В этом блоге я объясню, как структурировать проект машинного обучения и некоторые полезные методы для глубокого обучения, такие как трансферное обучение, многозадачность и сквозное обучение.
В предыдущем блоге я упоминал, сколько стратегий и параметров задействовано в проекте машинного обучения. В частности, когда мы хотим оптимизировать результаты нашего алгоритма, у нас есть несколько вариантов, таких как:
- Соберите больше данных
- Иметь более разнообразный тренировочный набор
- Увеличьте количество итераций
- Измените алгоритм оптимизации, например Adam, RMSprop, ..
- Изменить тип сети
- Добавить регуляризацию
- Изменить сетевую архитектуру
Это может быть пугающе, особенно потому, что сделать один шаг - значит потратить время только на то, чтобы понять, что это был не лучший выбор для начала.
Нам нужен быстрый совет о том, какую идею стоит реализовать. То есть, какую ручку мы хотим повернуть для достижения определенного эффекта. (Это то, что они называют «ортогонализацией», что само по себе звучит устрашающе!)
Начнем по порядку.
При работе над проектом машинного обучения первое, что нам нужно, - это хорошая производительность на обучающем наборе (для некоторых приложений, таких как распознавание изображений, это может означать достижение производительности на уровне человека). Затем переходите к исправлению набора разработчиков, набора тестов и, наконец, хорошо работайте в реальном мире.
Итак, вот что мы можем настроить, чтобы улучшить каждый из этих шагов:
- для обучающего набора:
- использовать большую сеть
- изменить алгоритм оптимизации (например, Адам)
- для набора dev:
- использовать регуляризацию
- собрать больше данных
- для набора test:
- если что-то не так с тестовым набором, нам, возможно, придется пересмотреть набор разработчика, так как мы могли его перенастроить.
- для реального мира:
- если здесь что-то пойдет не так, то, возможно, распределение разработчика и набора тестов может быть неправильным.
- или функция стоимости может быть неправильной
Вы можете спросить: «Как мне узнать, что все идет хорошо?»
Спасибо за вопрос! Да, верно, нам нужна метрика, чтобы оценивать вещи!
В опубликованной литературе вы можете прочитать, что для оценки эффективности классификатора вы смотрите на два оценочных показателя: точность и отзыв.
Напомним себе, что они из себя представляют.
Например, возьмем классификатор распознавания образов для кошек.
Точность в этом случае измеряет, какой процент примеров, признанных кошками, на самом деле являются кошками. Напоминание, с другой стороны, сообщает нам, какой процент настоящих кошек правильно отнесены к кошкам.
Проблема использования обоих этих показателей оценки заключается в том, что трудно определить, какой классификатор работает лучше. У одного могли быть лучшие результаты в отношении точности, а у другого - в отношении отзыва.
Разве не было бы лучше, если бы у нас была только одна метрика оценки? Может быть, тот, который сочетает в себе два? Раз уж вы спросили… да! F1-score делает это за нас! По сути, это среднее значение точности (P) и отзыва (R), которое рассчитывается как:

Иногда мы хотим учитывать и другие метрики (например, время работы), и поэтому одной метрики оценки недостаточно. В тех ситуациях, когда у нас есть несколько показателей, мы можем определить один из них как оптимизирующий, а остальные считать «удовлетворительным». Последнее, по сути, является «достаточно хорошим» значением, которому мы должны удовлетворять.
Например, мы хотим, чтобы алгоритм работал менее 100 мс. В этом случае наша «удовлетворительная» метрика (время выполнения ‹= 100 мсек) отфильтрует все алгоритмы, работающие выше этого времени. Для тех, которые вместо этого работают менее 100 мс. Затем мы рассмотрим другую (оптимизирующую) метрику, чтобы определить, какой алгоритм соответствует нашим требованиям.
Определение метрики для оценки классификатора помогает нам определить цель. Как преуспеть в этой метрике - это прицелиться и выстрелить в эту цель.
Проблема смещения / отклонения
Я упоминал ранее, что для некоторых приложений признание хорошей производительности алгоритма может быть выполнено путем сравнения результатов на человеческом уровне.
Это верно для приложений естественного восприятия, таких как, например, распознавание изображений, но для тех, которые включают много данных и, кроме того, более структурированные данные, даже современные алгоритмы работают лучше, чем люди.
Таким образом, правильным эталоном должна быть «оптимальная ошибка Байеса», которая является наилучшей возможной ошибкой, которую можно получить. В некоторых случаях человеческая ошибка может быть близка к этой, но никогда не превышать ее.
Давайте оценим производительность наших наборов для обучения / разработки, связанных с ошибкой Байеса, и посмотрим, как мы можем определить проблему смещения / дисперсии на следующем примере:

Как мы видим, разница между ошибкой Байеса и обучающей выборкой указывает на проблему, связанную с высоким смещением, в то время как разница между ошибкой обучения и ошибкой набора для разработки связана с проблемой высокой дисперсии. Таким образом, подгонка обучающего набора снижает предотвратимую систематическую ошибку, и когда производительность обучающего набора хорошо обобщается на набор разработчика, мы избегаем высокой дисперсии.
Я упомянул в предыдущем блоге некоторые методы преодоления проблемы смещения / дисперсии, но их стоит повторить.
Чтобы исправить предвзятость:
- обучить более крупную модель
- тренироваться дольше
- использовать лучшие алгоритмы оптимизации (Momentum, Adam, RMSprop)
- различная архитектура нейронной сети / поиск гиперпараметров
Чтобы исправить расхождение:
- собрать больше данных
- использовать регуляризацию (L2, отсев, увеличение данных)
- различная архитектура нейронной сети / поиск гиперпараметров
Приведенный выше анализ смещения / ошибок действителен только в том случае, если наборы для обучения и разработки / тестирования происходят из одного и того же распределения.
С другой стороны, если бы мы анализировали тот же разрыв ошибок, что и выше (ошибка обучения 8,0% и ошибка набора разработчика 12%), мы больше не могли бы с уверенностью сказать, что на модель повлияла высокая дисперсия, потому что теперь есть две вещи. :
- алгоритм увидел данные в обучающем наборе, который отличается от набора разработчика
- распределение данных отличается
К счастью, у нас есть возможность это исправить!
Нам нужно создать новое подмножество данных (называемое набором «обучение-разработчик»), которое является частью обучающего набора (поэтому оно имеет такое же распределение обучающего набора), но не используется для обучения.

Таким образом, мы можем различить проблему, связанную с различным распределением по разным данным, и можем соответствующим образом проанализировать ошибки.

Думаю, стоит упомянуть, как устранить несоответствие данных.
К сожалению, систематических способов сделать это не существует. Однако вот пара рекомендаций:
- выполнить ручной анализ ошибок, чтобы понять разницу между обучающими наборами и наборами для разработки / тестирования.
- сделайте обучающие данные более похожими или соберите данные, похожие на наборы для разработки / тестирования. Например, в системе распознавания голоса, если наборы для разработки / тестирования имеют фоновый шум, а обучающие данные представляют собой чистый звук, мы можем использовать «искусственный синтез данных», чтобы добавить фоновый шум к звуку.
________________________________
В следующем разделе я коснусь некоторых аспектов обучения, которые могут быть реализованы при работе над проектом глубокого обучения:
- Передача обучения
- Многозадачное обучение
- Сквозное глубокое обучение
ПЕРЕДАЧА ОБУЧЕНИЯ
В некотором смысле это похоже на то, как люди собирают знания: учатся на одной задаче и применяют ее к другим.
Чтобы быть более конкретным, для нейронной сети мы удаляем последний выходной слой и его веса и заменяем их новым слоем (или даже несколькими новыми слоями), а также новым набором случайно инициализированных весов для последней части сеть.
На этом этапе мы можем переобучить новую сеть на новом наборе данных.
Чтобы быть более точным, нам нужно различать два случая: новый небольшой набор данных или новый большой набор данных. В первой ситуации мы повторно тренируем веса только последнего слоя, а остальные параметры оставляем неизменными. Это называется «точной настройкой».
С другой стороны, применяя трансферное обучение к новому большому набору данных, мы повторно обучаем все параметры сети.
Если мы пытаемся научиться от задачи A к B, то трансферное обучение имеет смысл, если:
- Задачи A и B имеют одинаковые входные данные.
- Для задачи А у нас гораздо больше данных, чем для задачи Б.
- Низкоуровневые функции из A могут быть полезны при обучении задаче B.
Например, у нас может быть много данных, взятых для распознавания изображений. Мы можем использовать эту обученную сеть как «трансферное обучение» для распознавания рентгеновских лучей, где вместо этого у нас не так много изображений, чтобы можно было обучить сеть с нуля.
МНОГОЗАДАЧНОЕ ОБУЧЕНИЕ
Мы видели, как в трансферном обучении у нас есть последовательный процесс от A к B. Вместо этого в многозадачном обучении мы начинаем с одной нейронной сети, пытающейся одновременно делать несколько вещей одновременно. Каждая из этих задач также помогает другим задачам.
Одним из примеров многозадачного обучения является обучение нейронной сети распознаванию нескольких объектов на изображении, таких как распознавание пешеходов, автомобилей, знаков остановки и светофоров.
В этом случае вывод будет делиться на 4 категории:

где Y может быть:
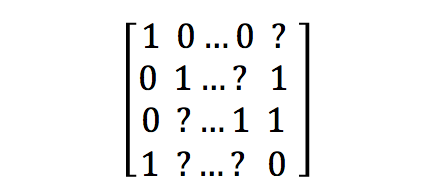
(Знак вопроса будет помещен в такое положение, когда он не сможет идентифицировать этот конкретный объект).
Затем потери (для всего обучающего набора m) будут рассчитаны по значениям выходных данных (4 в этом примере):

Таким образом, для каждого изображения выходные данные сети говорят нам, содержит ли изображение пешеход / автомобиль / знак остановки / светофор.
Вы можете спросить себя, а нельзя ли обучить четыре отдельных сети?
Да, мог бы. Но если некоторые из более ранних функций нейронной сети могут быть общими для этих разных типов объектов, то обучение одной нейронной сети для выполнения четырех действий приводит к более высокой производительности, чем обучение четырех отдельных сетей для выполнения четырех отдельных задач.
Многозадачное обучение имеет смысл, когда:
- Мы тренируемся по набору задач, которые могут выиграть от общих функций нижнего уровня.
- Количество данных, которые у нас есть для каждой задачи, очень похоже.
- Мы можем обучаться в достаточно большой сети, которая хорошо справляется со всеми задачами.
С другой стороны, если сеть недостаточно велика, лучше использовать отдельные нейронные сети. Наконец, многозадачное обучение используется не слишком часто, за исключением приложений, связанных с обнаружением объектов. Напротив, более широко используется трансферное обучение.
ПОСТОЯННОЕ ОБУЧЕНИЕ
Некоторые обучающие системы требуют нескольких этапов обработки. Напротив, сквозное обучение берет все эти несколько этапов и заменяет их одной нейронной сетью.
Этот тип обучения - один из самых недавних, и его иногда называют «черным ящиком», поскольку мы не обрабатываем данные заранее, а позволяем сети разобраться во всем самостоятельно.
Чтобы понять, что я имею в виду, давайте рассмотрим несколько примеров.
- Распознавание речи:
При многоэтапном подходе процесс будет следующим:
X (аудио) - ›особенности -› фонемы - ›слова -› Y (расшифровка)
А сквозной метод вместо этого передает аудио и получает транскрипты напрямую:
X (аудио) - ›Y (расшифровка)
- Распознавание лиц:
Многоступенчатый подход:
X (изображение) - ›обнаружение лица -› масштабирование и кадрирование - ›кадрированное изображение, загруженное в NN -› Y (обнаружение)
Концы с концами:
X (изображение) - ›Y (обнаружение)
При применении сквозного обучения ключевым моментом является наличие большого количества данных для сети, чтобы изучить функцию сложности, необходимую для отображения X в Y.
Плюсы этого метода:
- Пусть данные говорят (вместо того, чтобы иметь человеческие «предубеждения». Например, мы видели ранее, что при распознавании речи одним из шагов является создание фонем. Этот шаг оказался ненужным для распознавания звука.
- Требуется меньше «ручного проектирования» компонентов.
Минусы:
- Нам нужен большой объем данных.
- Он исключает потенциально полезные компоненты, разработанные вручную (в частности, когда у нас недостаточно данных, на основе которых сеть может получить ценную информацию. Что-то вроде палки о двух концах, а?)
Этот блог основан на лекциях Эндрю Нг на DeepLearning.ai