В соавторстве с Цянь Бао
Численное моделирование и компьютерная графика обычно включают обнаружение столкновений большого количества частиц (во многих случаях миллионов частиц). Обычные операции, такие как перемещение частиц и обработка границ, могут выполняться с временной сложностью O(N) (N означает количество частиц). Но сложность обнаружения столкновений может легко возрасти до O(N²), если не будет проведена оптимизация, что создаст алгоритмическое узкое место. Широко используемый метод - поиск окрестностей на основе сетки. Ограничив поиск склонных к столкновениям частиц небольшой областью, мы можем уменьшить вычислительную сложность обнаружения столкновений до O(N). В этой статье в качестве примера рассматривается решатель минимального 2D-метода дискретных элементов (DEM) и представлена высокоэффективная реализация поиска по окрестностям с использованием структур данных Taichi.
Что такое ДЭМ
ЦМР — это семейство численных методов, позволяющих рассматривать большое количество твердых тел как неконтинуум и моделировать их движение в соответствии с законами движения Ньютона. ЦМР можно применять к различным сценариям, таким как геотехническая инженерия, производство продуктов питания и науки о Земле, если они дополняются различными моделями материалов и контактной механики.
Поясню: авторы не являются экспертами в области ЦМР. В этой статье представлен общий подход к ускорению обнаружения столкновений. Не стесняйтесь обращаться к нам, если обнаружите, что мы ошиблись или упустили важную информацию.

Типичное моделирование ЦМР проходит следующие этапы:

Поскольку во время этого процесса могут произойти столкновения между любыми двумя случайными частицами, нам нужно покрыть O(N²) пар зерен на шаге 2 для обнаружения столкновений, что создает большую вычислительную нагрузку и может сыграть решающую роль. в общей алгоритмической производительности. Хорошая новость заключается в том, что мы можем уменьшить временную сложность этого шага до вычисления O(N) с помощью соответствующего алгоритма ускорения, и это то, чего мы хотим достичь в этой статье. Учитывая, что частица всегда окружена ограниченным числом соседей, нам нужен алгоритм, который может задействовать именно ближайших соседей для обнаружения столкновений.
Для тех, кто хочет пропустить нижеследующую разработку и разобраться в нашей реализации напрямую, ознакомьтесь с исходным кодом, который содержит менее 200 строк кода.
Основываясь на нашей реализации, вы можете дополнительно оптимизировать ее и добавить дополнительные функции для создания собственного моделирования ЦМР в реальном времени для десятков тысяч частиц на базе ЦП или ГП.
В следующих разделах сначала представлена реализация грубой силы, которая обходит O(N²) пар по всему миру. Затем мы предлагаем основанный на сетке метод обнаружения столкновений для ускорения вычислений, используя статическое выделение памяти вместо традиционного динамического подхода. Наконец, мы распараллеливаем процесс и добиваемся производительности в сотни раз быстрее, чем исходная версия грубой силы.
Примечание. Taichi также может легко распараллелить динамическое выделение памяти на процессорных и графических процессорах. Вы можете обратиться к этот документ для получения дополнительной информации. Мы также можем применить динамический подход к алгоритму ускорения, приведенному в этой статье, но это потребует дополнительных затрат.
Столкновения частиц в контексте ЦМР

На картинке выше показано падение 8192 твердых частиц. Обнаружение столкновений требует от нас локализации всех частиц, соприкасающихся со случайной частицей. Чтобы лучше сосредоточиться на обнаружении столкновений, мы делаем следующие предположения:
- Все частицы, участвующие в вычислении, имеют круглую форму, но разного диаметра.
- После столкновения учитывается только нормальное напряжение между частицами, а тангенциальная сила не учитывается.
- Деформация частиц не учитывается.
- Учитывается поступательное движение частиц, а угловой момент не учитывается.
Для начала нам нужно @ti.dataclass для представления частиц.
@ti.dataclass
class Grain:
p: vec # position
m: ti.f32 # mass
r: ti.f32 # radius
v: vec # velocity
a: vec # acceleration
f: vec # forces
Мы можем создать одномерное StructField с n элементами, чтобы собрать все частицы в вычислительной области:
gf = Grain.field(shape=(n, ))
Теперь мы приступаем к части обнаружения столкновений. Мы можем сказать, произошло ли столкновение, по расстоянию между двумя частицами и их радиусам:

def resolve(i, j):
rel_pos = gf[j].p - gf[i].p
dist = ti.sqrt(rel_pos[0]**2 + rel_pos[1]**2)
delta = -dist + gf[i].r + gf[j].r # delta = - d + r1 + r2
if delta > 0: # If delta > 0, a collision occurs
normal = rel_pos / dist
f1 = normal * delta * stiffness
# Details of the calculation are not included here
Однако как найти все частицы, взаимодействующие со случайной частицей gf[i]?
Самый простой способ — перебрать все остальные частицы в gf, кроме gf[i], и изучить любое возможное столкновение с gf[i]:
# Brute-force detection
for i in range(n):
for j in range(i + 1, n):
resolve(i, j)
Обратите внимание, что здесь мы гарантируем i < j, чтобы исключить повторное обнаружение столкновений между одними и теми же парами частиц. Например, для двух частиц gf[2] и gf[3] эта программа будет вычислять только resolve(2, 3) и исключать resolve(3, 2). Однако этот подход должен проходить через сотни миллионов пар частиц, когда количество задействованных частиц превышает 10 000, что приводит к невыносимо низкой производительности. Можем ли мы сузить область поиска для обнаружения столкновений и повысить эффективность алгоритма? В следующем разделе представлен вариант ускорения за счет разумного использования структур данных Taichi.
Ускорение обнаружения столкновений с помощью структур данных Taichi
Проблема реализации грубой силы заключается в большой области обнаружения, покрывающей всю вычислительную область. В идеале мы хотим задействовать только окружающие частицы данного объекта. Распространенным методом сужения области поиска является разделение вычислительной области на фиксированную сетку. Таким образом, нам нужно только исследовать клетки 3 х 3 с данной частицей в центре. Здесь нужно сделать одну оговорку: длина стороны ячейки должна быть больше диаметра частиц; в противном случае нам нужно немного расширить область поиска до 5x5 ячеек или даже больше.

Обычно мы используем здесь динамическое выделение памяти для записи идентификаторов частиц в ячейке, поскольку количество частиц в каждой ячейке постоянно изменяется. Но неизбежно, что динамический подход влечет за собой большие накладные расходы на GPU. Можем ли мы обеспечить запись и отслеживание с помощью статического размещения?
Что ж, это возможно — со статическим контейнером данных Taichi ti.field. Создайте поле particle_id для хранения идентификаторов частиц.
После разделения вычислительной области на сетку мы используем grid_idx, двухбитный целочисленный вектор, для представления ячейки, в которой находится частица, и используем grain_count для обозначения количества частиц в ячейке.
grain_count = ti.field(dtype=ti.i32,
shape=(grid_n, grid_n),
name="grain_count")
for i in range(n):
grid_idx = ti.floor(gf[i].p * grid_n, int)
grain_count[grid_idx] += 1


Затем мы хотим вычислить идентификаторы частиц (т. е. particle_id) в каждой из ячеек. Если particle_id представляет собой двумерный связанный список, элемент может добавляться динамически, как показано в следующем фрагменте кода, который может быть знаком пользователям Python/Taichi:
particle_id[cell_x, cell_y].append(gf[i]) # Append a particle in a dynamic way ti.append(particle_id[cell_x, cell_y], i) # Taichi's dynamic SNode feature supports appending at runtime and automatically allocates memory
Чтобы избежать дорогостоящих накладных расходов из-за динамического параллельного распределения памяти на графическом процессоре, мы хотим заранее зарезервировать местоположения частиц в particle_id.

Как показано на изображении выше, мы можем записывать индексы частиц в области поиска, используя одномерное поле particle_id, форма которого равна общему количеству частиц. Суть в том, что мы должны точно определить начальную и конечную позиции каждой ячейки в particle_id.
Мы можем разбить particle_id одним из следующих двух способов — сериализованным или параллельным.
Сериализованное разбиение particle_id
Мы используем три списка для хранения начального и конечного индексов каждого раздела в particle_id:
s = 0
ti.loop_config(serialize=True)
for i in range(grid_n):
for j in range(grid_n):
linear_idx = i * grid_n + j
list_head[linear_idx] = s
list_cur[linear_idx] = s
list_tail[linear_idx] = s + grain_count[i, j]
s += grain_count[i, j]
Приведенный выше фрагмент кода сохраняет начальную и конечную позиции раздела в list_head и list_tail соответственно, в зависимости от количества частиц в каждой ячейке (как задано grain_count). Поскольку результат вычисления каждого раздела зависит от s — результата предыдущего раздела, мы должны установить ti.loop_config(serialize=True) для сериализации программы.
На основе количества частиц, показанного на изображении выше, мы получаем следующие списки:
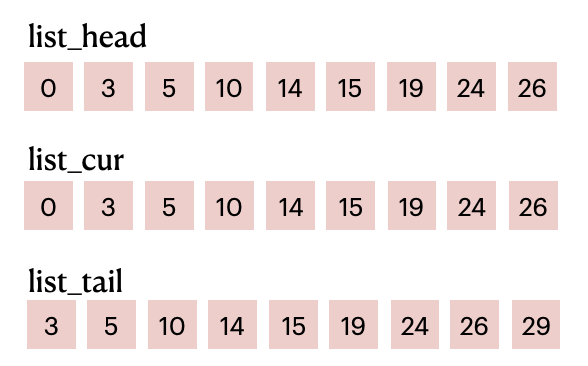
list_head и list_tail вместе делят particle_id на M частей (M равно количеству ячеек). Например, элементы в диапазоне от [0, 3) до particle_id представляют идентификаторы частиц в первой ячейке; элементы в диапазоне [3, 5) представляют идентификаторы частиц во второй ячейке; И так далее.
Параллельное разбиение particle_id
Когда задействовано больше ячеек (скажем, сетка 200 x 200 или даже больше), рабочая нагрузка последовательного выполнения приведенного выше фрагмента кода может стать узким местом в производительности. Основное препятствие для распараллеливания программы заключается в s, представляющей собой сумму префиксов, элементы которой необходимо обрабатывать последовательно. Чтобы уменьшить последовательную рабочую нагрузку, мы можем создать column_sum для хранения суммы частиц в каждом столбце, прежде чем использовать его для вычисления суммы 2D-префикса prefix_sum, значение которой равно s в каждом цикле. Таким образом, нам удается распараллелить все этапы вычислений, кроме начальной ячейки каждого столбца в prefix_sum.
column_sum = ti.field(dtype=ti.i32, shape=grid_n, name="column_sum")
prefix_sum = ti.field(dtype=ti.i32, shape=(grid_n, grid_n), name="prefix_sum")
@ti.kernel
def contact():
...
# Compute column sum in parallel
for i in range(grid_n):
sum = 0
for j in range(grid_n):
sum += grain_count[i, j]
column_sum[i] = sum
# Compute the beginning cell of each column of prefix_sum in SERIAL
prefix_sum[0, 0] = 0
ti.loop_config(serialize=True)
for i in range(1, grid_n):
prefix_sum[i, 0] = prefix_sum[i - 1, 0] + column_sum[i - 1]
# Compute the rest of perfix_sum in parallel
for i in range(grid_n):
for j in range(grid_n):
if j == 0:
prefix_sum[i, j] += grain_count[i, j]
else:
prefix_sum[i, j] = prefix_sum[i, j - 1] + grain_count[i, j]
Мы по-прежнему берем те же 3 x 3 ячейки, например. Ниже приведена визуализация grain_count, column_sum и prefix_sum, полученная из приведенного выше фрагмента кода:

Создайте параллельный связанный список на основе prefix_sum:
for i in range(grid_n):
for j in range(grid_n):
linear_idx = i * grid_n + j
list_head[linear_idx] = prefix_sum[i, j] - grain_count[i, j]
list_cur[linear_idx] = list_head[linear_idx]
list_tail[linear_idx] = prefix_sum[i, j]

Что наиболее важно, связанный список больше не зависит от результата предшествующего шага вычисления, а может обрабатываться параллельно.
До сих пор мы продемонстрировали два способа разбиения particle_id, посредством последовательного и параллельного выполнения соответственно. Они служат той же цели, несмотря на более низкую производительность последовательного подхода. Теперь мы готовы заполнить идентификаторы частиц и провести обнаружение столкновений.
Заполнение particle_id и поиск по соседству
Фрагмент кода ниже показывает, как мы заполняем particle_id, контейнер данных для индексации идентификаторов частиц. Основываясь на grid_idx, который помогает нам найти частицу в вычислительной области, мы можем получить ее местоположение в particle_id (обозначается grain_location) и сохранить ее индекс i:
for i in range(n):
grid_idx = ti.floor(gf[i].p * grid_n, int)
linear_idx = grid_idx[0] * grid_n + grid_idx[1]
grain_location = ti.atomic_add(list_cur[linear_idx], 1)
particle_id[grain_location] = i
Мы видим, что значение list_cur увеличивается на 1 каждый раз, когда добавляется частица из-за ti.atomic_add. В ходе этого процесса list_cur постепенно перемещается с list_head на list_tail. Другими словами, list_cur служит задним указателем каждой ячейки.

После заполнения particle_id мы можем искать соседей данной частицы. grid_idx помогает сузить область поиска до 3 x 3 = 9 ячеек, окружающих частицу, а resolve(i, j) перебирает все частицы в области, значительно снижая вычислительную нагрузку по сравнению с методом грубой силы и эффективно повышая производительность обнаружения столкновений на основе ЦМР. .
# Grid-based fast collision detection
for i in range(n):
grid_idx = ti.floor(gf[i].p * grid_n, int)
x_begin = max(grid_idx[0] - 1, 0)
x_end = min(grid_idx[0] + 2, grid_n)
y_begin = max(grid_idx[1] - 1, 0)
y_end = min(grid_idx[1] + 2, grid_n)
for neigh_i in range(x_begin, x_end):
for neigh_j in range(y_begin, y_end):
neigh_linear_idx = neigh_i * grid_n + neigh_j
for p_idx in range(list_head[neigh_linear_idx],
list_tail[neigh_linear_idx]):
j = particle_id[p_idx]
if i < j:
resolve(i, j)

Мы запускаем программу моделирования ЦМР, включающую 32 768 частиц, для оценки производительности. С предложенным нами решением для ускорения программа почти достигла симуляции в реальном времени (достигнув 25 кадров в секунду) на Macbook M1, в десятки или даже сотни раз быстрее, чем реализация грубой силы.
Заключение
В этой статье показано, как реализовать обнаружение столкновений в Taichi на основе минимальной модели ЦМР. Структуры данных Taichi при правильном использовании могут значительно ускорить поиск соседей; чем больше частиц задействовано, тем выше будет коэффициент ускорения. Более того, вам не потребуется много усилий, чтобы подобрать Taichi — ключевая часть алгоритма ускорения выполняется менее чем в 40 строках кода.
Чтобы кратко обобщить наш подход, мы разделяем вычислительную область на сетку и сохраняем идентификаторы частиц в соответствии с их пространственным расположением. Мы также предоставляем два способа разделения particle_id, т. е. сериализацию и распараллеливание. Полный код доступен по адресу https://github.com/taichi-dev/taichi_dem.
Задача оптимизации Taichi DEM
Поскольку это всего лишь минимальный решатель, есть много возможностей для оптимизации. Например:
- Еще вдвое уменьшите область поиска соседства;
- Учитывать поступательное движение и неправильную форму частиц;
- Реализовать те же функции с помощью динамических SNodes Taichi, поскольку Taichi поддерживает динамические структуры данных на GPU (taichi_elements — хороший справочник);
- Примените тот же подход для ускорения метода жидкости на основе положения (PBF).
- Распараллелить всю программу, используя
ti.atomic_add - Обновите демоверсию до 3D
- …
К нашей радости, после того как мы выпустили исходный код, многие участники сообщества проявили большой интерес и поделились с нами своими оптимизированными версиями. Мы восхищались их творчеством и изощренным использованием Taichi. Ниже приведены некоторые избранные материалы сообщества.
- Denver Pilphis и MuGdxy добавили в решатель 11 новых функций, включая обновление до 3D и введение сложных контактных моделей ЦМР.

- Linus-Civil реализовал молниеносно быстрый алгоритм параллельного поиска соседей на базе графических процессоров и работал со сложной геометрией для обработки границ.
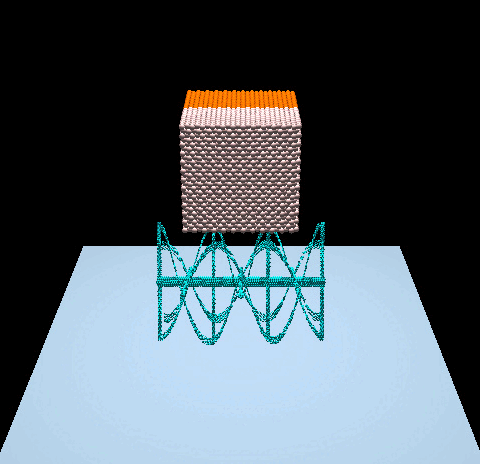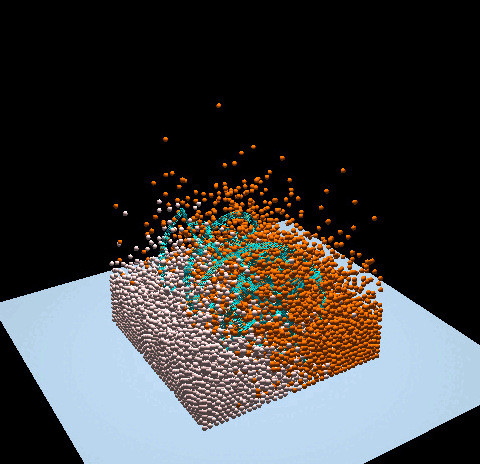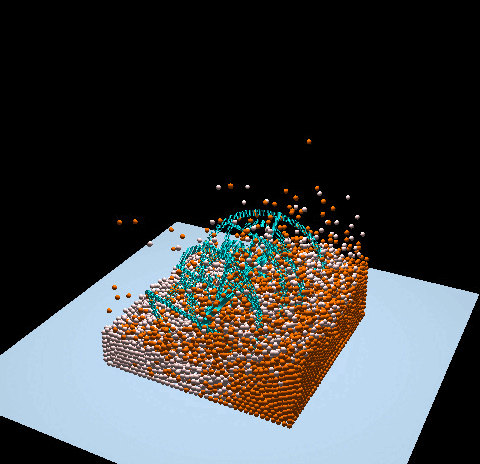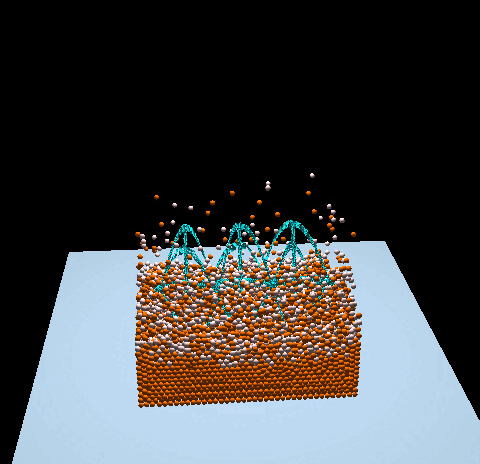
- Вдохновленный фильмом Мастер тайцзи, mrzhuzhe создал эту красивую симуляцию песчаного шара, реализовав поиск окрестностей с помощью атомарных замков, PBF (жидкостей на основе положения) и системы Taichi Snode.

Если у вас есть какие-либо вопросы или вы хотите поделиться с нами своими проектами DEM, присоединяйтесь к нашему слабому каналу или разместите свои идеи на сабреддите taichi_lang!