ResNet — это статья, в которой представлена новая архитектура для распознавания изображений, вот полная статья.
Проблема
Многие из моделей до использования ResNet просто добавляли все больше и больше слоев, и результаты модели были бы, по крайней мере, такими же хорошими, как и более мелкая модель. Логика этого заключается в том, что более глубокая модель имеет все те же части, что и поверхностная модель, плюс еще больше.
Неглубокая модель
Глубокая модель
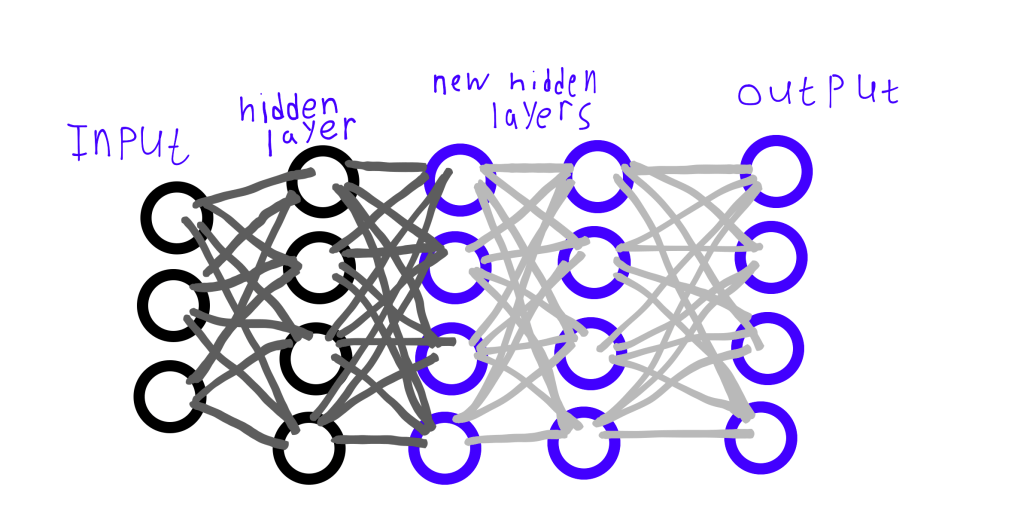
Чтобы глубокая модель работала так же хорошо, как и поверхностная, новые скрытые слои (те, что выделены синим цветом на картинке выше) должны сохранять тот же результат, что и старый скрытый слой (причудливыми словами, новые слои должны найти отображение личности)
Итак, авторы статьи Resnet задали очень простой вопрос: «Изучить более совершенные сети так же просто, как сложить больше слоев?», поэтому, чтобы определить, можно ли просто добавлять все больше и больше слоев и получать все лучше и лучше модели они сделали эксперимент. Для эксперимента они сделали две разные модели, чтобы попытаться предсказать, всегда ли большее количество слоев делает модель лучше: у одной было 20 слоев, а у другой — 56.
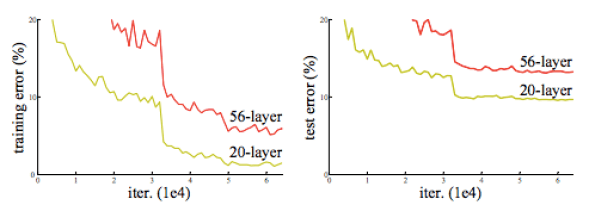
Как вы можете видеть выше, модель с большим количеством слоев на самом деле работала хуже, чем модель с меньшим количеством слоев, одним из возможных объяснений может быть то, что большая модель страдала от проблемы исчезающего градиента. Хотя в прошлом это было проблемой для больших моделей, в основном она решалась с помощью пакетной нормализации (или других нормализованных инициализаций). Таким образом, кажется, что основная проблема с более глубокой моделью заключается в том, что новые слои не могут научиться ничего не делать (она не может изучить отображение идентичности).
Решение
Решение этой проблемы, предложенное авторами, состояло в том, чтобы добавить в модель короткие соединения. Укороченный слой в основном разбивает ввод на две части, одна часть ожидает сбоку, а другая проходит через несколько новых слоев, и в конце они объединяются путем сложения.
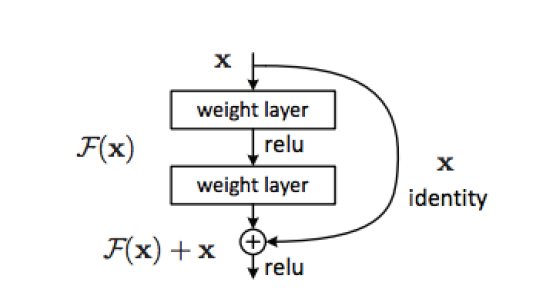
Мыслительный процесс о том, почему эта модель должна работать, выглядит следующим образом, как мы видели в предыдущей части, более глубокая модель не могла легко найти идентичность, однако в этой новой модели идентичность дана.
Полученные результаты
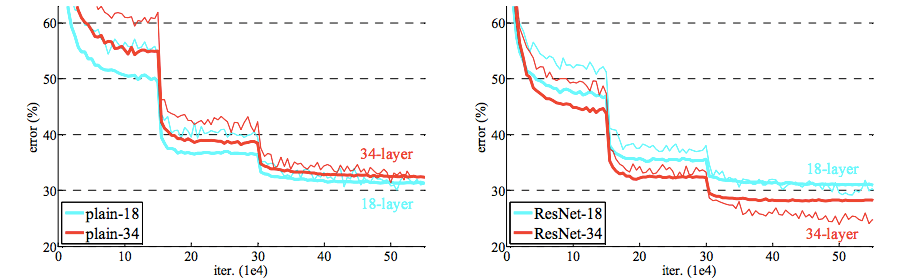
чтобы протестировать новую модель, они создали две разные модели (подробнее об архитектуре смотрите в статье)
- Простая сеть — без коротких соединений (18 слоев и 34 слоя)
- Остаточная сеть — имеет короткие соединения (18 слоев и 34 слоя).
Обычная сеть: при использовании обычной сети возникает проблема, описанная выше. 34-слойная версия работает хуже, чем 18-слойная.
Остаточная сеть: при использовании остаточной сети проблема не в этом, 34-слойная модель работает лучше, чем 18-уровневая.
Сокращенные соединения, используемые для этой задачи, выглядят следующим образом.
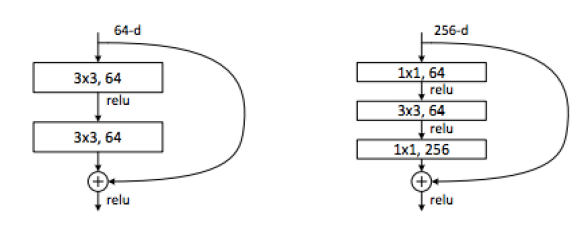
В коротком соединении может быть два или более слоев, но не может быть одного, потому что тогда он может быть только линейным. Другая возможная проблема с моделью заключается в том, что для того, чтобы слой с короткими вырезами добавлял идентичность и новые функции, они должны быть одного размера. Есть два решения этой проблемы: заполнение нулями и проекция. Заполнение нулями просто добавляет нули, чтобы сделать изображения одинакового размера, а проекция проецирует изображение до нужного размера. Преимущество использования заполнения нулями заключается в том, что вычислительная сложность не добавляется, но если используется проекция, она есть. в статье они решили использовать сочетание двух вариантов.
Заключение
Поздравляем, мы сделали это, теперь мы можем добавлять все больше и больше слоев, и модель будет работать все лучше и лучше, или мы можем? в последней части статьи они построили очень большую остаточную сеть с 1202 слоями, и она оказалась хуже, чем остаточная сеть со 110 слоями. Причина, которую они приводят в статье, заключается в том, что модель слоя 1202 превосходит данные, они также дали возможное решение, но не проводили с ним никаких экспериментов. Их идея состояла в том, чтобы просто добавить в модель некоторые методы регуляризации, такие как отсев.