
Дерево решений — один из самых мощных алгоритмов контролируемого обучения, который используется как для классификации, так и для регрессии.
Интуиция
Этот алгоритм предполагает, что данные следуют набору правил, и эти правила идентифицируются с использованием различных математических методов.
В деревьях решений используются гиперплоскости, параллельные любой из осей, для разрезания системы координат. Каждая ось определяет функцию. Пунктирные линии — гиперплоскости. o и x - точки данных.

Дерево решений строит классификационные или регрессионные модели в виде древовидной структуры.
Как строится древовидная структура?
В дереве решений используется двоичный (каждый узел имеет двух дочерних элементов) или недвоичный древовидный граф (каждый узел имеет более двух дочерних элементов) для назначения целевые значения для каждой выборки данных. Целевые значения представлены в дереве листья(или листья). Чтобы добраться до листа, образец распространяется через узлы, начиная с корневого узла. В каждом узле принимается решение «к какому узлу-потомку он должен перейти?», эти узлы называются узлами принятия решений. Решение принимается на основе признака выбранного образца (атрибут признака).
Обучение дерева решений — это процесс поиска оптимальных правил в каждом узле решений в соответствии с выбранной метрикой.
Древовидная структура

Допустим, есть этот набор данных, затем набор данных разбивается на более мелкие ветви (поддерево), в то же время постепенно развивается связанное с ним дерево решений (посмотрите на правую сторону, дерево растет). Кстати, дерево решений может обрабатывать как категориальные, так и числовые данные.
Разве это не похоже на гигантскую структуру вложенных условий if-else?
Процесс построения дерева решений
Построение дерева решений представляет собой пошаговый процесс:
- Выбор функции: выберите функцию из функций обучающих данных в качестве стандарта разделения текущего узла. (Разные стандарты генерируют разные алгоритмы дерева решений.)
- Создание дерева решений. Создайте внутренний узел в перевернутом виде на основе выбранных функций и остановитесь, пока набор данных больше нельзя будет разделить.
- Сокращение. Дерево решений может легко стать переобученным, если не будет выполнена необходимая обрезка (включая предварительную и последующую обрезку) для уменьшения размера дерева и оптимизации его структуры узлов.
Алгоритмы построения дерева решений
Существует два популярных алгоритма, широко используемых для построения деревьев решений:
- CART (деревья классификации и регрессии) – используется индекс Джини (для классификации), редукция стандартного отклонения (для регрессии). как показатели.
- ID3 (итеративный дихотомайзер 3) — использует функцию энтропиии прирост информациив качестве показателей. .
Ключевые моменты построения дерева решений
Прежде чем мы начнем строить дерево решений, нам нужно задать правильные вопросы, например,
- Как решить, какую функцию следует считать корневым узлом?
- Как выбрать узлы решений и потомки узлов решений?
- Как определить критерии разделения функций?
Дерево решений для классификации
Ключевым этапом построения дерева решений является разделение данных всех атрибутов (функций/столбцов), сравнение наборов результатов с точки зрения «чистоты» и выбор атрибута с самой высокой "чистотой" в качестве точки данных для разделения набора данных. У нас есть две часто используемые метрики критериев разделения для количественной оценки чистоты.
- Энтропия и Получение информации
- Индекс Джини
Энтропия
Энтропия — мера беспорядка. Он измеряет непредсказуемость или загрязненность в системе. Ниже мы видим, когда красные и зеленые точки распределены по порядку, тогда энтропия низкая. Но когда в распределении есть случайность, энтропия высока.

- Для набора данных только с 1 классом выборки однородны (это означает, что все выборки похожи, принадлежат к одному классу), Энтропия будет 0.
- Для набора данных с двумя классами, когда нет примесей (все экземпляры принадлежат одному классу), энтропия становится 0. Когда примесь высока, что означает, что экземпляры каждого класса распределены поровну (по 50% каждый), энтропия равна 1. Ниже у нас есть график энтропии для вероятности класса «+», где есть 2 класса «+» и «-».

3. Для набора данных с более чем двумя классами энтропия может быть больше 1 для более высокой примеси и энтропия равно 0, когда загрязнение низкое.
математическое уравнение для измерения энтропии:

Pi,k – это соотношение экземпляров класса k среди обучающих экземпляров в i-м узле.
Энтропия для непрерывных переменных
Если вы заметили, до сих пор мы обсуждали энтропию для категориальных данных. Но мы сказали ранее, что дерево решений также используется для задач регрессии. Итак, как мы измеряем энтропию, когда данные непрерывны (числовые)? Посмотрим!
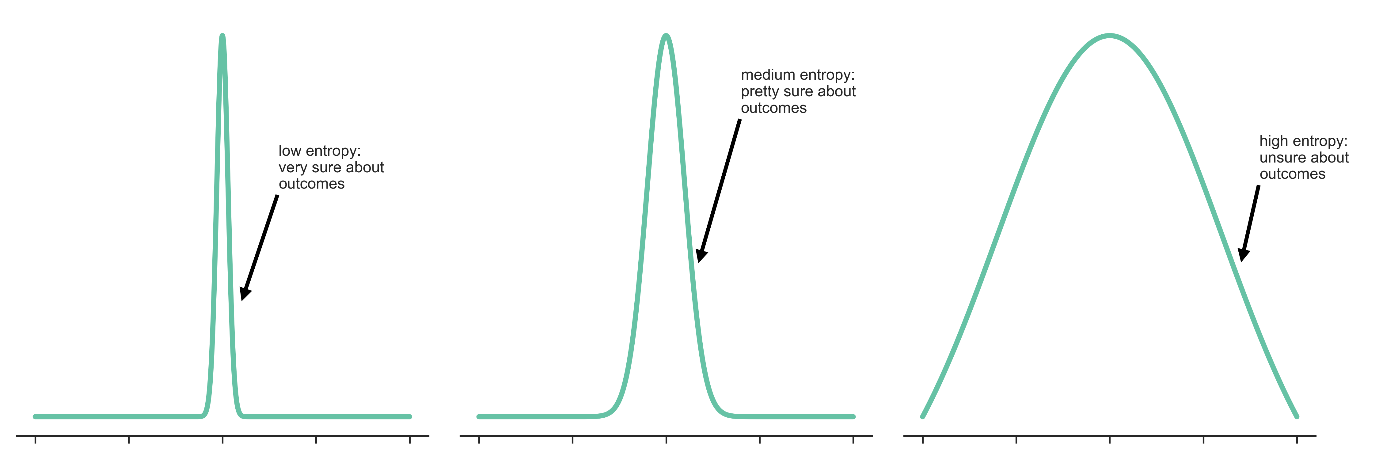
Посмотрите на этот kdeplot. широкое, однородное распределение, при котором мы в равной степени не уверены в вероятностях каждого исхода имеет большую неопределенность и, следовательно, имеет более высокую энтропию. И наоборот, распределение с очень узким пиком будет означать, что мы знаем с высокой вероятностью, каковы наши результаты, или, другими словами, они лежат в узком диапазоне, и поэтому мы более уверены, что указывает на то, что это распределение будет иметь низкую энтропию.
Чтобы построить дерево решений, нам нужно рассчитать два типа энтропии, используя таблицы частот следующим образом:
Шаг 1: Энтропия с использованием таблицы частот одного атрибута:
Вот таблица частот одного атрибута (целевой переменной), при вычислении мы получили Entropy = 0,94

Шаг 2: Энтропия с использованием таблицы частот двух атрибутов:

Прирост информации (IG)
Прирост информации — метрика для обучения деревьев решений. Этот показатель измеряет качество разделения. Прирост информации основан на снижении энтропии после разделения набора данных на основе атрибута. Нам нужно найти тот атрибут, который дает наибольший прирост информации (наиболее однородные ветви). Алгоритм дерева решений выполняет различные шаги для получения максимального IG.

Шаг 1: Рассчитайте энтропию родителя перед разделением. Из таблицы частот целевой переменной (игра в гольф) сначала вычисляется энтропия; Энтропия = 0,94
Шаг 2: Рассчитайте энтропию каждого дочернего элемента. Набор данных разделен на различные атрибуты (Солнечно, Пасмурно, Дождь) объекта (Прогноз). Затем вычисляется энтропия каждого атрибута.

Шаг 3: Рассчитайте взвешенную энтропию детей. Для функции (прогноз) вычисляется произведение энтропии (которую мы рассчитали на шаге 2) и вероятности каждого дочернего элемента. Затем вычисляется сумма всех произведений. Мы получили взвешенную энтропию детей. Взвешенная энтропия = 0,693
Шаг 4: Рассчитайте прирост информации. У нас есть уравнение получения информации, все, что нам нужно сделать, это подставить значения, которые мы получили на предыдущих шагах, в это уравнение.

Шаг 5: Рассчитайте IG получения информации для всех функций. Алгоритм вычисляет IG для всех функций и выбирает функцию с наибольшим IG в качестве узла принятия решения.

Посмотрите на изображения, мы видим, что самый высокий прирост информации у функции Outlook. Дерево решений выбирает функцию Outlook в качестве корневого узла.
На следующем шаге дерево решений делит набор данных на его ветви и повторяет тот же процесс для каждой ветви. Посмотрим, как!
Шаг 6: Рекурсивный поиск информации. Затем дерево решений применяет рекурсивный жадный алгоритм поиска сверху вниз, чтобы найти IG на каждом уровне дерева. Разделение прекращается, как только мы достигаем ветви с энтропией 0, эта ветвь является конечным узлом.

Окончательное дерево решений будет выглядеть так:

Примесь Джини
Примесь Джини, или индекс Джини, измеряет степень или вероятность того, что конкретная переменная будет неправильно классифицирована при случайном выборе.Он используется для определения того, как должны разделяться функции набора данных. узлы, образующие дерево. Формула примеси Джини:

Степень индекса Джини варьирует от 0 до 1,
- Где 0 означает, что все элементы относятся к определенному классу или существует только один класс.
- Индекс Джини, равный 1, означает, что все элементы случайным образом распределены по различным классам.
- Значение 0,5 означает, что элементы равномерно распределены по некоторым классам.

Нет большой разницы в деревьях решений, которые мы получаем из энтропии x`x` и примеси Джини. Но Gini в вычислительном отношении немного быстрее, чем Entropy. Джини полезен для больших наборов данных. Однако, когда они различаются, примесь Джини имеет тенденцию изолировать наиболее часто встречающийся класс в своей собственной ветви дерева, в то время как энтропия имеет тенденцию создавать несколько более сбалансированные деревья.
Гиперпараметры регуляризации
В деревьях решений древовидная структура адаптируется к обучающим данным, что приводит к переобучению модели на обучающих данных, и модель не может обобщить тестовый набор/данные. Чтобы избежать этой проблемы, степень свободы дерева решений должна быть ограничена во время обучения. Этот процесс называется регуляризацией. Гиперпараметры регуляризации зависят от типа алгоритма. В деревьях решений мы можем ограничивать глубину epth дерева, чтобы предотвратить переоснащение модели.Глубина дерева — это мера того, сколько расщепления может сделать дерево решений.
В Scikit-LearnDecisionTreeClassifier класс используется для построения дерева решений. Вот некоторые важные гиперпараметры, которые ограничивают свободу/форму дерева решений:
- max_depth (Максимальная глубина дерева. Если нет, то узлы расширяются до тех пор, пока все листья не станут чистыми или пока все листья не будут содержать выборок меньше, чем min_samples_split). Более низкое значение max_depth приводит к недостаточной подгонке, а более высокое значение приводит к переобучению.
- min_samples_split (минимальное количество сэмплов, которое должен иметь узел, прежде чем его можно будет разделить)
- min_samples_leaf (минимальное количество образцов, которое должен иметь конечный узел)
- min_weight_fraction_leaf (то же, что и min_samples_leaf, но выражается в виде доли от общего количества взвешенных экземпляров)
- max_leaf_nodes (максимальное количество конечных узлов)
- max_features (максимальное количество функций, которые оцениваются для разделения на каждом узле).
Увеличение гиперпараметров min_* или уменьшение гиперпараметров max_* приведет к упорядочению модели.

Вот два дерева решений, обученных на наборе данных. Слева дерево решений обучается с гиперпараметрами по умолчанию (без ограничений), а справа дерево решений обучается с min_samples_leaf=4. Мы видим, что левая модель переоснащает, тогда как правая модель лучше обобщает.
Дерево решений для регрессии
Деревья решений также способны выполнять задачи регрессии. Дерево регрессии очень похоже на дерево классификации. В отличие от проблемы классификации оценка целевой переменной в задаче регрессии является непрерывным значением, а не категориальным значением.
В следующей системе мы видим, что дерево решений сделало четыре разделения и разделило точки данных на пять групп.

Теперь этот алгоритм возьмет среднее значение каждой группы и на основе этих значений построит дерево решений для набора данных. Результирующее дерево будет выглядеть так,

Как работает дерево решений для регрессии?
Алгоритм ID3 (Итеративный дихотомайзер 3) можно использовать для построения дерева решений для регрессии, которое заменяет примесь Джини или энтропию и Получение информации с помощью снижения стандартного отклонения (SDR).
Уменьшение стандартного отклонения основано на уменьшении стандартного отклонения после разделения набора данных по атрибуту. Дерево будет разделено по атрибуту с более высоким SDR целевой переменной. Стандартное отклонение используется для измерения однородности (похожих значений) числовых выборок (целевой переменной). Математическая формула Уменьшения стандартного отклонения:

- Y — целевая переменная.
- X — это особый атрибут набора данных.
- SDR(Y,X) — это уменьшение стандартного отклонения целевой переменной Y с учетом информации X
- S(Y) — стандартное отклонение целевой переменной.
- S(Y,X) — стандартное отклонение целевой переменной с учетом информации X
Узел (независимая переменная), который имеет большее снижение стандартного отклонения, будет объявлен как узел решения. В первой итерации этот узел будет называться корневым узлом.
Если числовая выборка полностью однородна по независимой переменной (проверяем по каждой независимой переменной отдельно), то ее стандартное отклонение равно нулю.
Расчет S(Y,X) можно разбить по следующей формуле:

S(Y,X) — это сумма вероятности каждого из значений независимой переменной, умноженная на стандартное отклонение целевой переменной на основе этих значений независимой переменной. Здесь,
- S(c) — стандартное отклонение целевой переменной, основанное на уникальных значениях независимой переменной.
- P (c) - это число вероятности значения независимых переменных над общими значениями независимой переменной.
Признак с более высоким значением S(Y,X) — это признак, который имеет больше возможностей для объяснения изменений в целевой переменной, поэтому это признак, который алгоритм дерева решений будет использовать для разделения дерево.
Уменьшение дисперсии или уменьшение стандартного отклонения (SDR)
Дисперсия сообщает нам среднее расстояние всех точек данных от средней точки. Стандартное отклонение — это квадратный корень из дисперсии. Поскольку дисперсия рассчитывается в единицах, возведенных в квадрат, и, следовательно, чтобы получить значение, имеющее единицу, равную точкам данных, мы берем квадратный корень из дисперсии, который представляет собой стандартное отклонение. Математические формулы, которые нам нужны,

Стандартное отклонение представляет собой квадратный корень из среднеквадратичной ошибки (MSE).
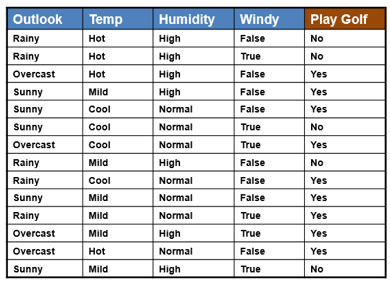
Давайте посмотрим пошаговый процесс построения дерева решений для регрессии. Здесь мы добавили новую функцию Часы игры в набор данных о погоде.

Шаг 1.Рассчитайте общее стандартное отклонение относительно целевой переменной перед разделением.

Коэффициент вариации используется в качестве критерия остановки для дальнейшего разделения.
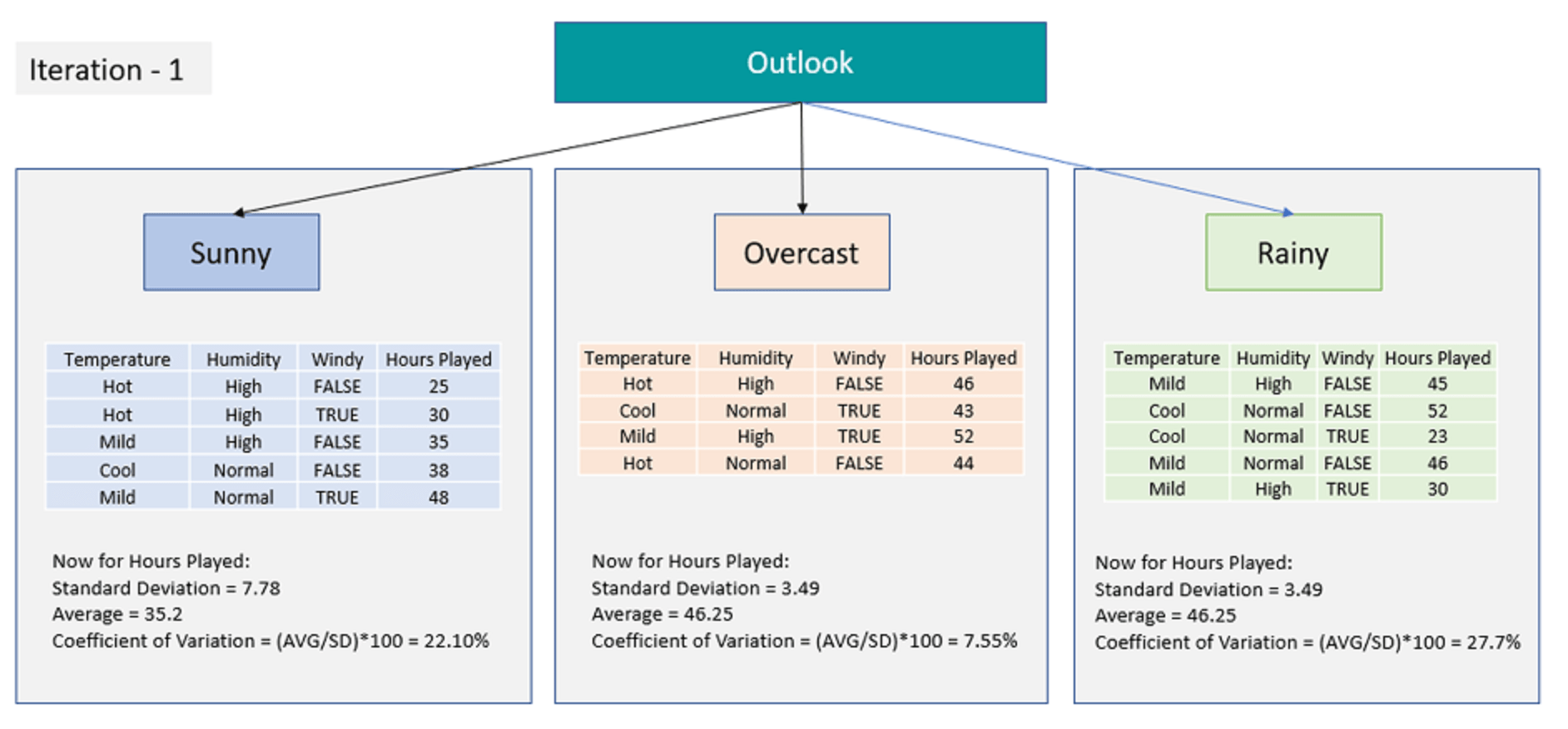
Шаг 2. Рассчитайте SDR относительно независимых переменных и выберите корневой узел, узлы решений и конечные узлы.
SDR для Outlook:

Точно так же, когда мы вычисляем SDR для всех атрибутов, мы получаем,

- SDR (часы, прогноз) = 1,66.
- SDR (часы, температура) = 0,39
- SDR (Часы, Влажность) = 0,09
- SDR (Часы, Ветер) = 0,39
Шаг 3. Определение корневого узла
Outlook имеет наибольшее снижение стандартного отклонения, поэтому Outlook будет корневым узлом.

Шаг 4: Набор данных делится на основе значений выбранного атрибута. Этот процесс выполняется рекурсивно на неконечных ветвях до тех пор, пока не будут обработаны все данные.
Для следующего узла нам нужны некоторые критерии завершения, например, когда прекратить разбиение. Следовательно, мы рассматриваем коэффициент дисперсии CV как один из критериев завершения и, например, можем установить CV = 10% в качестве порога. Итак, если у нас есть CV > 10%, то требуется дальнейшее разделение, иначе на этом остановимся. Или мы также можем установить пороговое значение количества точек данных (строк), если оно меньше или равно 3, тогда разделение не требуется.
Прогноз в листовом узле будет средним значением этой ветви. Здесь солнечные и дождливые узлы нуждаются в дальнейшем разделении, так как оба имеют CV > 10%. Однако облачность не нуждается в разделении, так как CV для облачности ‹= 10%.
Среднее значение пасмурной ветви = 46,25 будет прогнозом на пасмурном листе.

Теперь мы повторим ту же проверку SDR для данных, отфильтрованных для солнечных и дождливых дней, чтобы получить другие узлы решений и последующие конечные узлы.
Проверка SDR для строк данных Sunny
Посмотрите ниже: «Sunny» CV ветки (22,10%) › порог 10%, который требует дальнейшего разделения. Мы выбираем «Temp» как лучший узел после «Outlook», потому что он имеет самый большой SDR.

Поскольку количество строк для каждого горячего, мягкого и холодного ‹ 3, дальнейшее разделение не требуется.
Проверка SDR на наличие строк Rainy Data
«Дождливая» ветка имеет CV (22%) › порог 10%. Эта ветвь нуждается в дальнейшем расщеплении. Мы выбираем «Temp» как лучший узел, потому что он имеет самый большой SDR.

Поскольку количество точек данных для обеих ветвей (FALSE и TRUE) равно или меньше 3, мы останавливаем дальнейшее ветвление и назначаем среднее значение каждой ветви соответствующему конечному узлу.
Окончательное дерево решений для регрессии находится здесь,

Интерпретация дерева решений:
- Если Outlookсостояние равно Солнечно и Температура soft, то прогноз на количество часов, в течение которых может быть сыгран матч, составляет 41,5 часа независимо от других условий.
- Если для параметра Outlook задано значение Облачно, независимо от других условий прогноз составляет 46,25 часов.
- Если в Outlook дождьто, если ветрено тогда прогноз составляет 26,5 часов, а если нет ветра, прогноз составляет 47,6 часов.
Преимущества и недостатки деревьев решений
Преимущества
- Меньше предварительной обработки данных. В отличие от других алгоритмов машинного обучения, дерево решений не требует тщательной предварительной обработки данных.
- Нет нормализации. Дерево решений не требует нормализованных данных.
- Без масштабирования. Данные не нужно масштабировать перед их подачей в модель дерева решений.
- Не зависит от пропущенного значения — в отличие от k-ближайших соседей или других алгоритмов, основанных на расстоянии, на дерево решений не влияют пропущенные значения.
- Простота и интуитивность. Дерево решений является интуитивно понятным и довольно простым для понимания и объяснения основных свойств.
Недостатки
- Высокая чувствительность. Небольшое изменение данных может привести к высокой нестабильности модели дерева решений.
- Сложный расчет. В дереве решений используются более сложные вычисления по сравнению с другими моделями.
- Высокое время обучения. Для обучения дерева решений требуется больше времени. модель.
- Дороговитость.Модели на основе дерева решений требуют больше места и времени, поэтому требуют больших вычислительных ресурсов.
- Слабое качество. Одно дерево не может изучить большую часть данных, поэтому вы не получите хорошего предиктора, используя одно дерево решений. Вам нужно собрать большее количество деревьев решений, таких как Случайный лес, чтобы повысить точность прогноза.
Заключение
Деревья решений наиболее эффективны в машинном обучении. Поскольку они просты для понимания, они предпочтительнее других подходов к тем же проблемам. Можно использовать деревья решений для выполнения базовой сегментации клиентов и построения другой прогностической модели на сегментах.
В следующем блоге давайте посмотрим, как реализовать алгоритм дерева решений для задач классификации и регрессии с помощью Scikit-Learn.