Введение
Прогнозирование категории электронной почты можно рассматривать как задачу классификации нескольких классов, поскольку электронные письма с похожими темами могут автоматически создаваться с использованием схожих шаблонов. Цель этой статьи состоит в том, чтобы предсказать будущее электронное письмо, которое будет получено пользователем, в соответствии с его предыдущими электронными письмами. То есть, если пользователь получил письмо с определенными темами, через несколько дней ему может быть отправлено письмо с такими же или похожими шаблонами.
Статья имеет очень практическое значение, которое может принести непосредственную пользу в нашей повседневной жизни. Точно предсказывая категорию электронного письма, мы можем лучше извлечь из него полезную информацию в соответствии с соответствующими шаблонами. Это будет очень полезно для почтовых провайдеров, например, для автоматической вставки расписания пользователя в его календарь, тем самым улучшая пользовательский опыт.
В статье используются нейронные сети MLP и LSTM соответственно, чтобы сделать прогноз, чтобы сравнить с ранее использовавшейся моделью цепи Маркова.
Модели MLP и LSTM, предложенные в этой статье, достигли одних из самых высоких показателей MRR, 0,918 и 0,923 соответственно, по сравнению с 0,840 в модели 5-зависимой цепи Маркова, повышая точность прогнозирования по состоянию. -of-the-art примерно на 9%.
Помимо результатов, в этой статье подчеркивается, что для прогнозирования категории будущего электронного письма важно не только учитывать ранее встречавшиеся категории. , но также и информацию об отметке времени, что и было выбрано в статье при сопоставлении входных объектов.
Три модели в сравнении
1. Цепь Маркова
Одной из наиболее влиятельных моделей для решения проблемы прогнозирования категории электронной почты была модель цепи Маркова, предложенная Gamzu et al. Цепь Маркова может быть выражена «парами состояний» следующим образом:

где от a^(1) до a^(n) относится к последовательности категорий электронной почты для n электронных писем, полученных пользователем, отсортированных в частности, по полученным временным меткам; и k относится к выбранному нами окну предсказания, что означает, что мы рассматриваем k электронных писем в каждом состоянии, также называемом k-зависимой цепью Маркова. Затем мы можем построить ориентированный граф с узлами в качестве разных состояний, а ребро связывает два состояния в паре состояний. Вес каждого ребра представляет собой «вероятность перехода» из одного состояния в другое состояние. Этот тип модели цепи Маркова используется для прогнозирования будущего электронного письма, и благодаря объединению с временной информацией модель достигла точности около 45%.
2. Многослойные персептроны (MLP)
Первая модель нейронной сети, предложенная в статье, — это простая модель прямой связи: многослойный персептрон (MLP). В отличие от обычной сигмовидной или гиперболической тангенциальной функции активации, в статье используются выпрямленные линейные единицы (ReLU) в своих нейронах, что лучше имитирует «разреженную активацию» реальных нейронов, поэтому является более правдоподобным с биологической точки зрения. (Например, для широко используемой сигмовидной функции будет активирована почти половина нейронов, что не соответствует фактическому положению реальных нейронов в нашем мозгу.) Калибровочная функция записывается как:
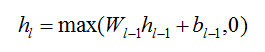
Где h_l относится к выходным данным l-го слоя, W – это матрица весов между слоями l-1 и l, а b — вектор смещения.
Если MLP имеет L скрытых слоев, выходной слой сначала будет использовать логит-функцию для создания вектора z:

Затем с помощью функции softmax создается вектор вероятности:
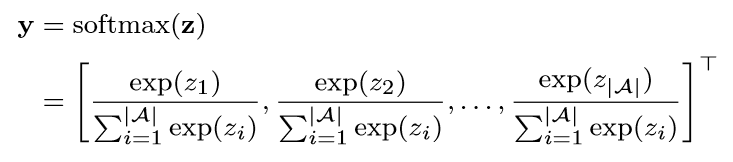
Где A означает количество всех категорий электронной почты. Таким образом, вероятность того, что будущее электронное письмо будет принадлежать категории a-th, P(a), составляет [y]a .
Оптимизируемая функция потерь при обучении записывается как:

Где u относится к конкретному пользователю, a_u^t относится к категории, а m_u^t отметка времени письма, полученного вовремя т. Дельта — это размер временного окна прогноза, что означает, что мы рассматриваем электронные письма, которые приходят последовательно в течение времени дельты. Функция 1 имеет значение 1, если промежуток времени между двумя электронными письмами не превышает дельты, и 0, наоборот (в статье дельта установлена равной одной неделе). Затем для оптимизации L используется «алгоритм стохастической оптимизации Адама», а для вычисления градиента L по отношению к параметрам W и b используется «алгоритм усеченного обратного распространения во времени» (см. D. Kingma and J. Ba. Adam, 2014 г. и И. Гудфеллоу, Ю. Бенжио и А. Курвиль, 2016 г.).
3. Долгая кратковременная память
Второй
моделью нейронной сети является долговременная кратковременная память (LSTM), которая оказывается очень эффективной при решении последовательных задач. По сравнению с довольно простой структурой MLP, LSTM имеет «ячейки памяти» на каждом уровне, которые обрабатывают электронные письма одно за другим и сохраняют выходные данные предыдущего уровня, а также информацию о предыдущем электронном письме. Более формальное выражение можно записать так:
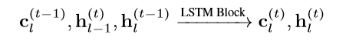
Мы можем понять это более четко по графику ниже:

При дальнейшем рассмотрении того, как работает «блок LSTM», мы можем получить более четкое представление о том, почему ячейка памяти c на самом деле может «запоминать»:
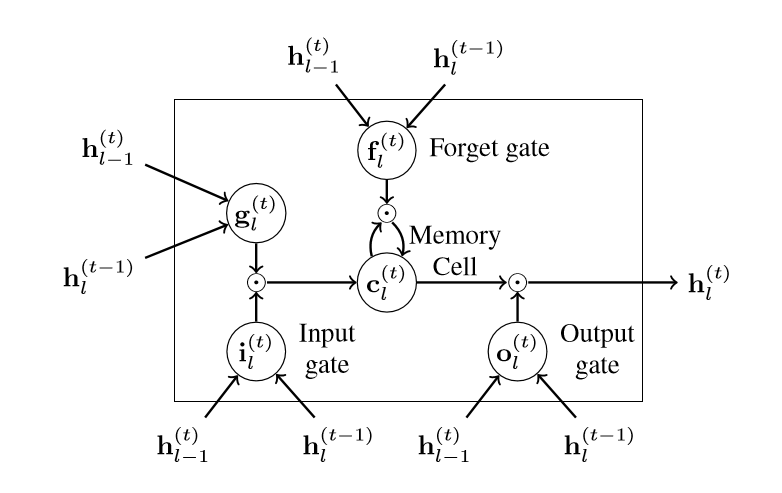
h_1⁰ и c_1⁰ инициализируются как нулевые векторы, и в каждом состоянии обработки блок LSTM одновременно обновляет параметры, показанные на графике выше, как:

где sigma σ — сигмовидная функция. σ и tanh являются поэлементными, а символ в последних двух уравнениях также является поэлементным оператором умножения.
Несколько основных моментов в этой статье
1. Сопоставление входных данных
Как упоминалось выше, в документе предлагается, чтобы вероятность категории будущего электронного письма относилась не только к категориям предыдущих электронных писем, но и к временной информации этих электронных писем. Таким образом, при отображении входных k полученных писем в вектора действительных чисел каждый вектор электронной почты состоит из трех частей:
- «вектор категории» a этого электронного письма, используя однократное представление. (длина вектора A - это количество всех категорий, а-е измерение установлено равным 1, а остальные измерения установлены равными 0). Если у нас есть категории a, вектор категории будет a-мерным.
- "вектор дня недели" d, также отображаемый с помощью прямого представления. (в документе d установлено равным 7, для 7 дней неделю).
- 'вектор периода месяца' p, опять-таки отображаемый однократным представлением (в статье p установлено равным 3, что означает "начало, середина и конец месяца).
промежуток времени между двумя электронными письмами устанавливается как реальные числа. Если он не превышает одной недели, значение будет равно 1; а если он длиннее одной недели, значение будет равно 0. Следовательно, весь входной вектор из k электронных писем будет иметь значения k*s, где s — длина каждого вектора электронной почты, а s=a+d+p+1.
2. Разделение набора данных
В документе используются 102 743 пользователя и 2 562 361 электронное письмо, полученное ими за 90 дней, и эти электронные письма разделены на 17 категорий.
Авторы статьи тщательно рассмотрели все аспекты вопроса и разделили набор данных двумя способами, как показано ниже. Во-первых, тестовый набор содержит те электронные письма, которые были получены известным набором пользователей, но невидимы в обучающем и проверочном наборе; в то время как второй дополнительно гарантирует, что электронные письма в тестовом наборе принадлежат новому набору пользователей.

3. Измерение точности прогноза
В статье используется средний обратный ранг (MRR) для измерения точности прогноза. RR означает обратное значение позиции для первой правильно предсказанной категории, отсортированной по убыванию вероятности, также называемой ранг; M означает вычисление среднего значения всех рангов.
< br /> Кроме того, показатель успешности r(SR@r) используется для измерения точности, что подразумевает долю тестовых электронных писем, рейтинг которых меньше или равен r в течение времени прогнозирования. window.
Например, при разделении набора данных двумя упомянутыми выше способами и постепенном увеличении окна прогноза k соответствующие MRR и SR@r цепи Маркова модели показаны ниже.


4. Предотвращение переобучения
В статье используется метод регуляризации отсева для рекуррентных нейронных сетей для уменьшения переобучения (см. V. Pham, T. Bluche, C. Kermorvant и J. Louradour, 2014). Вкратце, отсев означает случайную очистку некоторых нейронов в скрытых слоях (то есть обнуление). На рисунке ниже показано, что с некоторым положительным отсевом модель LSTM может достичь более высокого MRR. На рисунке также показано, что для модели LSTM одного скрытого слоя достаточно для достижения удовлетворительных результатов, в то время как MLP может потребоваться больше скрытых слоев для достижения тех же результатов.

Результаты
Результаты эксперимента дают представление о следующих пяти аспектах:
а) Модель цепи Маркова недостаточна для описания полезной информации, содержащейся в электронных письмах, поскольку она не может очень хорошо отображать временные особенности прошлых электронных писем. Поскольку модели MLP и LSTM могут лучше описывать временную информацию, они явно превосходят модель цепи Маркова. LSTM работает лучше всех трех моделей.
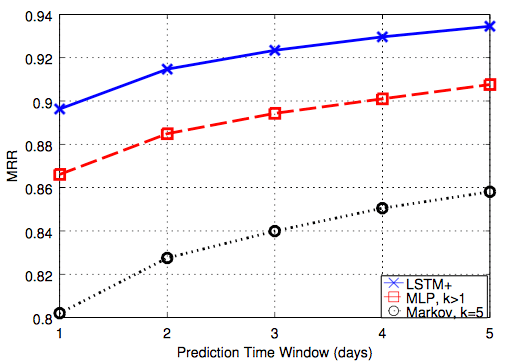
б) Увеличение количества скрытых слоев выше 2 и количества нейронов в каждом слое как в MLP, так и в LSTM не обеспечивает значительного улучшения производительности, как показано ниже:

c) Увеличение размера окна предсказания k может значительно повысить точность только в том случае, если k не больше 5, что также показано на рисунке 7. А увеличение размера окна времени предсказания также повышает точность, что также показано на рисунке 6.
< br /> d) При использовании второго метода разбиения данных, описанного на рисунке 3, при котором пользователи в тестовой выборке невидимы в обучающей и проверочной выборке, все три модели достигают меньшей точности, но это не очень существенно, несмотря на 5-зависимая цепь Маркова, как показано в таблицах ниже.


e) если мы минимизируем «возможности памяти» трех моделей (для модели цепей Маркова и MLP это означает установить k = 1, а для модели LSTM это означает очистить всю ячейку памяти), производительность всех три модели несколько хуже, что также показано в таблицах ниже.
Заключение
Модели MLP и LSTM, предложенные в этой статье, достигают самых высоких показателей MRR 0,918 и 0,923 соответственно, по сравнению с 0,840 в 5-зависимой модели цепи Маркова. Даже при очистке всех возможностей памяти трех моделей производительность LSTM по-прежнему остается лучшей.
Это довольно всеобъемлющий эксперимент, и дальнейшие улучшения могут быть сделаны при выяснении того, как отображать больше функций. прошлых электронных писем, а не текущую информацию о категории и временную информацию.
Комментарий рецензента
Из статьи мы увидели, что LSTM Нейронная сеть достигла наилучшей производительности из всех трех моделей. Фактически, LSTM довольно хорошо работает в широком диапазоне задач, особенно в последовательных задачах (как во времени, так и в пространстве). Одним из наиболее впечатляющих применений LSTM является обработка естественного языка, от тегов POS, анализа синтаксической структуры до задач машинного перевода и распознавания речи, и все они требуют, чтобы модель могла обрабатывать долгосрочный контекст или зависимости между символами. входная последовательность.
Некоторые языки, которые также имеют фиксированные грамматические шаблоны, такие как коннекторы в китайском и японском языках, в которых некоторые коннекторы, скорее всего, появятся после некоторых других парных коннекторов. Методы, предложенные в этой статье, могут послужить источником вдохновения для улучшения генерации естественного языка или понимания естественного языка.
Ссылка
[1] Aston Zhang, Луис Гарсия-Пуэйо, Джеймс Б. Вендт, Марк Найорк, Андрей Бродер, Предсказание категории электронной почты
Источник: https://static.googleusercontent.com/media/research.google.com /zh-CN//pubs/archive/45896.pdf
[2] Д. Кингма и Дж. Ба. Адам: Метод стохастической оптимизации. Препринт arXiv: 1412.6980, 2014.
[3] В. Фам, Т. Блюш, К. Керморвант и Дж. Лурадур. Dropout улучшает рекуррентные нейронные сети для распознавания рукописного ввода. На 14-й Международной конференции по границам в распознавании рукописного ввода, страницы 285–290, 2014 г.
Источник: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45896.pdf
Автор статьи: Астон Чжан, Луис Гарсия-Пуэйо, Джеймс Б. Вендт, Марк Найорк, Андрей Бродер, Университет штата Иллинойс, Урбана-Шампейн, Иллинойс, США, Google, Калифорния, США
Автор: Кеджин Джин | Рецензент: Хао Ван