Введение
Обучение с временной разницей (TD Learning) является одной из центральных идей в обучении с подкреплением, поскольку оно находится между методами Монте-Карло и динамическим программированием в спектре различных методов обучения с подкреплением.
В этой статье мы подробно рассмотрим обучение с разницей во времени и увидим, почему оно оказалось одной из самых фундаментальных идей в обучении с подкреплением.
Мы начнем наше исследование с обсуждения проблемы предсказания (оценки политики), а затем исследуем проблему управления (поиск оптимальной политики).
Прогноз TD
Как мы видели для методов Монте-Карло, прогнозирование относится к проблеме оценки значений состояний, значение состояния является показателем того, насколько хорошо это состояние для агента в данной среде, чем выше значение состояния, тем лучше быть в таком состоянии.
Монте-Карло и обучение с временной разницей похожи в том смысле, что они оба используют реальный опыт для оценки данной политики, однако методы Монте-Карло ждут, пока не станет известно возвращение после посещения, которое после окончания эпизода доступно для обновления. значение состояния, в то время как методы TD обновляют значение состояния на следующем временном шаге, на следующем временном шаге t+1 они немедленно формируют цель и делают полезное обновление, используя наблюдаемое вознаграждение.


Обновление значения состояния сразу после одного временного шага называется одношаговым TD или TD(0), что является частным случаем методов TD(лямбда) и n-шагового TD, которые выходят за рамки однако из нашего обсуждения принципы, которые мы здесь исследуем, могут быть распространены на эти методы без особых сложностей.

Как мы видим, TD(0) основывает свое обновление на существующей оценке следующего значения состояния, из-за чего известно, что это метод самозагрузки.
Говорят, что методы временной разницы сочетают выборку Монте-Карло с начальной загрузкой DP, потому что в методах Монте-Карло целью является оценка, поскольку мы не знаем фактического ожидаемого значения, а используем выборку возврата из этого конкретного эпизода, а в DP эта цель является оценкой, потому что значение следующего состояния неизвестно, вместо этого используется текущая оценка, а в TD цель является оценкой по обеим причинам, она выбирает ожидаемые значения и использует текущую оценку вместо истинное значение состояния.
В уравнении обновления TD количество в скобках является мерой ошибки, измеряя разницу между оценочным значением St и лучшей оценкой на следующем временном шаге. Эта величина называется ошибкой TD и широко распространена во всех методах обучения с подкреплением.
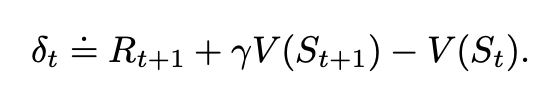
Методы TD используют самонастройку, то есть они извлекают догадку из догадки, но хорошо ли это делать? Однозначный ответ на этот вопрос не очень прост и является предметом текущих исследований, однако, мы можем привести некоторые аргументы, почему методы TD имеют определенные преимущества.
Методы TD имеют преимущество перед методами DP в том, что они не требуют модели среды, ее вознаграждения и распределений вероятностей следующего состояния, аналогично методы TD имеют преимущество перед методами Монте-Карло, поскольку они естественным образом реализуются в онлайн, полностью пошаговая мода. В методах Монте-Карло нужно дождаться конца эпизода, потому что только тогда известен возврат, тогда как в методах TD нужно дождаться только одного шага по времени.
Кроме того, методы TD доказали свою надежность и гарантируют сходимость. Для любой фиксированной политики p было доказано, что TD(0) сходится к оптимальному значению с вероятностью 1, если параметр размера шага (альфа) уменьшается в соответствии с обычным стохастическим приближением условия.
Давайте теперь рассмотрим, как можно использовать методы TD для решения задачи управления.
ТД контроль
Проблема управления относится к проблеме оценки оптимальной политики, так как в методах Монте-Карло мы используем итерацию обобщенной политики для решения проблемы управления и аналогичным образом сталкиваемся с тем же компромиссом между эксплуатацией и разведкой, в качестве решения которого наш подход попадает либо двух категорий: по политике и вне политики.
Давайте начнем нашу дискуссию с рассмотрения дела о политике.
SARSA: контроль TD в соответствии с политикой
Нам нужно изучить функцию «действие-значение», а не функцию «состояние-значение», то есть нам нужно рассмотреть переходы от одной пары «состояние-действие» к другой паре «состояние-действие» и изучить значения пар «состояние-действие».

Однако теоретически оба сценария являются цепями Маркова и, следовательно, идентичны, нам просто нужно применить один и тот же алгоритм для значений действия.

Поскольку это правило использует каждый элемент пятерки событий (St, At, Rt+1, St+1, At+1), этот алгоритм называется SARSA.
Сарса сходится с вероятностью 1 к оптимальной политике и функции действия-ценности, если все пары состояние-действие посещаются бесконечное число раз и политика сходится в пределе к жадной политике.
На этом мы завершаем обсуждение варианта использования в соответствии с политикой, давайте теперь обсудим метод вне политики.
Q-learning: управление TD вне правил
Q-обучение можно описать как алгоритм управления TD вне политики, определяемый:

Q-обучение напрямую аппроксимировало функцию оптимальных значений действий, не зависящую от применяемой политики. Это обеспечивает раннюю сходимость, которая была доказана, однако для правильной сходимости алгоритма нам необходимо посетить/обновить все пары, хотя это не является нетривиальным требованием в том смысле, что любой метод, который намеревается найти функцию оптимального значения, потребуется чтобы удовлетворить этому требованию, однако при этом предположении было показано, что Q-обучение сходится с вероятностью 1 к функции оптимальных значений действия
На этом мы завершаем обсуждение нестандартных методов, а также использование методов TD для решения проблемы управления.
Заключение
В этой статье мы рассмотрели метод обучения, называемый обучением с временной разницей, и увидели, как его можно применять как к задачам прогнозирования, так и к задачам управления в обучении с подкреплением.
Методы TD являются наиболее широко используемыми методами обучения с подкреплением. Вероятно, это связано с их большой простотой: их можно применять онлайн с минимальным объемом вычислений для получения опыта, полученного в результате взаимодействия с окружающей средой; их можно почти полностью выразить с помощью отдельных уравнений, которые можно реализовать с помощью небольших компьютерных программ.
Чтобы получить более глубокие знания о различных концепциях обучения с подкреплением, прочитайте эту замечательную книгу — Обучение с подкреплением: введение Ричарда Саттона и Эндрю Барто, которая также послужила основным источником вдохновения для этой статьи. .