
В моей предыдущей статье я обсуждал регрессионный анализ, особенно линейную регрессию. Статью можно найти здесь.
Я хотел бы привести несколько примеров использования регрессионного анализа, прежде чем мы перейдем к основной теме.
- Определение силы прогнозов
- прогнозирование эффекта
- прогнозирование тенденций
Давайте представим, что мы пытаемся продать фирме по недвижимости алгоритм прогнозирования рынка жилья. Он прогнозирует цены на жилье на основе таких факторов, как количество спален и размер участка. Компании по недвижимости могут легко заработать миллионы на этой информации, но им нужно доказательство того, что она работает, прежде чем они купят ваш алгоритм.
Чтобы оценить эффективность алгоритма обучения, вам необходимо усвоить две ключевые концепции. Они есть:-
- Дисперсия
- Предвзятость
Дисперсия
Чувствительность прогноза к используемому обучающему набору измеряется его дисперсией. В идеальном мире не должно иметь значения, как мы выбираем тренировочный набор, то есть желательна более низкая дисперсия.
Предвзятость
Смещение — это сила предположений, сделанных в отношении обучающего набора данных. Использование слишком большого количества предположений может затруднить обобщение, а это означает, что предпочтение отдается более низкому смещению.
Если модель слишком адаптивна, она может в конечном итоге запомнить обучающие данные, а не разрешать полезные шаблоны. Представьте себе извилистую функцию, которая проходит через каждую точку в наборе данных без каких-либо ошибок. Когда это происходит, говорят, что алгоритм обучения переобучил данные. Кривая наилучшего соответствия в этом случае будет хорошо согласовываться с данными обучения, но она может плохо работать при оценке данных тестирования (рис. 1).

С другой стороны, менее гибкая модель может лучше обобщать неизвестные данные тестирования, но плохо работать с обучающими данными.
Термин "недостаточное приспособление" для этой ситуации.
Слишком гибкая модель имеет высокая дисперсия, но низкое смещение, тогда как слишком строгая модель имеет низкую дисперсию, но большое смещение.
Нам нужна модель с низкой ошибкой дисперсии, а также с низкой ошибкой смещения.
Таким образом, она одновременно обобщает новые данные и фиксирует закономерности данных.
Примеры недостаточного соответствия модели и переоснащение точек данных в 2D, см. рис. 2.

Говоря более конкретно, дисперсия модели — это мера того, насколько сильно колеблются ответы, а предвзятость — это мера того, насколько далеко ответ отклоняется от основной истины. Вы хотите, чтобы ваша модель давала результаты, которые были бы точными (низкая систематическая ошибка) и воспроизводимыми (низкая дисперсия).
Подводя итог, можно сказать, что измерение того, насколько хорошо ваша модель работает с обучающими данными, не является хорошим показателем ее обобщаемости. Вместо этого вы должны протестировать свою модель на другом наборе тестовых данных.
Вот почему для измерения успеха в машинном обучении мы разделяем набор данных на две группы: набор данных для обучения и набор данных для тестирования. Набор обучающих данных используется для обучения модели, а набор тестовых данных используется для оценки ее производительности.
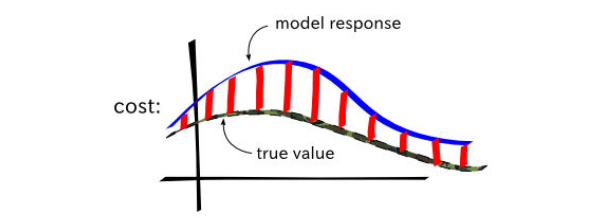
Цель состоит в том, чтобы найти параметр веса, который лучше всего соответствует данным из многих, которые мы можем сгенерировать. Мы определяем функцию стоимости для измерения «наилучшего соответствия», что более подробно обсуждается в моей предыдущей статье.
Увидимся в следующей статье. А пока удачного обучения!!!