
Полное руководство по Unicode
Каждый разработчик должен понимать Unicode.
Программное обеспечение пожирает мир, — заявил Марк Андриссен в 2011 году.
Возможность представления текста на любом из языков мира имеет решающее значение для современных приложений.
Стандарт Unicode предоставляет эту возможность, улучшая ранние наборы символов, такие как ASCII, которые игнорируют 94% неанглоязычных жителей мира.
Понимание Unicode является ключом к работе с текстом в современных цифровых системах.
Основы кодировки символов
Начнем с самого начала.
Не секрет, что все данные в компьютере хранятся в виде битов, обычно представленных единицами и нулями.
Чтобы представить число, мы просто преобразуем число в соответствующую ему форму с основанием 2 (двоичную).
Но как насчет текста?
Как мы представляем букву a или z, или даже смайлики вроде 😁?
Нам нужно сопоставление между символами и двоичными числами. Отображение определяет, как каждый символ может быть представлен в виде двоичного числа, которое может быть сохранено в памяти.
Набор сопоставлений между символами и двоичными значениями называется набором символов.
Другими словами, набор символов определяет, как набор символов кодируется в соответствующую двоичную форму.
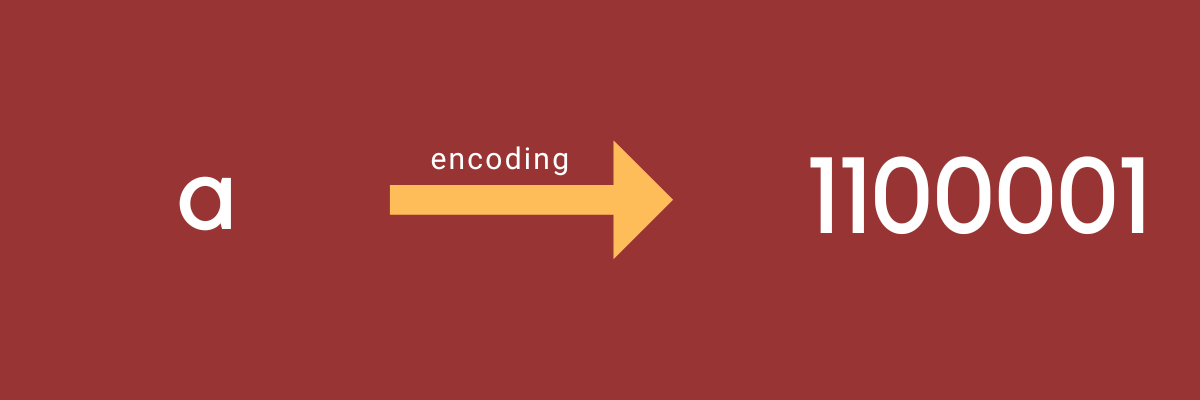
Компьютеры представляют цифровой текст, кодируя каждый символ как двоичную цифру. Набор символов определяет конкретную двоичную цифру, соответствующую конкретному символу. Процесс преобразования символа в двоичную цифру называется кодированием.
Существует много наборов символов/кодировок — разные наборы обычно используют разные схемы кодирования.
Но все они существуют по одной причине: чтобы преобразовать символы в удобные для компьютера двоичные цифры.
Существование множества наборов символов с разными схемами кодирования может быть проблематичным. Если два компьютера не согласны с общей схемой кодирования, двоичный вывод одного компьютера не может быть декодирован обратно в символ другим.
Когда компьютер не может распознать символ, большинство операционных систем используют фиктивный символ, обычно вопросительный знак в рамке, для представления неизвестного символа. Причина этого проста — компьютер не может декодировать двоичную форму в символ для отображения. Другими словами, он не распознает схему кодирования символа.
Что необходимо, так это стандартный набор символов, определяющий сопоставление, с которым согласны все компьютеры.
Чтобы буква a на одном компьютере была также a на другом компьютере. И не скажем 👙!
ASCII
Ранняя попытка создать стандартизированный набор символов привела к созданию Американского стандартного кода для обмена информацией, также известного как ASCII.
ASCII — это 7-битный (обычно 1 байт) набор символов, содержащий 128 символов. Символы основаны на английском алфавите.
Чтобы упростить математику, системы, поддерживающие ASCII, обычно сопоставляют каждый символ с 8 битами или 1 байтом [1].
Это дает ASCII хорошее свойство, заключающееся в том, что количество символов равно количеству байтов.
Но ASCII очень ограничен — его символы основаны на английском алфавите. Он полностью игнорирует символы других алфавитов, таких как китайский, арабский и кириллический.
Поскольку программное обеспечение начало выходить за пределы англоязычного мира, понадобился новый стандарт. Тот, который распознавал языки мира, сценарии и жажду смайликов.
Юникод
В ответ на ограничения ASCII был разработан стандарт Юникод.
Фон
Чтобы понять Unicode, важно правильно понимать терминологию.
В ASCII, в котором используется только английский алфавит, термин символ используется для определения атомарного, удобочитаемого символа.
Но в контексте неанглоязычных шрифтов, которые могут включать в себя слова с акцентом, сложные глифы и цветные смайлики, что на самом деле представляет собой персонаж?
Это a или á или даже a плюс модификатор ударения?
Чтобы устранить эту двусмысленность, Unicode вводит три термина; кодовая точка, графема и текст. Это позволяет нам точно идентифицировать различные текстовые атрибуты.
Во-первых, кодовая точка — это числовое представление конкретной элементарной единицы текстовой информации. Например, в Unicode буква a имеет кодовую точку U+0061, буква A имеет кодовую точку U+0041, а модификатор ударения имеет кодовую точку U+0769. Помните, что кодовая точка — это не то же самое, что символ — один удобочитаемый символ может состоять из нескольких кодовых точек.
Во-вторых, графема — это комбинация одной или нескольких кодовых точек, которая представляет собой единую графическую единицу, узнаваемую читателем. Например, буква é — это графема, состоящая из кодовых точек U+0101 и U+0769.
В-третьих, текст — это последовательность из одной или нескольких графем.
Другими словами, теперь у нас есть кодовые точки, представляющие атомарную единицу текстовой информации, мы комбинируем кодовые точки, чтобы получить графемы, то есть удобочитаемый символ, и мы комбинируем графемы, чтобы получить текст.
Остается последний кусочек головоломки юникода — как представить сами кодовые точки в двоичном виде?
Схемы кодирования Unicode
В ASCII мы используем простой подход, заключающийся в том, что один символ ASCII всегда отображается в один байт.
В Юникоде одна графема/символ Юникода может состоять из нескольких кодовых точек, а одна кодовая точка может быть представлена несколькими байтами. Это означает, что один удобочитаемый символ Юникода может варьироваться от одного байта до конкатенации многих байтов.
Хотя схема кодирования ASCII очень проста, нам нужно что-то более масштабируемое при работе с Unicode.
UTF-32
Распространенная схема кодирования кодовых точек Unicode известна как UTF-32.
В UTF-32 каждая кодовая точка отображается на 4 байта (32 бита).
Преимущество этой схемы заключается в ее простоте.
Каждый символ представлен одинаковым количеством байтов. Это означает, что текст легче анализировать, а размер текста легко оценить — просто подсчитайте количество графем/символов и умножьте на 4.
Однако за эту простоту приходится платить.
UTF-32 очень неэффективно использует память. Наиболее популярные символы, а именно символы английского алфавита, могут быть представлены одной 1-байтовой кодовой точкой. Использование UTF-32 означает, что такие символы должны быть дополнены 3 байтами бесполезных нулей, чтобы довести общее количество на символ до требуемых 4 байтов. Для стандартных символов ASCII это делает кодировку UTF-32 в 4 раза более расточительной, чем ASCII.
Нам нужно что-то получше.
UTF-8
Потребность в схеме кодирования, которая находится между экономичностью ASCII и излишествами UTF-32, привела к созданию UTF-8, которая стала одной из самых популярных схем кодирования кодовых точек Unicode [2].
В UTF-8 количество байтов, которым соответствует данная кодовая точка, является переменным — простыми кодовыми точками, такими как те, которые представляют карту английского алфавита в один байт. Самые большие кодовые точки соответствуют 4 байтам.
Это изменение размера одного символа означает, что синтаксический анализ строк в кодировке UTF-8 выполняется медленнее и сложнее.
Но это гарантирует, что текст всех видов будет представлен эффективным для памяти способом.
И это еще не самое лучшее.
В UTF-8 первые 126 символов имеют те же значения однобайтовых кодовых точек, что и соответствующие значения ASCII. Это означает, что UTF-8 обратно совместим — любой текст ASCII является допустимым текстом UTF-8.
Инженеры во всем мире могут вздохнуть с облегчением, что их раннее игнорирование интернационализации не будет наказано.
Краткое содержание
Вот краткое изложение того, что вам нужно знать.
На самом базовом уровне компьютеры понимают только биты. Эти биты не имеют внутреннего значения. Для представления текста нам нужна кодировка. Схема кодирования определяет, как каждый удобочитаемый символ, который мы хотим использовать, сопоставляется с уникальной последовательностью битов. Набор всех символов и соответствующих им кодировок представляет собой набор символов.
ASCII — это простой набор символов для английского алфавита, в котором один символ представлен одним байтом.
Юникод — это более широкий набор символов, который можно использовать для представления любого существующего символа. Он определяет набор кодовых точек, которые можно комбинировать для формирования удобочитаемых символов, т. е. графем. Кодовые точки кодируются чаще всего по схеме UTF-8, где количество символов не обязательно равно количеству байтов (это верно только для первых 126 символов ASCII).
Юникод в дикой природе
Итак, это теория. Но как насчет практики?
Критической частью этого является то, что языки программирования манипулируют строками на уровне байтов. Это означает, что очень важно знать используемую схему кодирования и то, как разные языковые конструкции могут по-разному взаимодействовать с текстом.
Читайте дальше, чтобы узнать, как Unicode используется в дикой природе: Байты, руны и строки: как кодировки символов работают в Go.
Примечания
[1] - Большинство компьютеров используют 8-битную систему, так как проще представить степень числа 2.
Первоначально опубликовано на https://yusufbirader.com 23 ноября 2022 г.