Давайте начнем с того, что означает алгоритм и что он может сделать для кода, который мы пишем на любом из языков.

Что ж, алгоритм можно определить так: «В математике и информатике алгоритм — это недвусмысленная спецификация того, как решать класс задач. Алгоритмы могут выполнять вычисления, обработку данных и автоматические логические задачи», или, говоря простым языком, это можно интерпретировать как «алгоритм — это компьютерная процедура, которая во многом похожа на рецепт (называемый процедурой) и сообщает ваш компьютер точно, какие шаги нужно предпринять, чтобы решить проблему или достичь цели. Ингредиенты называются входами, а результаты — выходами».
ЧТО ТАКОЕ АЛГОРИТМЫ МАШИННОГО ОБУЧЕНИЯ? ? ? ? ? ?
Ну, в основном алгоритмы машинного обучения также похожи на общие типы алгоритмов, которые мы видим в нашей повседневной жизни, например, алгоритм вождения автомобиля может быть таким: A. возьмите ключи от машины B. Проверьте топливо в машине ( или электричество, если у вас есть Tesla) C. Пристегните ремень безопасности. D. Наконец, запустите двигатель. Точно так же алгоритм машинного обучения можно изобразить в нескольких типах случаев, основываясь на способности машин понимать, чему мы пытаемся их научить.
В этом посте мы увидим три типа алгоритмов и их подкатегории:
В целом алгоритмы машинного обучения делятся на три типа:

- Контролируемое обучение
- Обучение без учителя
- Обучение с подкреплением
И. ОБУЧЕНИЕ С КОНТРОЛЕМ:
Обучение с учителем — это то, что можно выразить как обучение, управляемое задачами. Здесь машина учится на предыдущих типах выборочных входных данных и выборочных выходных данных и пытается узнать как можно больше, чтобы попытаться предсказать новый набор примеров, когда он будет показан.
Реальный пример сделает вас кристально ясным по этой теме:
Вам дан набор данных, который отображается следующим образом.
Кстати, как специалист по данным или инженер по машинному обучению, мы всегда будем работать с файлами типа .csv (значения, разделенные запятыми) или файлами типа excel почти в большинстве случаев, так что промойте руки в Excel .

Наш набор данных выглядит как на изображении выше, где у нас есть две строки A и B.
- A-› Многолетний опыт
- Б -> Зарплата
Итак, наша проблема здесь состоит в том, чтобы заставить нашу модель машинного обучения использовать любой из алгоритмов, чтобы заставить ее учиться, чтобы, когда мы придаем ей новое значение, мы могли получить прогнозируемый результат.
Поскольку вход A и выход B даны нам в задаче, это будет тип обучения с учителем.
Известные алгоритмы контролируемого обучения:
- Регрессия
- Деревья
- Случайный лес
- Классификация
2. Неконтролируемое обучение:
Предположим, что вам даны только входные данные, и это все, что вам нужно, чтобы найти некоторые закономерности из входных данных или, в терминах ML, кластеры из входных данных, и они делают прогноз в соответствии с ними, что ж, это неконтролируемое обучение.
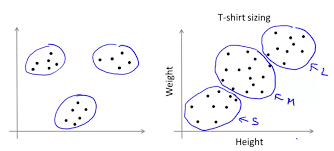
Как вы могли видеть на рисунке выше, мы формируем три кластера в зависимости от нашего набора входных данных. В этом случае нам дается куча одежды, которую необходимо разделить по размерам: маленький (S), средний (M), большой (L). Мы формируем три кластера, чтобы сгруппировать их, и когда мы получаем футболку размера X, для которой мы хотим предсказать размер, в который она поместится, мы можем легко сопоставить их координаты и сгруппировать их в соответствии с их типом кластера. подойдет.
Типичный набор данных для задачи обучения без учителя будет выглядеть следующим образом:

У нас есть задача, в которой нам нужно сгруппировать различные типы клиентов на основе их оценки расходов в определенном торговом центре.
Обычно используемые неконтролируемые алгоритмы:
- кластеризация k-средних
- Иерархическая кластеризация
3. Обучение с подкреплением:
Согласно Википедии, «Обучение с подкреплением — это область машинного обучения, вдохновленная бихевиористской психологией и связанная с тем, как программные агенты должны выполнять действия в среде, чтобы максимизировать некоторое понятие совокупного вознаграждения».
Обучение в основном работает с концепцией следа и ошибки, когда каждый раз, когда данные изучаются на примере, в зависимости от его вознаграждения или наказания наша модель становится очень точной.

Одним из примеров в реальном времени является то, как alpha go использовала обучение с подкреплением, чтобы обучить свою модель победе над чемпионом мира по GO.

Набор данных для обучения с подкреплением будет выглядеть следующим образом:

Нам дается набор данных для проверки вероятности того, что пользователь нажмет на конкретное объявление или нет.
Общие алгоритмы:
- UCB (верхняя доверительная граница)
- Выборка Томпсона
Мы подошли к концу блога. Поздравляем с изучением трех алгоритмов, которые служат основой для машинного обучения.
Поделитесь этим постом, если он вам понравился :)
посетите мой веб-сайт для более интересных статей по AI/DL/DS/ML в очень упрощенной форме https://mytakeondata.wordpress.com/