
Оптимизация - самый важный ингредиент в рецепте алгоритмов машинного обучения. Он начинается с определения какой-то функции потерь / функции стоимости и заканчивается ее минимизацией с помощью той или иной процедуры оптимизации. Выбор алгоритма оптимизации может иметь значение для получения хорошей точности в часах или днях. Возможности оптимизации безграничны, и эта тема широко исследуется как в промышленности, так и в академических кругах. В этой статье мы рассмотрим несколько алгоритмов оптимизации, используемых в сфере глубокого обучения. (Вы можете просмотреть эту статью, чтобы понять основы функций потерь)
Стохастический градиентный спуск
Стохастический градиентный спуск (SGD) - это простейший алгоритм оптимизации, используемый для поиска параметров, которые минимизируют заданную функцию стоимости. Очевидно, чтобы градиентный спуск сходился к оптимальному минимуму, функция стоимости должна быть выпуклой. Для демонстрации представьте следующее графическое представление функции стоимости.

Начнем с определения случайных начальных значений параметров. Цель алгоритма оптимизации - найти значения параметров, которые соответствуют минимальному значению функции стоимости. В частности, градиентный спуск начинается с вычисления градиентов (производных) для каждого параметра по функции стоимости. Эти градиенты дают нам числовую корректировку, которую необходимо внести в каждый параметр, чтобы минимизировать функцию стоимости. Этот процесс продолжается до тех пор, пока мы не достигнем локального / глобального минимума (функция стоимости минимальна относительно окружающих значений). Математически,
for i in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
params -= learning_rate * param_gradients

Скорость обучения определяет, сколько параметров должно изменяться на каждой итерации. Другими словами, он контролирует, насколько быстро или медленно мы должны сойтись к минимуму. С одной стороны, небольшая скорость обучения может потребовать итераций для схождения, большая скорость обучения может превышать минимум, как вы можете видеть на рисунке выше.
Несмотря на то, что он достаточно прост в применении на практике, он имеет немало недостатков, когда дело доходит до глубоких нейронных сетей, поскольку эти сети имеют большое количество параметров, которые нужно уместить. Чтобы проиллюстрировать проблемы с градиентным спуском, давайте предположим, что у нас есть функция стоимости только с двумя параметрами. . Предположим, что функция стоимости очень чувствительна к изменениям одного из параметров, например, в вертикальном направлении, и менее чувствительна к другому параметру, например, в горизонтальном направлении (это означает, что функция стоимости имеет высокое число условий).

Если мы запустим для этой функции стохастический градиентный спуск, мы получим своего рода зигзагообразное поведение. По сути, SGD медленно продвигается в сторону менее чувствительного направления и больше - в сторону высокочувствительного и, следовательно, не выравнивается в направлении минимума. На практике глубокая нейронная сеть может иметь миллионы параметров и, следовательно, миллионы направлений для корректировки градиента и, следовательно, усугубления проблемы.
Еще одна проблема с SGD - проблема локального минимума или седловых точек. Седловые точки - это точки, в которых градиент равен нулю во всех направлениях. Следовательно, наш SGD застрянет только там. С другой стороны, локальные минимумы - это точки, которые минимальны относительно окружающей среды, но не минимальны в целом. Поскольку градиент будет равен нулю в локальном минимуме, наш градиентный спуск будет сообщать его как минимальное значение, когда глобальный минимум находится где-то еще.
Чтобы исправить проблемы с ванильным градиентным спуском, в последние годы было разработано несколько усовершенствованных алгоритмов оптимизации. Мы будем просматривать их по очереди.
Стохастический градиентный спуск с импульсом
Чтобы понять динамику расширенных оптимизаций, мы сначала должны понять концепцию экспоненциально взвешенного среднего. Предположим, нам даны данные о дневных температурах в каком-либо конкретном городе за все 365 дней в году. Построив его, мы получим график в верхнем левом углу.

Теперь, если мы хотим рассчитать среднюю местную температуру в течение года, поступим следующим образом.
NOTE :-
alpha = 0.9 is randomly chosen weight.
t(i) is temperature at ith day.
v(i) is average temperature for ith day averaged over 1/(1 - alpha) days.
v(0) = 0
v(1) = 0.9 * v(0) + 0.1 * t(1)
v(2) = 0.9 * v(1) + 0.1 * t(2)
...
v(i) = alpha * v(i-1) + (1 - alpha) * t(i)
Каждый день мы вычисляем средневзвешенное значение температуры предыдущего дня и температуры текущего дня. График для вышеуказанного вычисления показан в верхнем правом углу. На этом графике показана средняя температура за последние 10 дней (альфа = 0,9). Слева внизу (зеленая линия) показаны усредненные данные графика за последние 50 дней (альфа = 0,98).
Здесь важно отметить, что поскольку мы усредняем большее количество дней, график станет менее чувствительным к изменениям температуры. Напротив, если мы усредним за меньшее количество дней, график будет более чувствительным к изменениям температуры и, следовательно, к изгибному поведению.
Это увеличение задержки связано с тем, что мы придаем больший вес температуре предыдущим дневным температурам, чем текущей дневной температуре.
Пока все хорошо, но вопрос в том, что все это нам дает. Точно так же, усредняя градиенты по нескольким прошлым значениям, мы стремимся уменьшить колебания в более чувствительном направлении и, следовательно, ускорить их схождение.
На практике алгоритмы оптимизации на основе импульса почти всегда быстрее, чем обычный градиентный спуск. Математически,
moment = 0
for i in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
moment = gamma * moment + param_gradients
params += learning_rate * moment
(where moment is building moving average of gradients.
gamma gives kind of friction = 0.9 or 0.99).
Оптимизация AdaGrad
Идея состоит в том, что для каждого параметра мы храним сумму квадратов всех его исторических градиентов. Эта сумма позже используется для увеличения скорости обучения.
Обратите внимание, что, в отличие от предыдущих оптимизаций, здесь у нас разная скорость обучения для каждого параметра.
squared_gradients = 0
for i in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
squared_gradients += param_gradients * param_gradients
params -= learning_rate * param_gradients/
(np.sqrt(squared_gradients) + 1e-8)
{1e-8 is to avoid divide by zero}
Теперь вопрос в том, как это масштабирование помогает нам, когда у нас очень большое число обусловленности для нашей функции потерь?
Для параметров с высокими значениями градиента квадратный член будет большим, и, следовательно, деление на большой член приведет к медленному ускорению градиента в этом направлении. Точно так же параметры с низкими градиентами будут давать меньшие квадраты членов, и, следовательно, градиент будет ускоряться быстрее в этом направлении.
Однако обратите внимание, что, поскольку градиент возводится в квадрат на каждом шаге, скользящая оценка будет монотонно расти с течением времени, и, следовательно, размер шага, который наш алгоритм будет принимать для схождения к минимуму, будет становиться все меньше и меньше.
И в известном смысле это выгодно для выпуклых задач, так как в этом случае ожидается замедление до минимума. Однако этот же подарок становится проклятием в случае проблем с невыпуклой оптимизацией, так как увеличивается шанс застрять в седловых точках.
Оптимизация RMSProp
Это небольшая разновидность AdaGrad, которая лучше работает на практике, поскольку решает оставленные им проблемы. Подобно AdaGrad, здесь мы также сохраним оценку квадрата градиента, но вместо того, чтобы позволять этой оценке в квадрате накапливаться во время обучения, мы скорее позволим этой оценке постепенно уменьшаться. Для этого мы умножаем текущую оценку квадратов градиентов на скорость затухания.
squared_gradients = 0
for i in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
squared_gradients = decay_rate * squared_gradients + (1 -
decay_rate) * param_gradients * param_gradients
params -= learning_rate * param_gradients/
(np.sqrt(squared_gradients) + 1e-8)
Адам
Он включает в себя все прекрасные функции RMSProp и градиентного спуска с импульсом.
В частности, этот алгоритм вычисляет экспоненциальное скользящее среднее градиентов и квадратов градиентов, тогда как параметры beta_1 и beta_2 контролируют скорость затухания этих скользящих средних.
first_moment = 0
second_moment = 0
for step in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
first_moment = beta_1 * first_moment + (1 - beta_1) *
param_gradients
second_moment = beta_2 * second_moment + (1 - beta_2) *
param_gradients * param_gradients
params -= learning_rate * first_moment/(np.sqrt(second_moment) +
1e-8)
Обратите внимание, что мы инициализировали second_moment равным нулю. Итак, вначале second_moment будет рассчитываться как нечто очень близкое к нулю. Следовательно, мы обновляем параметры путем деления на очень маленькое число и, следовательно, делаем большие обновления параметра. Это означает, что изначально алгоритм будет делать большие шаги. Чтобы исправить это, мы создаем беспристрастную оценку первого и второго момента, включая текущий шаг. А затем мы обновляем параметры, основываясь на этих объективных оценках, а не на первом и втором моментах. Математически,
first_moment = 0
second_moment = 0
for step in range(iterations_count):
param_gradients = evaluate_gradients(loss_function,
data,
params)
first_moment = beta_1 * first_moment + (1 - beta_1) *
param_gradients
second_moment = beta_2 * second_moment + (1 - beta_2) *
param_gradients * param_gradients
first_bias_correction = first_moment/(1 - beta_1 ** step)
second_bias_correction = second_moment/(1 - beta_2 ** step)
params -= learning_rate * first_bias_correction/
(np.sqrt(second_bias_correction) + 1e-8)
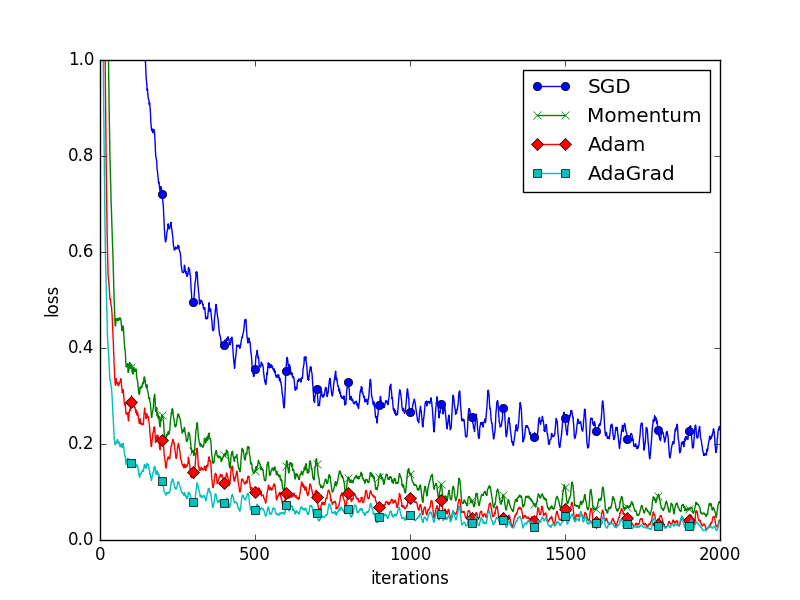
На рисунке ниже показана производительность каждого алгоритма оптимизации по мере прохождения итераций. Ясно, что добавление импульса повышает точность. На практике, однако, известно, что Адам очень хорошо работает с большими наборами данных и сложными функциями.
Ресурсы
RMSprop - Алгоритмы оптимизации | Coursera
Этот курс научит вас «волшебству заставить глубокое обучение работать хорошо. Вместо процесса глубокого обучения… www.coursera.org »
Вы можете найти this для получения более подробной математической информации. Сообщите мне через свои комментарии о любых изменениях / улучшениях, которые могут быть внесены в эту статью.