
Введение
Исследовательский анализ данных (EDA) — одна из основных задач, которую выполняет Data Scientist, начиная работу с новым набором данных. Этот процесс информирует нас о распределении или взаимосвязи между переменными, выявляет отсутствующие и нечистые данные и выявляет выбросы. Это помогает в разработке и обновлении конвейеров данных для предварительной обработки входящих данных.
Существуют различные библиотеки Python, которые поддерживают как статистический, так и научный анализ и представление данных. Это делает Python одним из наиболее предпочтительных языков для EDA. В этом посте вы узнаете, как использовать библиотеку Seaborn для EDA и записывать созданные таким образом диаграммы в Comet для совместного использования и совместной работы с командой, а также для облегчения создания отчетов.
Настроить проект Comet
Войдите на Comet.com и нажмите Зарегистрироваться в правом верхнем углу.

Добавьте свои данные или зарегистрируйтесь, используя учетную запись GitHub.

Нажмите «+ Новый проект», чтобы создать новый проект. Это как каталог для всех ваших экспериментов.

Добавьте имя проекта, описание и настройки видимости. Настройки для этой демонстрации показаны на скриншоте ниже.

Нажав на «Краткое руководство», вы получите инструкции по настройке и ключ API.

В разделе «Начало работы с Comet» нажмите Python. Это отобразит команды терминала для установки библиотеки Comet в вашей локальной среде Python.
Вы можете либо создать новую среду, либо использовать базовую среду для установки.

Запустите приведенную ниже команду в своем терминале.
pip install comet_mlПрежде чем писать код, добавьте следующий код в начало скрипта Python (файл .py) или блокнота Jupyter (файл .ipynb).
from comet_ml import Experiment
experiment = Experiment(
api_key="add your api key here",
project_name="add your project name here",
workspace="add your workspace name here",
)
Вы можете найти приведенный выше код прямо на странице «Начало работы с Comet». Вы можете подтвердить, прослушивает ли платформа Comet ваши эксперименты на той же странице. Пожалуйста, обратитесь к скриншоту ниже.

Исследовательский анализ данных
Для этой демонстрации мы будем использовать набор данных House Prices — Advanced Regression Techniques от Kaggle. Это проблема регрессии, где целевой переменной является цена дома, а атрибуты дома, такие как площадь, структура и удобства поблизости, составляют независимые переменные. Поэтому проанализируем взаимосвязь между независимыми переменными и ценой продажи дома. Пойдем!
Импорт необходимых библиотек
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns
Прочитайте данные CSV и просмотрите первые пять строк.
train = pd.read_csv('train.csv')
train.head()

Вы можете увидеть кучу атрибутов, относящихся к зоне, к которой принадлежит дом, или площади в квадратных метрах и подъездной дороге. Получим сводную статистику по:
train.describe().T

Показать распределение продажной цены
Установите размер фигуры в соответствии с вашими потребностями, затем постройте распределение и зарегистрируйте свою диаграмму в эксперименте в своем проекте Comet, используя log_figure(). График распределения показывает распределение цен продажи по различным зонам.
plt.figure(figsize=(15,10)) fig = sns.histplot(data = train, x = "SalePrice", hue="MSZoning") experiment.log_figure(figure_name = "Sale Price Distribution", figure=fig.figure, overwrite=False)

Распределение имеет положительную асимметрию. Вы можете выполнить логарифмическое преобразование, чтобы исправить перекос. Код для построения графика и регистрации неасимметричного распределения выглядит следующим образом:
train['log_sales_price'] = np.log(train['SalePrice']) plt.figure(figsize=(15,10)) sns.histplot(train, x="log_sales_price", hue="MSZoning") plt.show()

Лучше! Получить числовое значение перекоса и эксцесса так же просто, как показано ниже:
print("Skewness: %f" % train['SalePrice'].skew())
print("Kurtosis: %f" % train['SalePrice'].kurt())
Значение перекоса равно 1,88, а эксцесс равен 6,54, что соответствует положительному перекосу. Точно так же мы можем построить график распределения продажной цены с другими переменными.
for i in train.columns:
if len(train[i].value_counts()) < 5 and len(train[i].value_counts()) > 1:
fig = sns.displot(train, x="SalePrice", kde=True, hue=i)
plt.title('Sales Price Distribution by '+i)
experiment.log_figure(figure_name = "Pairplot distribution and Scatterplots", figure=fig.figure, overwrite=False)
Используя вышеуказанные фильтры, мы получаем 15 графиков распределения цен продаж. Ниже показаны три диаграммы для справки.

Форма лота IR1 является популярным выбором и требует более высоких продажных цен по сравнению с обычными формами лота. У него также есть длинный правый хвост, представляющий положительный перекос.

Качество материалов для экстерьера также, по-видимому, является решающим фактором для цены продажи дома, демонстрируя резкую разницу в распределении ее значений.

Полноценные ванные комнаты на цокольном этаже, по-видимому, являются более слабым фактором, определяющим цену жилья.
График продажной цены по сравнению с независимыми переменными
Теперь давайте посмотрим на соотношение цены с. непрерывные переменные с использованием диаграммы рассеяния.
plt.figure(figsize=(15,10)) fig = sns.scatterplot(data=train, x='GrLivArea', y='SalePrice', hue = "MSZoning", palette="deep", style="Street") experiment.log_figure(figure_name = "Complete Data", figure=fig.figure, overwrite=False)
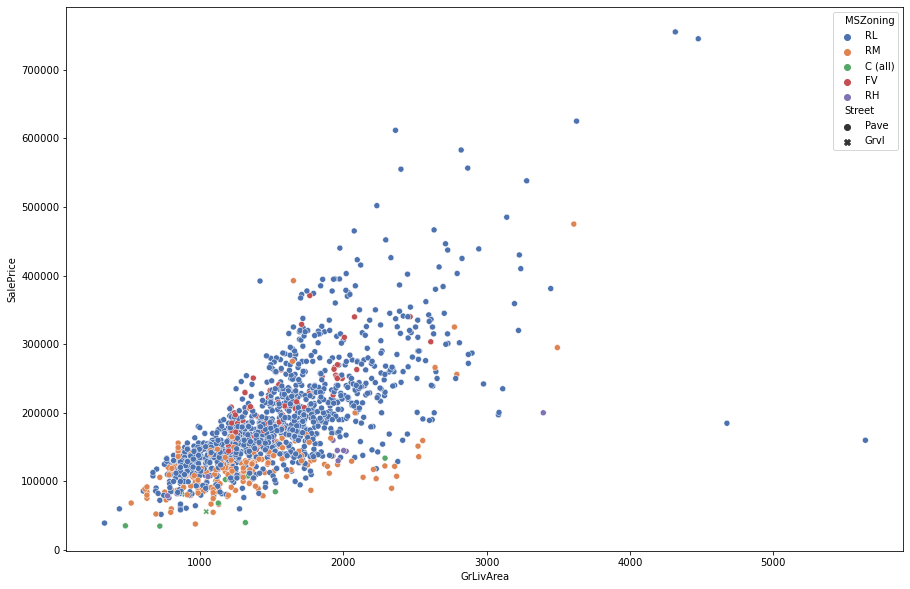
Взаимосвязь кажется нелинейной, при этом дисперсия цен продажи увеличивается с увеличением GrLivArea. Давайте возьмем их в логарифмическом масштабе и еще раз посмотрим на отношения.
train['log_GrLivArea'] = np.log(train['GrLivArea'])
train['log_SalePrice'] = np.log(train['SalePrice'])
plt.figure(figsize=(15,10))
plt.title("Log transform of Sales Price vs Ground Floor Living Area")
fig = sns.scatterplot(data=train, x='log_GrLivArea', y='log_SalePrice', hue = "MSZoning", palette="deep", style="Street")
experiment.log_figure(figure_name = "Log transform of Sales Price vs Ground Floor Living Area", figure=fig.figure, overwrite=False)

Ах, намного лучше! Кандидат на линейную регрессию.
Давайте поищем следующий лучший предсказатель, начнем с подвала.
plt.figure(figsize=(15,10))
plt.title("Sales Price vs Basement Area")
fig = sns.scatterplot(data=train, x='TotalBsmtSF', y='SalePrice', hue = "MSZoning", palette="deep", style="Street")
experiment.log_figure(figure_name = "Sales Price vs Basement Area", figure=fig.figure, overwrite=False)

Диаграмма рассеяния показывает интересную положительную зависимость и выброс в крайнем правом нижнем углу. Идентификация выбросов и обработка — неотъемлемая часть проекта машинного обучения.
Диаграмма продажных цен с общим качеством показывает все более положительную взаимосвязь. Здесь TotalQual — порядковая переменная, поэтому диаграмма рассеяния выглядит как очередь столбцов. Пожалуйста, обратитесь к коду и выводу ниже.
plt.figure(figsize=(15,10))
plt.title("Sales Price vs Overall Quality")
fig = sns.scatterplot(data=train, x='OverallQual', y='SalePrice', hue = "MSZoning", palette="deep", style="Street")
experiment.log_figure(figure_name = "Sales Price vs Overall Quality", figure=fig.figure, overwrite=False)

Мы также можем посмотреть на распределение переменной, используя блочную диаграмму. Коробчатая диаграмма — это стандартный способ определения квартилей и выбросов. Ниже приведен график продажных цен с указанием года постройки.
plt.figure(figsize=(25,15))
plt.title("Sales Price vs Year Built")
fig = sns.boxplot(data=train, x='YearBuilt', y='SalePrice')
plt.xticks(rotation=75)
experiment.log_figure(figure_name = "Sales Price vs Year Built", figure=fig.figure, overwrite=False)

Графики показывают, что цены продажи выше для недавно построенных и старинных домов.
Изоляция сложных выборок данных? Комета может это сделать. Узнайте больше о нашем сценарии PetCam и откройте для себя кометные артефакты.
Тепловые карты корреляции
Числовые переменные наделены такими показателями, как корреляция, которая показывает, связаны ли две величины (положительно или отрицательно) или нет.
plt.figure(figsize=(35,20))
plt.title("Correlation Heat Map")
fig = sns.heatmap(train.corr(), annot=True)
experiment.log_figure(figure_name = "Correlation Heat Map", figure=fig.figure, overwrite=False)

Тепловая карта — это распространенный способ представления корреляций, в котором используется матричная функция корреляции (.corr()) из библиотеки Pandas. Приведенная выше тепловая карта немного перегружена из-за большого количества переменных.
Давайте сузим наш поиск до сильно коррелированных переменных.
cols = list(train.corr().nlargest(5, 'SalePrice')['SalePrice'].index) + list(train.corr().nsmallest(5, 'SalePrice')['SalePrice'].index)
plt.figure(figsize=(15,10))
plt.title("Top 5 highly correlated variables - Correlation Heat Map")
fig = sns.heatmap(train[cols].corr(), annot=True)
experiment.log_figure(figure_name = "Top 5 highly correlated variables - Correlation Heat Map", figure=fig.figure, overwrite=False)

Выберите пять первых переменных с положительной и отрицательной корреляцией, вызвав функции nlargest() и nsmalest() соответственно в матрице корреляции.
Общее качество и жилая площадь сильно коррелируют с ценой дома.
Парные участки
Вы также можете определить взаимосвязь между независимыми переменными в одном снимке, используя парный график. Диагональ на парном графике показывает гистограмму, тогда как остальные ячейки представляют собой диаграммы рассеяния.
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
plt.figure(figsize=(15,10))
fig = sns.pairplot(train[cols])
plt.title("Pairplot distribution and Scatterplots")
experiment.log_figure(figure_name = "Pairplot distribution and Scatterplots", figure=fig.figure, overwrite=False)

Помимо ранее выявленных взаимосвязей, GrLivArea и TotalBsmtSF имеют слабую положительную взаимосвязь, что заслуживает дальнейшего изучения в ходе моделирования.
Определение пропущенных значений
При создании решения машинного обучения важно выявлять и обрабатывать отсутствующие значения. Вы бы не хотели, чтобы ваше решение зависело от переменных с большим количеством пропущенных значений, поскольку это может привести к плохим прогнозам в производственной среде.
total = train.isnull().sum().sort_values(ascending=False) percent = (train.isnull().sum()/train.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) missing_data.head(20)

Приведенный выше код идентифицирует переменные с одним или несколькими отсутствующими значениями, а приведенный ниже код удаляет столбцы с отсутствующими значениями.
train = train.drop((missing_data[missing_data['Total'] >= 1]).index,1) train.isnull().sum().max()
Вывод приведенного выше кода равен нулю, как и ожидалось.
Просмотр зарегистрированных визуализаций
Перейдите по ссылке эксперимента Comet и щелкните вкладку Графика. Здесь вы найдете все свои сюжеты в одном месте.

Красивый! Не так ли?
Вы можете легко использовать эти диаграммы и графики в своих отчетах.
Примечание. Не забудьте вызвать experiment.end() при использовании Jupyter Notebook.
Краткое содержание
В этом посте вы узнали о важности исследовательского анализа данных, а также кратко ознакомились с использованием Comet для беспрепятственной регистрации визуализаций между проектами и командами. Вы проанализировали данные о ценах на жилье по отношению к различным экзогенным переменным, таким как площадь, местоположение и другие объекты. Вы научились выбирать графики для одномерного, двумерного и многомерного анализа, а также познакомились с пакетом Seaborn.
Примечание редактора. Heartbeat — это интернет-издание и сообщество, созданное участниками и посвященное предоставлению лучших образовательных ресурсов для специалистов по науке о данных, машинному обучению и глубокому обучению. Мы стремимся поддерживать и вдохновлять разработчиков и инженеров из всех слоев общества.
Независимая от редакции, Heartbeat спонсируется и публикуется Comet, платформой MLOps, которая позволяет специалистам по данным и командам машинного обучения отслеживать, сравнивать, объяснять и оптимизировать свои эксперименты. Мы платим нашим авторам и не продаем рекламу.
Если вы хотите внести свой вклад, перейдите к нашему призыву к участию. Вы также можете подписаться на получение нашего еженедельного информационного бюллетеня (Еженедельник глубокого обучения), заглянуть в блог Comet, присоединиться к нам в Slack и подписаться на Comet в Twitter и LinkedIn для получения ресурсов и событий. и многое другое, что поможет вам быстрее создавать более качественные модели машинного обучения.