения.
Следует особо отметить [2] их высокую точность (сравнимую с современными технологиями), несмотря на то, что они полагаются только на функции без содержания. Таким образом, их модель может использоваться глобально, поскольку функции не зависят от языка, в отличие от более сложных лексических, синтаксических и семантических функций, используемых в других моделях.

[3] выполнял выделение признаков, выбор признаков и затем классификацию. В корпус записано много синтаксических, семантических и прагматических особенностей. Они испробовали три метода выбора функций, а именно: получение информации, KNN и устранение рекурсивных функций SVM. Этот шаг выбора функции особенно интересен для моего проекта. Используя функции, выбранные KNN, их наиболее точной моделью была SVM, которая достигла точности 79%.
[4] представляет совершенно другой (и более интересный) подход, чем в других статьях, поскольку они строят сеть консенсуса (CN).
Поскольку [4] использует тот же корпус, что и [1] и [3], наступает момент, когда единственные два способа улучшить предыдущие классификаторы - это либо добавить больше данных, либо вычислить больше функций. Конечно, у обоих этих вариантов есть ограничения, поэтому [4] использует новый подход.
Сначала они разделили извлеченные признаки на неперекрывающиеся подмножества и обнаружили, что три естественных группы (акустическая, синтаксическая и семантическая) дали наилучшие результаты.
185 акустических функций, 117 синтаксических функций и 31 семантическая функция (плюс 80 POS-функций, которые были в основном семантическими) были использованы для обучения трех отдельных нейронных сетей, называемых «ePhysician»:

Каждый ePhysician представляет собой полностью подключенную сеть с десятью скрытыми уровнями, активациями Leaky ReLU и пакетной нормализацией. И классификатор, и дискриминатор были одинаковыми, но без каких-либо скрытых слоев.
Выходные данные каждого электронного врача передавались один за другим в дискриминатор (с шумом), а затем он пытался отличить электронных врачей друг от друга. Это побуждает электронных врачей выводить неотличимые друг от друга представления (согласитесь).
[4] действительно обнаружили, что их CN с тремя естественными и неперекрывающимися подмножествами функций превосходит другие модели с макросом F1 0,7998. Кроме того, [4] показал, что включение шума и совместной оптимизации действительно способствовало повышению производительности.
В случае возникновения путаницы, важно повторить, что [2] использовал другой корпус.
В каждой статье, особенно в [4], их модель, конечно же, описывается более подробно. Меня не интересуют в первую очередь сами модели, так как я не собираюсь диагностировать деменцию. Моя основная цель в этой статье - выяснить, какие функции использовались для обучения этих моделей, так как мне придется обратить внимание на те же функции.
Важные языковые особенности
Чтобы разговорная система работала более естественно для людей с когнитивными нарушениями, необходимо исследовать языковые изменения.
[4] отправили все функции своим врачам-специалистам по электронной медицине, поэтому не уточнили, какие функции были наиболее предсказуемыми. Они упомянули, что соотношение местоимений и существительных, как известно, меняется, поскольку люди с когнитивными нарушениями используют больше местоимений, чем существительных.
[2], что интересно, достигли отличных результатов, используя только скорость речи человека и его очередность. Они действительно получали меньше ложных срабатываний, добавляя другие функции, но, как уже упоминалось, придерживались функций без содержания. Это означает, что их модель не зависит от конкретного языка и, следовательно, может использоваться в глобальном масштабе.
[1] извлекли признаки, которые, как известно, подвержены влиянию AD, и дополнительно отметили, что словарный запас пациентов и семантическая обработка снизились.
[1] перечислены следующие функции на основе транскрипции:
- Лексическое богатство
- Длина высказывания
- Частота слов-заполнителей
- Частота местоимений
- Частота глаголов
- Частота употребления прилагательных
- Частота имен собственных
и [1] перечислили следующие акустические особенности:
- Ошибки при поиске слов
- Текучесть
- Ритм речи
- Частота паузы
- Продолжительность
- Скорость речи
- Скорость артикуляции
Блестяще, [3] выполнил несколько методов выбора признаков по следующим признакам:

Для всех этих функций они реализовали три метода выбора функций для выбора каждой из восьми основных функций: получение информации, KNN и устранение рекурсивных функций SVM (SVM-RFE).
Они выводят следующее:

Всеми тремя методами были выбраны три характеристики, что позволяет предположить, что они очень предсказуемы для обнаружения AD: ошибки в словах, количество предлогов и количество повторений.
Также важно повторить, что наиболее точная модель использовала функции, выбранные методом KNN.
В целом, в этом разделе выделено множество функций, на которые следует обратить внимание. В частности, однако (как из четырех статей, так и из видеороликов Общества Альцгеймера) нам необходимо обратить особое внимание на:
- Ошибки в словах
- Повторение
- Соотношение местоимений и существительных
- Количество предлогов
- Скорость речи
- Частота паузы
Заключение
Ранее мы изучали текущее исследование сделать диалоговые системы более естественными, и теперь у нас есть относительно короткий список функций, которые необходимо обрабатывать, чтобы диалоговые системы работали плавно, даже если у пользователя есть когнитивные нарушения, такие как AD. .
Конечно, это не исчерпывающий список, но это хорошее место для начала и указывает мне правильное направление, над чем работать дальше. Будьте на связи!
Примечание редактора. Heartbeat - это онлайн-публикация и сообщество, созданное авторами и посвященное предоставлению первоклассных образовательных ресурсов для специалистов по науке о данных, машинному обучению и глубокому обучению. Мы стремимся поддерживать и вдохновлять разработчиков и инженеров из всех слоев общества.
Являясь независимой редакцией, Heartbeat спонсируется и публикуется Comet, платформой MLOps, которая позволяет специалистам по данным и группам машинного обучения отслеживать, сравнивать, объяснять и оптимизировать свои эксперименты. Мы платим участникам и не продаем рекламу.
Если вы хотите внести свой вклад, отправляйтесь на наш призыв к участникам. Вы также можете подписаться на наши еженедельные информационные бюллетени (Deep Learning Weekly и Comet Newsletter), присоединиться к нам в » «Slack и подписаться на Comet в Twitter и LinkedIn для получения ресурсов, событий и гораздо больше, что поможет вам быстрее создавать лучшие модели машинного обучения.