В этом посте я рассказываю, как я создал свое первое веб-приложение RemindMe с помощью Clojure! Приложение развернуто здесь: https://remind.otee.dev
Объем проекта
Приложение RemindMe призвано воспроизвести работу карточек в реальном мире. Цитата из Википедии:
Флэш-карта или флэш-карта (также известная как каталожная карточка) — это карточка с информацией на обеих сторонах, которая предназначена для помощи в запоминании. На каждой карточке с одной стороны вопрос, а с другой ответ.
Подобно флеш-картам реального мира, RemindMe отображает вопрос, который выбирается случайным образом из набора вопросов. У пользователя есть возможность увидеть подсказку или перейти к следующему вопросу (который снова будет выбран случайным образом из пула вопросов). Если пользователь решит просмотреть подсказку, будет отображаться подсказка к этому вопросу, и у пользователя снова будет выбор: перейти к следующему вопросу или просмотреть решение. Наконец, если пользователь решит просмотреть решение, соответствующее решение отображается вместе с возможностью перейти к следующему вопросу.
Я хотел создать RemindMe в качестве инструмента для напоминания о моих решениях проблем с LeetCode. По этой причине приложение описывает каждый вопрос как «проблему». Кроме того, хотя текст каждой проблемы взят из LeetCode, подсказки и решения принадлежат мне. (Всегда рад обновить свои решения более оптимальными. Запросы на вытягивание приветствуются!)
Приложение читает файл JSON ( data.txt), чтобы получить доступ к набору проблем, решений и подсказок. Когда мы хотим добавить новую проблему, нам нужно будет обновить файл JSON.
Вот маршруты, поддерживаемые этим приложением:
/problem/:id: Этот маршрут загружает проблему, соответствующую параметру путиid./next: этот маршрут перенаправляет на случайно выбранный маршрут/problem/:id./: То же, что и/next, перенаправляет на новый проблемный маршрут./hint/:id: генерирует полезную нагрузку JSON, содержащую подсказку для соответствующей проблемы (для использования клиентским JavaScript).:/solution/:id: генерирует полезную нагрузку JSON, содержащую подсказку и решение для соответствующей проблемы (для использования клиентским JavaScript).
Вот демонстрация RemindMe.
Цель
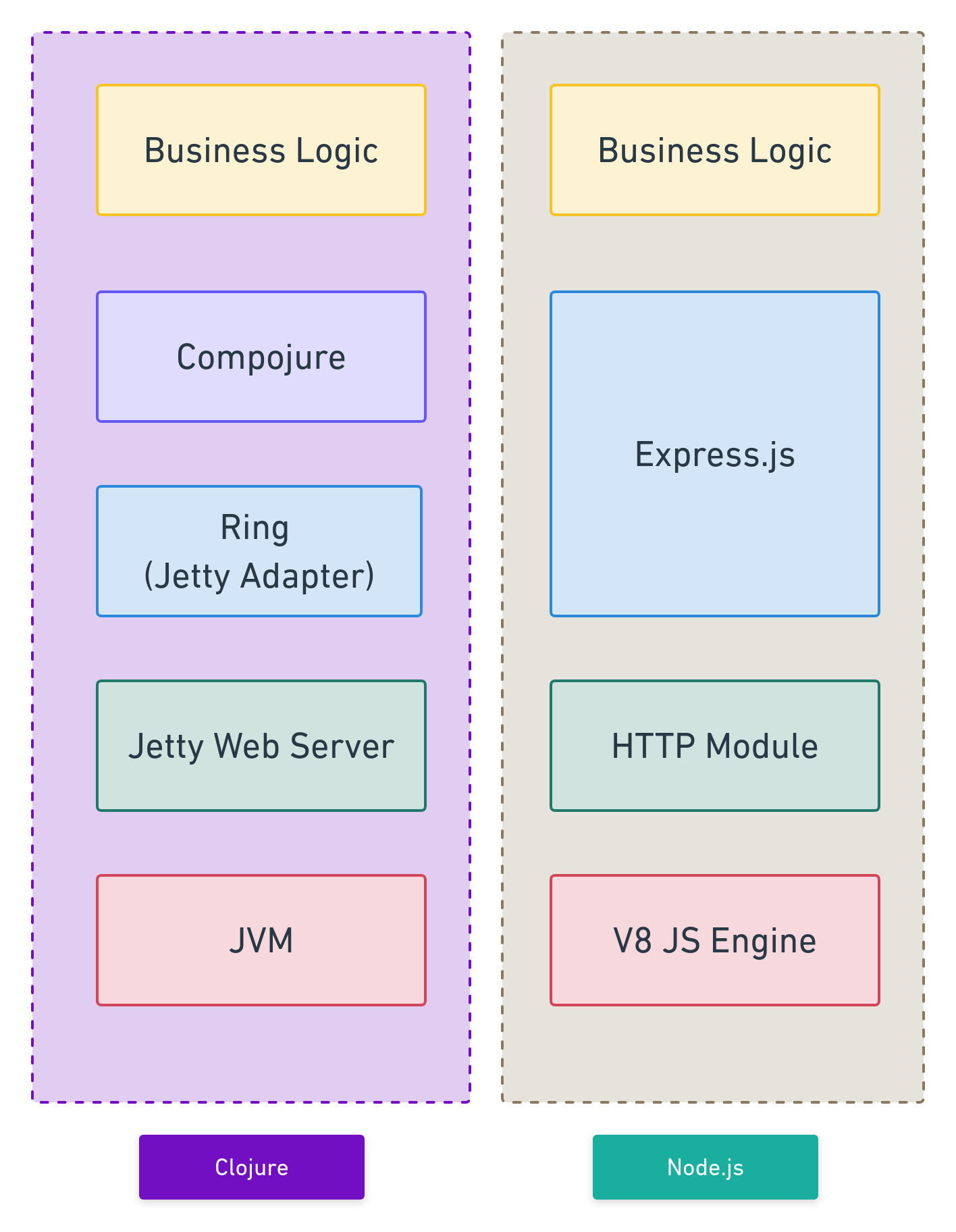
Основная цель — научиться создавать и развертывать проект с помощью Clojure. Но прежде чем отправиться в это путешествие, я сначала создал идентичное приложение, используя Node.js и платформу Express. Это было полезно, так как мне не нужно было тратить много времени на изучение основной бизнес-логики приложения и его внешнего интерфейса при работе с Clojure и фреймворком Ring. Версия приложения Node.js размещена в этом репозитории GitHub: https://github.com/oitee/remind-me.
Таким образом, целью этого проекта является повторная реализация серверной части RemindMe с использованием Clojure и инфраструктуры Ring. Этот проект размещен в отдельном репозитории под названием aspire.
Шаг 0: Добавление зависимостей в проект Leiningen
Для этого проекта нам понадобятся три зависимости:
- Ring: Ring — это веб-фреймворк, аналог Express в Node.js. Он используется для упрощения управления HTTP-запросами с помощью маршрутов, обработчиков и промежуточного программного обеспечения. Цитируя собственную документацию,
Абстрагируя детали HTTP в простой унифицированный API, Ring позволяет создавать веб-приложения из модульных компонентов, которые могут совместно использоваться различными приложениями, веб-серверами и веб-фреймворками.
- Ring-Jetty: поскольку Clojure не поставляется со встроенным HTTP-сервером, в отличие от Node.js, нам необходимо реализовать HTTP-сервер. Ring поставляется с поддержкой по умолчанию для Jetty, веб-сервера Java.
Ring-Jetty — это веб-сервер, который поставляется вместе с Ring. Это оболочка Clojure для Jetty. Это совершенно нормально и приемлемо, и, на мой взгляд, имеет самую простую настройку. Если вы собираетесь использовать Ring, это лучший вариант. Кроме того, он хорошо поддерживается и имеет много пользователей. (Эрик Норманд)
В этом проекте мы будем использовать Ring-Jetty. Мы можем сделать это, включив ring-jetty-adapter в наши зависимости.
- Compojure: это библиотека маршрутизации для Ring, позволяющая легко обрабатывать маршруты.
После добавления трех вышеуказанных зависимостей project.clj будет выглядеть так:
(defproject aspire "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "EPL-2.0 OR GPL-2.0-or-later WITH Classpath-exception-2.0"
:url "https://www.eclipse.org/legal/epl-2.0/"}
:dependencies [[org.clojure/clojure "1.10.0"]
[ring/ring-core "1.9.5"]
[ring/ring-jetty-adapter "1.9.5"]
[compojure "1.6.2"]]
:main ^:skip-aot aspire.core
:target-path "target/%s"
:profiles {:uberjar {:aot :all}})Теперь нам нужно запустить lein deps в командной строке Linux:
Осторожно: он может загрузить весь интернет при первом запуске lein deps. 😛
Шаг 1: Запуск сервера «hello world»
Чтобы запустить простой сервер hello world, нам нужно сначала написать функцию-обработчик, которая будет отвечать на каждый запрос (documentation).
Затем мы передаем этот обработчик функции run-jetty для ответа на запросы. Функция run-jetty запускает HTTP-сервер, который прослушивает порт и, когда на этот порт поступает запрос, вызывает функцию-обработчик. Позже, когда мы напишем более сложный код, функция-обработчик будет решать (на основе параметров запроса, маршрутов, методов и т. д.), как реагировать на определенный запрос. Короче говоря, jetty — это HTTP-сервер, run-jetty преобразует функции Clojure, чтобы они хорошо работали с библиотекой Java jetty.
Обратите внимание, что мы всегда отвечаем hello world, поэтому запросы по любому пути будут получать одинаковый ответ. Если мы напечатаем объект запроса, мы сможем увидеть всю необходимую информацию, которая потребуется для маршрутизации запросов (например, URI).
{:ssl-client-cert nil,
:protocol "HTTP/1.1",
:remote-addr "[0:0:0:0:0:0:0:1]",
:headers
{"sec-fetch-site" "none",
"host" "localhost:3000",
"user-agent"
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
...
"sec-gpc" "1"},
:server-port 3000,
:content-length nil,
:content-type nil,
:character-encoding nil,
:uri "/aaa",
:server-name "localhost",
:query-string nil,
:body
#object[org.eclipse.jetty.server.HttpInputOverHTTP 0x2c9dcdc6 "HttpInputOverHTTP@2c9dcdc6[c=0,q=0,[0]=null,s=STREAM]"],
:scheme :http,
:request-method :get}Шаг 2: Маршрутизация
В приведенном выше фрагменте мы использовали одну функцию для ответа на все запросы. Однако это было бы сложно при управлении запросами с разными методами и/или путями HTTP.
Поскольку наш проект поддерживает несколько маршрутов, мы будем использовать маршруты, предоставленные compojure, чтобы определить, как следует отвечать на запрос по определенному маршруту (аналогично приложению Express.js).
Итак, предыдущую функцию handler следует заменить на app:
Обратите внимание, что:
defroutes— это макрос, который возвращает функцию обработчика кольца. Это позволяет нам определять и объединять несколько маршрутов под одним зонтиком (точнее, обработчиком).- Индивидуальные маршруты
compojureтакже являются макросами (и их можно использовать автономно, т. е. безdefroutes). compojureмакросы маршрутов основаны на методах HTTP, т. е.GETPUTи т. д.- Путь запроса сопоставляется с первым аргументом макроса маршрута (обратите внимание на
"/"послеcompojure/GET). - Последний аргумент формирует ответ для этого конкретного маршрута. Как только метод HTTP и путь совпадут, этот аргумент сформирует ответ. Это может быть не значение данных, а функция, которая будет иметь доступ к входящему запросу для формирования ответа.
- Второй аргумент в макросе
GETиспользуется для параметров: формы и параметров запроса (в этом проекте мы его использовать не будем) - Существует способ иметь запасной маршрут, то есть
not-found, для отправки ответа, когда ни один из маршрутов не совпадает (здесь мы используем ответPage not found, когда ничего не совпадает).
Шаг 3: Добавление маршрутов «RemindMe»
Вот маршруты, используемые в Node.js версии проекта:
router.get("/", renderHome);
router.get("/problem/:id", getProblem);
router.get("/next", goToNext);
router.get("/hint/:id", getHint);
router.get("/solution/:id", getSolution);Мы можем переписать эти маршруты, используя compojure, и предоставить определенные функции обработчика маршрутов для каждого маршрута:
Здесь следует отметить две вещи:
- Если URL-адрес имеет параметр в пути, мы можем использовать
:для ссылки на этот параметр в маршруте. Этот тип определения маршрута аналогичен описанию в Express.js. - Второй аргумент
GETбольше не является вектором; мы просто даем ему имя (params), хотя мы можем его не использовать.
Теперь давайте напишем обработчики маршрута (т. е. третий аргумент для каждого маршрута compojure). Начнем с problem-by-id. Обратите внимание, что нам нужно получить доступ к параметру в пути URL. Доступ к этому можно получить из карты запросов. Мы можем распечатать карту запроса, чтобы увидеть соответствующий ключ params.
Как только мы отправим запрос по пути /problem/foo, мы сможем увидеть всю карту запросов:
{:ssl-client-cert nil,
:protocol "HTTP/1.1",
:remote-addr "[0:0:0:0:0:0:0:1]",
:params {:id "foo"},
...
:scheme :http,
:request-method :get}Мы можем получить доступ к ключу params, чтобы увидеть значение нашего параметра пути и соответствующим образом написать наши обработчики:
Каждая из вышеперечисленных функций упоминается в наших маршрутах compojure, поэтому при совпадении пути запроса и метода будет вызвана соответствующая функция.
Шаг 4: Реорганизация кода
В настоящее время все обработчики и маршруты находятся в одном пространстве имен. Мы можем разделить их на три пространства имен: одно для запуска сервера, одно для определения маршрутов и одно для обработчиков маршрутов:
aspire.core: Это запустит серверaspire.routes: Это определит маршрутыaspire.handlers: здесь будут функции обработчика маршрута
На данный момент структура проекта выглядит так:
.
├── LICENSE
├── project.clj
├── README.md
├── resources
├── src
│ └── aspire
│ ├── core.clj
│ ├── handlers.clj
│ └── routes.clj
└── test
└── aspire
└── core_test.cljaspire.core содержит код запуска сервера:
aspire.routes содержит определения маршрута:
aspire.handlers содержит функции обработчика маршрута:
Шаг 5: Реализация бизнес-логики
Теперь, когда у нас есть веб-сервер, определены наши маршруты и обработчики маршрутов, мы можем создавать фактические функции продукта, соответствующим образом определяя функции обработчиков маршрутов. Для этого нам нужен механизм шаблонов и способ чтения данных из файла JSON.
- Обработчик шаблонов: Версия приложения Node.js использовала обработчик шаблонов Mustache. Итак, нам нужно поддерживать Mustache и в Clojure. Это гарантирует, что интерфейс останется неизменным. Для этого мы можем использовать
de.ubercode.clostache/clostacheкак зависимость (документация) - Чтение данных: фактическое содержимое проекта (такое как описания и решения проблем и т. д.) хранится в файле JSON, который нам нужно прочитать для обслуживания запроса. Для этого мы можем использовать
org.clojure/data.jsonв качестве зависимости (документация)
Компонент модели
Файл JSON, содержащий наборы задач, выглядит следующим образом:
[
{
"id": "find-peak-element",
"problemTitle": "Find Peak Element",
"problemDescription": "A peak element is an element that is strictly greater than its neighbors. Given an integer array nums, find a peak element, and return its index. If the array contains multiple peaks, return the index to any of the peaks. You may imagine that nums[-1] = nums[n] = -∞. You must write an algorithm that runs in O(log n) time.",
"hint": "Start with the middle element",
"solution": "Start with mid element.\n If this is a peak, then return it.\n If this element is less than the next element, it means this element is part of an asceding slope. So, make lo = mid + 1,\n If this element is less than the earlier element, move to the earlier sub-array, ie, hi = mid - 1\n At the end, if lo === hi, lo is the peak element. Because it would mean we have reached the end of the array. And edges are peaks, if their adjacent element are smaller than them."
},
{
"id": "boats-to-save-people",
"problemTitle": "Boats to Save People",
"problemDescription": "You are given an array people where people[i] is the weight of the ith person, and an infinite number of boats where each boat can carry a maximum weight of limit. Each boat carries at most two people at the same time, provided the sum of the weight of those people is at most limit.\n\n Return the minimum number of boats to carry every given person.\n ",
"hint": "Start with sorting the array",
"solution": "Sort the array.\n For each people[hi] + people[lo] > limit, hi-- and boats++.\n For others, hi-- lo++ boats++\n At the end, if hi == lo (indicating that there was an odd number of elements), boats++"
},
...
]Нам нужно проанализировать этот файл JSON, используя clojure.data.json
Функция read-str (из пространства имен clojure.data.json) берет строку JSON и преобразует ее в допустимую структуру данных Clojure. Из-за характера данных, содержащихся в файле JSON, data будет вектором хэш-карт.
Обратите внимание, что мы передаем дополнительный аргумент в read-str, называемый :key-fn keyword. Это гарантирует, что ключи хэш-карт, сгенерированных read-str, будут ключевыми словами, а не строками. Вот как выглядит хэш-карта:
Теперь нам нужно преобразовать этот вектор в хэш-карту, где каждый id будет отображаться в соответствующую хэш-карту (представляющую набор задач)
data-map — это хэш-карта набора идентификаторов проблем. Это поможет в поиске проблем с их соответствующими идентификаторами.
Также нам нужны две дополнительные функции для наших обработчиков маршрутов:
get: чтобы получить набор задач отid, иrandom-id: за возврат случайно выбранногоidизdata-map
Обработчики маршрутов
Нам нужно написать обработчики маршрутов для каждого маршрута. Начнем с обработчика маршрута для /problem/:id.
Если параметр id правильный, этот обработчик маршрута должен сгенерировать домашнюю страницу с необходимыми сведениями о соответствующем наборе проблем.
Для этого нам нужно отрендерить файл шаблона (home.mustache), используя clostache
Функция render-resource в clostache.parser представляет собой механизм шаблонов. Первым аргументом должно быть расположение файла шаблона. Согласно документации, render-resource может «рендерить ресурс из пути к классам».
Путь к классам — это последовательность путей, которую Clojure (или Java) «проверяет при поиске исходного файла Clojure». В проекте Leiningen следующие каталоги включены в путь к классам по умолчанию: каталоги src, test, classes, test-resources и resources (источник). Это означает, что наш файл шаблона должен быть помещен в любой из этих каталогов, чтобы render-resource мог получить к нему доступ. Соответственно, файл шаблона (home.mustache) помещается в подкаталог (templates) внутри каталога resources проекта.
Чтобы написать обработчик маршрута для /next, нам нужно знать, как отправить ответ о перенаправлении. Для этого нам нужно потребовать пространство имен ring.util.response и использовать в нем функцию redirect:
Аналогично устроены и другие обработчики маршрутов. (см. код здесь).
Развертывание
Чтобы запустить этот проект на нашей виртуальной машине Google Cloud Platform (GCP), нам необходимо выполнить следующие шаги:
- Скомпилируйте код в Java JAR
- Зарегистрируйте нашу программу как услугу с помощью
Systemd - Установите файл конфигурации NGINX и настройте запись DNS.
Компиляция кода в JAR
Поскольку Clojure размещается на виртуальной машине Java, приложения Clojure запускаются так же, как и приложения Java.
Как исходный код Java соблюдается?
- Сначала компилятор Java преобразует исходный код в байт-код Java.
- После преобразования программы в байт-код Java она может выполняться виртуальной машиной Java, которая является средой выполнения для Java (Источник).
- Байт-код Java сохраняется в файлах классов; файл Java ARchive, также называемый JAR, может хранить коллекцию файлов классов (исходный код)
Исходный код Clojure преобразуется в определенный JAR-файл, который может выполняться JVM.
Поскольку наш проект построен с использованием Leiningen, мы можем использовать lein jar для создания JAR-файла нашего проекта. Этот файл будет храниться в каталоге target нашего проекта. Вместо простого использования lein jar мы можем использовать lein uberjar, который создаст файл JAR, содержащий исходный код нашего проекта, вместе со всеми его зависимостями. uberjar — это отдельный автономный исполняемый файл jar. файл», что упрощает развертывание. Как только убержар подготовлен, мы можем запустить его, просто используя команду java -jar. При желании мы можем использовать lein clean для очистки нашего каталога target. Чтобы запустить несколько команд последовательно, мы можем использовать lein do. Итак, вот как мы сначала очищаем наш каталог target, а затем компилируем наш проект в один файл JAR:
$ lein do clean, uberjar
Java HotSpot(TM) 64-Bit Server VM warning: Options -Xverify:none and -noverify were deprecated in JDK 13 and will likely be removed in a future release.
Compiling aspire.core
2022-01-24 18:38:32.790:INFO::main: Logging initialized @1495ms to org.eclipse.jetty.util.log.StdErrLog
WARNING: seqable? already refers to: #'clojure.core/seqable? in namespace: clojure.core.incubator, being replaced by: #'clojure.core.incubator/seqable?
WARNING: seqable? already refers to: #'clojure.core/seqable? in namespace: clostache.parser, being replaced by: #'clojure.core.incubator/seqable?
WARNING: get already refers to: #'clojure.core/get in namespace: aspire.db, being replaced by: #'aspire.db/get
Compiling aspire.db
WARNING: get already refers to: #'clojure.core/get in namespace: aspire.db, being replaced by: #'aspire.db/get
Compiling aspire.handlers
Compiling aspire.routes
Created /home/otee/projects/aspire/target/uberjar/aspire-0.1.0-SNAPSHOT.jar
Created /home/otee/projects/aspire/target/uberjar/aspire-0.1.0-SNAPSHOT-standalone.jarЧтобы запустить проект из JAR, нам нужно убедиться, что мы не читаем файлы из локальной файловой системы. В данном проекте все файлы, не относящиеся к Clojure, считываются из пути к классам. В случае data.txt, на котором размещен набор данных JSON, мы не можем напрямую использовать путь к файлу, поглощая его. Вместо этого мы должны использовать метод resource для чтения файла из пути к классам:
(slurp (clojure.java.io/resource "data.txt"))Развертывание uberjar на GCP VM
Теперь, когда у нас есть файл JAR, нам нужно отправить его на нашу виртуальную машину в GCP (псевдоним calculus). Мы можем сделать это с помощью команды rsync, которая позволяет передавать файлы по SSH. Интересно, что он синхронизирует передаваемые данные между разными машинами: гарантирует, что передаются только те файлы, которые являются новыми или обновленными.
rsync /home/otee/projects/aspire/target/uberjar/aspire-0.1.0-SNAPSHOT-standalone.jar calculus:/home/oitee.codes/projectsПосле развертывания JAR мы можем запустить его на виртуальной машине, используя:
java -jar -Xmx32m /home/oitee.codes/projects/aspire-0.1.0-SNAPSHOT-standalone.jarФлаг -Xmx используется для указания максимального выделения памяти в куче для запуска программы Java. Когда мы используем -Xmx32m, мы ограничиваем выделение памяти до 32 МБ.
Регистрация в системе
Нам нужно использовать systemd, чтобы обеспечить бесперебойную работу нашего приложения. Чтобы настроить systemd для нашего приложения, нам нужно написать новый файл конфигурации ( remind.service) в /lib/systemd/system.
sudo nano /lib/systemd/system/remind.serviceЭтот файл должен содержать следующие данные:
[Unit]
Description=remind
Documentation=https://github.com/oitee/aspire#readme
After=network.target
[Service]
Environment=PORT=4003
Type=simple
User=oitee.codes
ExecStart=/usr/bin/java -Xmx32m -jar /home/oitee.codes/projects/aspire-0.1.0-SNAPSHOT-standalone.jar
Restart=on-failure
[Install]
WantedBy=multi-user.targetБолее подробное объяснение каждого из этих терминов см. в этом полезном посте или в моем предыдущем посте о настройке виртуальной машины в Google Cloud Compute.
Обратите внимание, что нам нужно указать значение внутреннего порта (PORT=4003), где наш сервер будет прослушивать запись Environment. Кроме того, под записью ExecStart мы не можем использовать java; вместо этого мы должны указать расположение исполняемого файла Java, то есть /usr/bin/java. (/usr/bin — это 'основной каталог исполняемых команд в системе').
Теперь нам нужно выполнить следующие команды, чтобы systemd запустило наше приложение (подробнее об этом читайте в предыдущем посте):
sudo systemctl daemon-reload
sudo systemctl start remind.service
sudo systemctl enable remind.serviceЭто должно запустить наше приложение. Чтобы увидеть статус статуса нашего приложения, мы можем использовать следующую команду:
sudo systemctl status remind.service
● remind.service - remind
Loaded: loaded (/lib/systemd/system/remind.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-01-24 09:25:30 UTC; 18s ago
Docs: https://github.com/oitee/aspire#readme
Main PID: 178875 (java)
Tasks: 22 (limit: 1159)
Memory: 119.4M
CGroup: /system.slice/remind.service
└─178875 /usr/bin/java -Xmx32m -jar /home/oitee.codes/projects/aspire-0.1.0-SNAPSHOT-standalone.jar
Jan 24 09:25:30 calculus systemd[1]: Started remind.
Jan 24 09:25:33 calculus java[178875]: 2022-01-24 09:25:33.385:INFO::main: Logging initialized @2707ms to org.eclipse.jetty.util.log.StdErrLog
Jan 24 09:25:35 calculus java[178875]: WARNING: seqable? already refers to: #'clojure.core/seqable? in namespace: clojure.core.incubator, being replaced by: #'clojure.core.incubator/seqable?
Jan 24 09:25:35 calculus java[178875]: WARNING: seqable? already refers to: #'clojure.core/seqable? in namespace: clostache.parser, being replaced by: #'clojure.core.incubator/seqable?
Jan 24 09:25:35 calculus java[178875]: WARNING: get already refers to: #'clojure.core/get in namespace: aspire.db, being replaced by: #'aspire.db/get
Jan 24 09:25:35 calculus java[178875]: 2022-01-24 09:25:35.264:INFO:oejs.Server:main: jetty-9.4.44.v20210927; built: 2021-09-27T23:02:44.612Z; git: 8da83308eeca865e495e53ef315a249d63ba9332; jvm 17.0.1+12-Ubuntu-120.04
Jan 24 09:25:35 calculus java[178875]: 2022-01-24 09:25:35.454:INFO:oejs.AbstractConnector:main: Started ServerConnector@4052913c{HTTP/1.1, (http/1.1)}{0.0.0.0:4003}
Jan 24 09:25:35 calculus java[178875]: 2022-01-24 09:25:35.456:INFO:oejs.Server:main: Started @4815msИспользование NGINX для перенаправления трафика с порта 80
Чтобы перенаправить запросы к порту 80 нашей виртуальной машины на определенный внутренний порт, который будет прослушивать наш сервер (4003), нам нужно написать файл конфигурации для NGINX. Во-первых, мы должны добавить файл конфигурации remind.otee.dev в файл /etc/nginx/sites-available.
sudo nano /etc/nginx/sites-available/remind.otee.devЭтот файл должен содержать следующие данные:
server {
listen 80;
listen [::]:80;
server_name remind.otee.dev;
location / {
proxy_pass http://127.0.0.1:4003;
}
}Теперь нам нужно включить эту конфигурацию, добавив на нее символическую ссылку в каталоге /etc/nginx/sites-available:
sudo ln -s /etc/nginx/sites-available/remind.otee.dev /etc/nginx/sites-enabled/remind.otee.devДалее нам следует перезапустить NGINX:
sudo systemctl status nginx
sudo systemctl restart nginxТеперь, когда NGINX настроен на перенаправление запросов к remind.otee.dev на внутренний порт 4003, нам нужно настроить собственный домен remind.otee.dev, а затем применить HTTPS с помощью бесплатно доступного инструмента Certbot, предоставленного Lets Зашифровать.
На этом развертывание завершено!🎉
Проект работает по адресу: https://remind.otee.dev
Дальнейшие улучшения
Вот некоторые из улучшений, которые могут быть добавлены в будущем:
- Переместите набор данных в SQLite. Это позволит нам записывать данные в файл. Например, отслеживать аналитику нашего приложения: количество просмотров, запросы подсказок и решений.
- Включите добавление новых наборов задач из пользовательского интерфейса:
- Это можно сделать, создав таблицу «пользователи» с именами пользователей и паролями администратора (используя хорошие принципы хранения паролей, как мы сделали с Twirl).
- Поддержание сеансов на дополнительных маршрутах (промежуточное ПО для разбора файлов cookie)
Первоначально опубликовано на https://otee.dev 25 января 2022 г.