
Программное обеспечение - это все о логике. Программирование заработало репутацию области, в которой много математики и сумасшедших уравнений. И информатика, кажется, является причиной этого заблуждения.
Конечно, есть немного математики и есть несколько формул, но никому из нас на самом деле не нужно иметь докторскую степень по математике, чтобы понимать, как работают наши машины! Фактически, многие правила и парадигмы, которые мы изучаем в процессе написания кода, являются теми же правилами и парадигмами, которые применимы к сложным концепциям информатики. А иногда эти идеи на самом деле проистекают из информатики, а мы просто никогда об этом не знали.
Независимо от того, какой язык программирования мы используем, когда большинство из нас пишут наш код, мы стремимся инкапсулировать отдельные вещи в классы, объекты или методы, намеренно разделяя то, с чем связаны разные части нашего кода. Другими словами, мы знаем, что, как правило, полезно разделить наш код так, чтобы один класс, объект или метод занимались только одной вещью и отвечали за нее. Если бы мы этого не сделали, все могло бы стать очень беспорядочным и запутанным в сети. Иногда это все же происходит, даже при разделении забот.
Оказывается, даже внутреннее устройство наших компьютеров следует очень схожим конструктивным парадигмам. Например, у нашего компилятора есть разные части, и каждая часть отвечает за обработку одной конкретной части процесса компиляции. С частичкой этого мы столкнулись на прошлой неделе, когда узнали о парсере, который отвечает за создание деревьев синтаксического анализа. Но синтаксическому анализатору нельзя поручить все.
Синтаксическому анализатору нужна помощь его приятелей, и, наконец, нам пора узнать, кто они такие!
Переход к компиляторам
Когда мы недавно узнали о синтаксическом анализе, мы погрузились в грамматику, синтаксис и то, как компилятор реагирует и реагирует на эти вещи в рамках языка программирования. Но мы никогда особо не подчеркивали, что такое компилятор! По мере того, как мы углубляемся во внутреннюю работу процесса компиляции, мы будем много узнавать о дизайне компилятора, поэтому нам жизненно важно понимать, о чем именно мы здесь говорим.
Компиляторы могут показаться пугающими, но их работа на самом деле не слишком сложна для понимания, особенно когда мы разбиваем различные части компилятора на небольшие части.
Но сначала давайте начнем с самого простого определения. компилятор - это программа, которая считывает наш код (или любой код на любом языке программирования) и переводит его на другой язык.

Вообще говоря, компилятор действительно только когда-либо будет переводить код с языка высокого уровня на язык более низкого уровня. Языки нижнего уровня, на которые компилятор переводит код, часто называют кодом сборки, машинным кодом или объектным кодом. Стоит отметить, что большинство программистов на самом деле не работают и не пишут какой-либо машинный код; скорее, мы зависим от компилятора, который берет наши программы и переводит их в машинный код, который наш компьютер будет запускать как исполняемую программу.
Мы можем думать о компиляторах как о посреднике между нами, программистами и нашими компьютерами, которые могут запускать исполняемые программы только на языках нижнего уровня.
Компилятор выполняет работу по преобразованию того, что мы хотим сделать, так, чтобы это было понятно и выполнимо для наших машин.
Без компилятора мы были бы вынуждены связываться с нашими компьютерами путем написания машинного кода, который невероятно нечитаем и трудно расшифровать. Машинный код для человеческого глаза часто может выглядеть как набор нулей и единиц - все это двоичное, помните? - что делает его очень сложным для чтения, записи и отладки. Компилятор абстрагировал машинный код для нас, программистов, потому что он позволял нам не думать о машинном коде и писать программы, используя гораздо более элегантные, ясные и легко читаемые языки.
Мы продолжим раскрывать все больше и больше о загадочном компиляторе в течение следующих нескольких недель, что, надеюсь, сделает его менее загадкой в процессе. Но пока давайте вернемся к текущему вопросу: каковы самые простые возможные части компилятора?
Каждый компилятор, независимо от того, как он может быть спроектирован, имеет отдельные фазы. На этих этапах мы можем различать уникальные части компилятора.

Мы уже столкнулись с одним из этапов наших приключений по компиляции, когда недавно узнали о синтаксическом анализаторе и деревьях синтаксического анализа. Мы знаем, что синтаксический анализ - это процесс получения некоторого ввода и построения из него дерева синтаксического анализа, который иногда называют актом синтаксического анализа . Как оказалось, работа по синтаксическому анализу специфична для этапа процесса компиляции, называемого синтаксическим анализом.
Однако парсер не просто строит дерево синтаксического анализа из воздуха. Есть некоторая помощь! Напомним, что синтаксическому анализатору выдается несколько токенов (также называемых терминалами), и он строит дерево синтаксического анализа из этих токенов. Но откуда у него эти токены? К счастью для парсера, он не должен работать в вакууме; вместо этого у него есть некоторая помощь.
Это подводит нас к другому этапу процесса компиляции, предшествующему этапу синтаксического анализа: этапу лексического анализа.

Термин «лексический» относится к значению слова отдельно от содержащего его предложения и независимо от его грамматического контекста. Если мы попытаемся угадать наше собственное значение, основываясь исключительно на этом определении, мы могли бы постулировать, что фаза лексического анализа имеет отношение к отдельным словам / терминам в самой программе и не имеет ничего общего с грамматикой или значением предложения, которое содержит слова.
Фаза лексического анализа - это первый шаг в процессе компиляции. Он не знает и не заботится о грамматике предложения, значении текста или программы; все, о чем он знает, - это значение самих слов.
Лексический анализ должен произойти до того, как любой код из исходной программы сможет быть проанализирован. Прежде чем программа сможет быть прочитана синтаксическим анализатором, ее необходимо сначала просканировать, разделить и сгруппировать определенным образом.
Когда на прошлой неделе мы начали рассматривать фазу синтаксического анализа, мы узнали, что дерево синтаксического анализа строится путем рассмотрения отдельных частей предложения и разбиения выражений на более простые части. Но на этапе лексического анализа компилятор не знает или не имеет доступа к этим отдельным частям. Скорее, он должен сначала идентифицировать и найти их, а затем выполнить работу по разделению текста на отдельные части.
Например, когда мы читаем предложение Шекспира, такое как To sleep, perchance to dream., мы знаем, что пробелы и знаки препинания разделяют «слова» предложения. Это, конечно, потому, что нас научили читать предложение, «лексировать» его и разбирать на предмет грамматики.
Но для компилятора это же предложение может выглядеть так при первом чтении: Tosleepperhachancetodream. Когда мы читаем это предложение, нам становится труднее определить, что это за «слова» на самом деле! Я уверен, что наш компилятор чувствует то же самое.
Итак, как наша машина справляется с этой проблемой? Что ж, на этапе лексического анализа процесса компиляции он всегда выполняет две важные вещи: он сканирует код, а затем оценивает это.

Работа по сканированию и оценке иногда может быть объединена в одну единую программу, или это могут быть две отдельные программы, которые зависят друг от друга; на самом деле вопрос лишь в том, как был разработан какой-либо один компилятор. Программа в компиляторе, которая отвечает за сканирование и оценку, часто называется лексером или токенизатором. , а весь этап лексического анализа иногда называют процессом лексирования или токенизации.
Для сканирования, возможно, для чтения
Первым из двух основных шагов лексического анализа является сканирование. Мы можем думать о сканировании как о фактическом «чтении» некоторого введенного текста. Помните, что этот вводимый текст может быть строкой, предложением, выражением или даже целой программой! На самом деле это не имеет значения, потому что на этом этапе процесса это просто гигантский кусок символов, который еще ничего не значит, и представляет собой один непрерывный кусок.
Давайте посмотрим на примере, чтобы увидеть, как именно это происходит. Мы будем использовать наше исходное предложение To sleep, perchance to dream., которое является нашим исходным текстом или исходным кодом. Для нашего компилятора этот исходный текст будет считываться как входной текст, который выглядит как Tosleep,perchancetodream., который представляет собой всего лишь строку символов, которую еще предстоит расшифровать.

Первое, что должен сделать наш компилятор, - это фактически разделить этот фрагмент текста на минимально возможные части, что значительно упростит определение того, где на самом деле находятся слова в этом фрагменте текста.
Самый простой способ выделить гигантский кусок текста - это медленно и систематически читать его по одному символу за раз. И это именно то, что делает компилятор.
Часто процесс сканирования обрабатывается отдельной программой, называемой сканером, единственной задачей которой является чтение исходного файла / текста, по одному символу за время. Для нашего сканера не имеет значения, насколько большой наш текст; все, что он увидит, когда «прочитает» наш файл, - это по одному символу за раз.
Вот как наш сканер будет читать нашу шекспировскую фразу:

Мы заметим, что To sleep, perchance to dream. был разделен нашим сканером на отдельные символы. Более того, даже пробелы между словами обрабатываются как символы, как и знаки препинания в нашем предложении. В конце этой последовательности есть также очень интересный символ: eof. Это символ «конец файла», он похож на tab, space и newline. Поскольку наш исходный текст представляет собой всего лишь одно предложение, когда наш сканер доходит до конца файла (в данном случае до конца предложения), он считывает конец файла и рассматривает его как символ.
Итак, на самом деле, когда наш сканер прочитал наш вводимый текст, он интерпретировал его как отдельные символы, что привело к следующему: ["T", "o", space, "s", "l", "e", "e", "p", ",", space, "p", "e", "r", "c", "h", "a", "n", "c", "e", space, "t", "o", space, "d", "r", "e", "a", "m", ".", eof].

Теперь, когда наш сканер прочитал и разделил исходный текст на самые мелкие части, ему будет намного проще определить «слова» в нашем предложении.
Затем сканеру необходимо просмотреть по порядку разбитые символы и определить, какие символы являются частями слова, а какие - нет. Для каждого символа, который считывает сканер, он отмечает строку и положение, в котором этот символ был найден в исходном тексте.
Изображение, показанное здесь, иллюстрирует этот процесс для нашего шекспировского предложения. Мы видим, что наш сканер отмечает строку и столбец для каждого символа в нашем предложении. Мы можем думать о представлении строки и столбца как о матрице или массиве символов.
Напомним, что, поскольку в нашем файле только одна строка, все находится в строке 0. Однако по мере прохождения предложения столбец каждого символа увеличивается. Также стоит отметить, что, поскольку наш сканер считывает spaces, newlines, eof и все знаки препинания как символы, они также появляются в нашей таблице символов!

Как только исходный текст отсканирован и помечен, наш компилятор готов преобразовать эти символы в слова. Поскольку сканер знает не только, где находятся spaces, newlines и eof в файле, но и где они находятся по отношению к другим окружающим их символам, он может сканировать символы и при необходимости разделять их на отдельные строки.
В нашем примере сканер посмотрит символы T, затем o, а затем space. Когда он находит пробел, он разделяет To на собственное слово - простейшую комбинацию символов, возможную до того, как сканер обнаружит пробел.
То же самое и со следующим найденным словом sleep. Однако в этом сценарии он читает s-l-e-e-p, а затем читает ,, знак препинания. Поскольку эта запятая окружена символом (p) и space с обеих сторон, запятая сама по себе считается «словом».
И слово sleep, и знак препинания , называются лексемами, которые представляют собой подстроки исходного текста. Лексема - это группа наименьших возможных последовательностей символов в нашем исходном коде. Лексемы исходного файла считаются отдельными «словами» самого файла. Как только наш сканер закончит чтение отдельных символов нашего файла, он вернет набор лексем, которые выглядят следующим образом: ["To", "sleep", ",", "perchance", "to", "dream", "."].

Обратите внимание, как наш сканер взял на вход кусок текста, который он изначально не мог прочитать, и начал сканировать его по одному символу за раз, одновременно считывая и отмечая его содержимое. Затем он приступил к разделению строки на минимально возможные лексемы, используя пробелы и знаки препинания между символами в качестве разделителей.
Однако, несмотря на всю эту работу, на данном этапе фазы лексического анализа наш сканер ничего не знает об этих словах. Конечно, он разбивал текст на слова разных форм и размеров, но что это за слова, сканер понятия не имеет! Слова могут быть буквальной строкой, или они могут быть знаком препинания, или они могут быть чем-то совершенно другим!
Сканер ничего не знает ни о самих словах, ни о том, к какому «типу» они относятся. Он просто знает, где слова заканчиваются и начинаются в самом тексте.
Это настраивает нас на вторую фазу лексического анализа: оценку. После того, как мы отсканировали наш текст и разбили исходный код на отдельные блоки лексемы, мы должны оценить слова, которые сканер вернул нам, и выяснить, с какими типами слов мы имеем дело - в частности, мы должны искать важные слова, которые означают что-то особенное в языке, который мы пытаемся скомпилировать.
Оценка важных частей
Когда мы закончим сканирование исходного текста и определим наши лексемы, нам нужно будет что-то сделать с нашей лексемой «слова». Это этап оценки лексического анализа, который при разработке компиляторов часто называют процессом лексирования или токенизация нашего ввода.

Когда мы оцениваем наш отсканированный код, все, что мы на самом деле делаем, это более внимательно изучаем каждую из лексем, созданных нашим сканером. Нашему компилятору нужно будет просмотреть каждое слово лексемы и решить, что это за тип слова. Процесс определения лексемы каждого «слова» в нашем тексте - это то, как наш компилятор превращает каждую отдельную лексему в токен, тем самым токенизируя нашу входную строку.
Мы впервые столкнулись с токенами еще тогда, когда изучали деревья синтаксического анализа. Токены - это специальные символы, которые лежат в основе каждого языка программирования. Токены, такие как (, ), +, -, if, else, then, помогают компилятору понять, как разные части выражения и различные элементы связаны друг с другом. Синтаксический анализатор, занимающий центральное место на этапе синтаксического анализа, зависит от получения токенов от где-то, а затем превращает эти токены в дерево синтаксического анализа.

Ну, угадайте, что? Мы наконец-то разобрались в «где-то»! Как оказалось, токены, которые отправляются синтаксическому анализатору, генерируются на этапе лексического анализа токенизатором, также называемым лексером .

Итак, как именно выглядит токен? токен довольно прост и обычно представлен в виде пары, состоящей из имени токена и некоторого значения (которое необязательно).
Например, если мы токенизируем нашу шекспировскую строку, мы получим токены, которые будут в основном строковыми литералами и разделителями. Мы могли бы представить лексему “dream” в виде лексемы, например: <string literal, "dream">. Подобным образом мы могли бы представить лексему . как токен <separator, .>.
Мы заметим, что каждый из этих токенов вообще не изменяет лексему - они просто добавляют к ним дополнительную информацию. Токен - это лексема или лексическая единица с более подробной информацией; в частности, дополнительная информация сообщает нам, с какой категорией токена (с каким типом «слова») мы имеем дело.
Теперь, когда мы токенизировали наше шекспировское предложение, мы видим, что в нашем исходном файле не так много разнообразия типов токенов. В нашем предложении были только строки и знаки препинания - но это только верхушка айсберга! Существует множество других типов «слов», на которые можно разделить лексему.

В приведенной здесь таблице показаны некоторые из наиболее распространенных токенов, которые наш компилятор увидит при чтении исходного файла практически на любом языке программирования. Мы видели примеры literals, который может быть любой строкой, числом или логическим / логическим значением, а также separators, который представляет собой любой тип пунктуации, включая фигурные скобки ({}) и круглые скобки (()).
Однако есть также keywords, термины, зарезервированные в языке (например, if, var, while, return), а также operators, которые работают с аргументами и возвращают некоторое значение (+, -, x, /) . Мы также можем встретить лексемы, которые могут быть обозначены как identifiers, которые обычно представляют собой имена переменных или вещи, написанные пользователем / программистом для ссылки на что-то еще, а также comments, которые могут быть строковыми или блочными комментариями, написанными пользователем.
Наше первоначальное предложение показало нам только два примера токенов. Давайте перепишем наше предложение следующим образом: var toSleep = "to dream";. Как наш компилятор мог бы лексировать эту версию Шекспира?
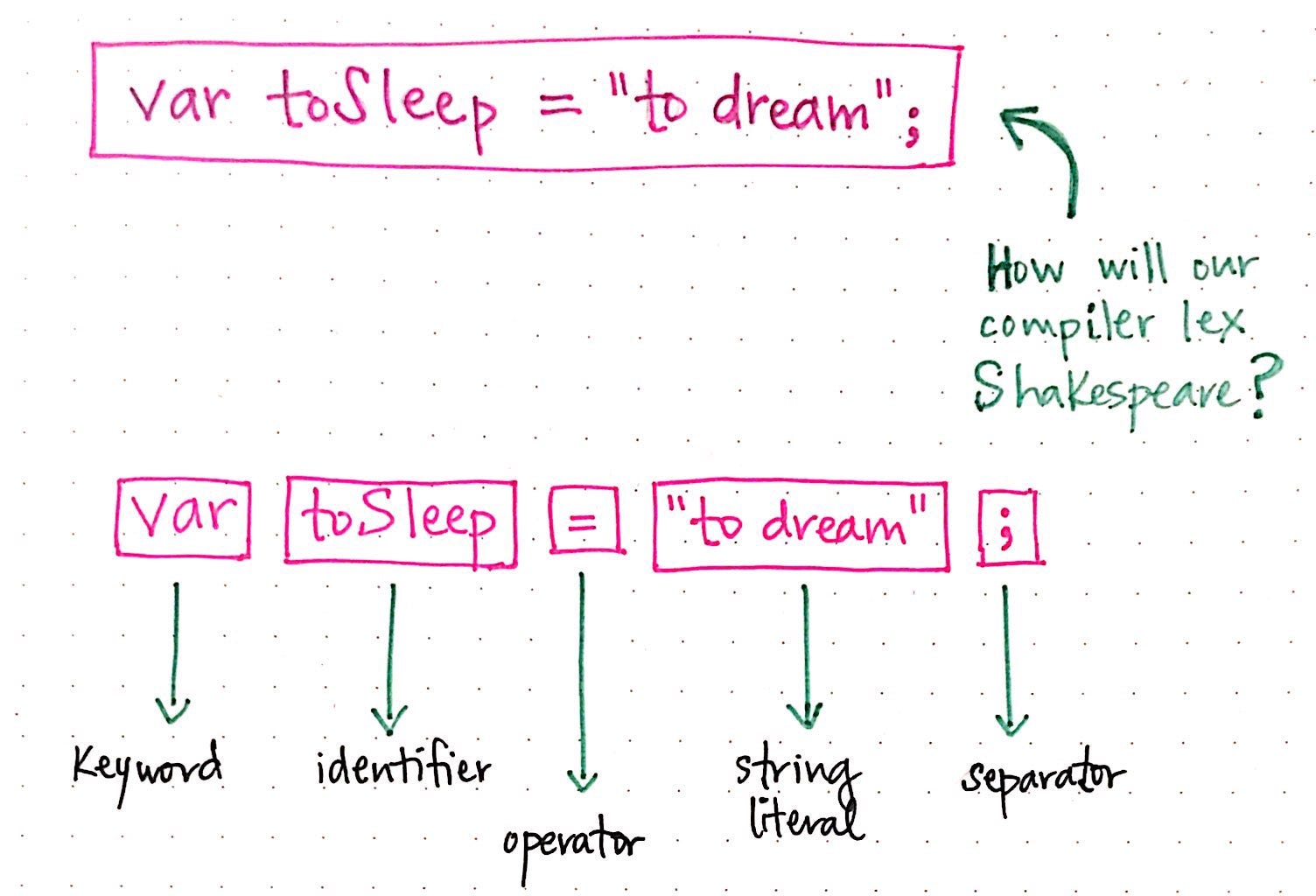
Здесь мы увидим, что у нас больше разнообразных токенов. У нас есть keyword в var, где мы объявляем переменную, и identifier, toSleep, который является способом, которым мы называем нашу переменную или ссылаемся на следующее значение. Далее идет наш =, который представляет собой токен operator, за которым следует строковый литерал "to dream". Наш оператор заканчивается разделителем ;, обозначающим конец строки и ограничивающим пробелы.
Важно отметить, что в процессе токенизации мы не токенизируем пробелы (пробелы, символы новой строки, табуляции, конец строки и т. Д.) И не передаем их синтаксическому анализатору. Помните, что синтаксическому анализатору передаются только токены, которые попадают в дерево синтаксического анализа.
Также стоит отметить, что в разных языках используются разные символы, которые считаются пробелами. Например, в некоторых ситуациях язык программирования Python использует отступы, включая табуляции и пробелы, чтобы указать, как изменяется область действия функции. Таким образом, токенизатор компилятора Python должен учитывать тот факт, что в определенных ситуациях tab или space действительно нужно токенизировать как слово, потому что на самом деле действительно нужно передать в парсер!

Этот аспект токенизатора - хороший способ противопоставить, чем лексер / токенизатор отличается от сканера. В то время как сканер ничего не знает и знает только, как разбить текст на более мелкие возможные части (его «слова»), лексер / токенизатор гораздо более осведомлен и более точен в сравнении.
Токенизатору необходимо знать тонкости и спецификации компилируемого языка. Если tabs важны, он должен это знать; если newlines может иметь определенные значения на компилируемом языке, токенизатор должен знать об этих деталях. С другой стороны, сканер даже не знает, какие слова он разделяет, не говоря уже о том, что они означают.
Сканер компилятора гораздо более независим от языка, в то время как токенизатор должен быть зависящим от языка по определению.
Эти две части процесса лексического анализа идут рука об руку и являются центральными для первой фазы процесса компиляции. Конечно, разные компиляторы созданы по-своему. Некоторые компиляторы выполняют этап сканирования и токенизации в одном процессе и как единую программу, в то время как другие разделяют их на разные классы, и в этом случае токенизатор будет вызывать класс сканера при его запуске.

В любом случае этап лексического анализа очень важен для компиляции, потому что этап синтаксического анализа напрямую зависит от него. И хотя у каждой части компилятора есть свои специфические роли, они опираются друг на друга и зависят друг от друга, как это всегда делают хорошие друзья.
Ресурсы
Поскольку есть много разных способов написать и спроектировать компилятор, есть также много разных способов научить их. Если вы проведете достаточно исследований по основам компиляции, станет довольно ясно, что в некоторых объяснениях содержится гораздо больше деталей, чем в других, что может оказаться полезным, а может и не оказаться. Если вы обнаружите, что хотите узнать больше, ниже представлены различные ресурсы по компиляторам - с акцентом на фазу лексического анализа.
- Глава 4 - Ремесленные переводчики, Роберт Нистром
- Конструирование компиляторов, профессор Аллан Готтлиб
- Основы компилятора, профессор Джеймс Алан Фаррелл
- Написание языка программирования - лексера, Энди Валаам
- Заметки о том, как работают парсеры и компиляторы, Стивен Раймонд Ферг
- В чем разница между токеном и лексемой?, StackOverflow