Понимание и создание N-грамм для обработки естественного языка (NLP) с библиотекой Python NLTK

При обработке естественного языка (NLP) мы обучаем модели, чтобы компьютеры могли понимать текст и произносимые слова так же, как люди. Человеческий язык полон двусмысленностей, таких как омонимы, омофоны, сарказм, идиомы, метафоры и грамматика, что усложняет обучение моделей, которые точно определяют предполагаемое значение текста.
НЛП включает в себя несколько задач, некоторые из которых могут включать:
- Распознавание речи.
- Тегирование части речи.
- Анализ настроений.
- Генерация естественного языка.
Python предоставляет Natural Language Toolkit (NLTK),который представляет собойколлекцию библиотек с открытым исходным кодом для выполнения задач НЛП.
В этой статье мы обсудим N-граммы, способ помочь машинам понять значение слов и научиться их реализовывать с помощью Python NLTK.
Что такое n-граммы?
Языковые модели часто оценивают распределение вероятностей последовательностей слов. Со случайными длинами последовательностей это огромная задача. Таким образом, предполагается, что вероятность слова зависит только от предшествующих ему N слов. Это называется моделью языка N-грамм.
Таким образом, N-граммы представляют собой тип статистической языковой модели, используемой в обработке естественного языка (NLP) для прогнозирования возможности последовательности слов. N-грамма — это непрерывная серия из n элементов заданного образца текста, где n — количество элементов в последовательности.
Классификация n-грамм
У нас есть несколько классификаций n-грамм, в зависимости от числа, которое представляет n. Наиболее часто используемые n-граммы:
- N-грамм размера 1,
n= 1, является униграммой. - N-грамм размера 2,
n= 2, является биграммой. - N-грамм размера 3,
n= 3, является триграммой.
N-грамма может быть любой длины, n и разные типы n-грамм подходят для разных приложений.
Мы можем быстро и легко генерировать n-граммы с помощью функции ngrams, доступной в файле nltk.util module. Давайте посмотрим, как вышеприведенные n-граммы будут выглядеть, если реализовать их со следующим предложением:
«Обработка естественного языка с помощью N-грамм — это невероятно круто».
from nltk.util import ngrams sentence = "Natural Language Processing using N-grams is incredibly awesome." def generate_n_grams(sentence, n): unigrams = ngrams(sentence.split(), n) return [unigram for unigram in unigrams]
Для Unigrams n = 1 сохраняет этот текст в токенах из 1 слова:
# n = 1
generate_n_grams(sentence, 1)
# Results
('Natural',)
('Language',)
('Processing',)
('using',)
('N-grams',)
('is',)
('incredibly',)
('awesome.',)
Для Bigrams n = 2 сохраняет этот текст в токенах из 2 слов:
# n = 2
generate_n_grams(sentence, 2)
# Results
('Natural', 'Language')
('Language', 'Processing')
('Processing', 'using')
('using', 'N-grams')
('N-grams', 'is')
('is', 'incredibly')
('incredibly', 'awesome.')
Для триграмм n = 3 сохраняет этот текст в токенах из 3 слов:
# n = 3
generate_n_grams(sentence, 3)
# Results
('Natural', 'Language', 'Processing')
('Language', 'Processing', 'using')
('Processing', 'using', 'N-grams')
('using', 'N-grams', 'is')
('N-grams', 'is', 'incredibly')
('is', 'incredibly', 'awesome.')
Когда n > 3, мы называем их четырьмя граммами или пятью граммами и так далее.
Применение n-грамм в НЛП
- Мы можем использовать их для создания функций из текстового корпуса для алгоритмов машинного обучения, таких как SVM, Naive Bayes и т. д.
- Они помогают развивать такие функции, как:
— Автозамена
— Автодополнение предложений
— Обобщение текста
— Распознавание речи
— Поиск в словаре
— Сжатие текста
— Идентификация языка и т. д.
Давайте теперь возьмем набор данных и используем его для создания n-грамм и продемонстрируем, как мы можем использовать их в НЛП.
Какие советы дают известные компании студентам и стартапам? Мы попросили их! Прочитайте или посмотрите наши отраслевые вопросы и ответы, чтобы получить советы от команд из Стэнфорда, Google и HuggingFace.
Пошаговый подход к созданию n-грамм
В этом разделе мы рассмотрим пошаговую подготовку данных для создания n-грамм.
Набор данных
Во-первых, нам понадобится набор данных. Мы будем использовать данные Financial Sentiment Analysis от Kaggle. Набор данных содержит два поднабора данных (FiQA и Financial PhraseBank), объединенных в один файл CSV. Данные здесь предоставляют финансовые предложения с метками тональности.
Давайте загрузим необходимый импорт:
import pandas as pd import string #library that contains sets of punctuation import nltk from nltk.corpus import stopwords from collections import defaultdict from sklearn.model_selection import train_test_split
Прочитайте данные:
data = pd.read_csv('Financial_Sentiment.csv')
print(data.info())
data.head()

Мы видим, что у нас есть два столбца данных и 5842 строки.
Давайте проверим типы настроений и их количество в наборе данных:
data['Sentiment'].unique(), data['Sentiment'].value_counts()

У нас есть три класса чувств:
- нейтральный
- положительный
- отрицательный
Проверьте, содержит ли набор данных нулевые значения:
data.isnull().sum()

Разделение данных на обучающие и тестовые наборы.
Мы разделили данные на 20% тестовый набор и 80% обучающий набор.
train_set, test_set = train_test_split(data, test_size=0.20, random_state=42) train_set.shape, test_set.shape # ((4673, 2), (1169, 2))
Предварительная обработка данных
Прежде чем мы сможем создать n-граммы, нам нужно выполнить определенные операции с данными, которые жизненно важны при выполнении НЛП.
В нашем случае мы проведем следующие операции:
- Токенизация. Здесь мы разбиваем предложения на отдельные слова, также называемые токенами. С помощью этих токенов мы можем создать словарь для представления всех слов в списке.
- Удаление знаков препинания. Нам не нужны знаки препинания в наших токенах.
- Нижний регистр: нам нужно преобразовать все токены в нижний регистр, чтобы избежать избыточности слов, чтобы модель не интерпретировала такие слова, как рынок, рынок и РЫНОК, как разные слова.
- Удаление стоп-слов. Стоп-слова – это слова, которые не добавляют особого значения нашей модели, например "the", "is" и "her". Эти слова действуют как шум, поэтому мы их удалим.
Обратите внимание, что эти операции необязательны для всех задач НЛП. В некоторых задачах, таких как генерация естественного языка, мы можем захотеть сохранить стоп-слова и знаки препинания, но здесь мы сосредоточимся на n-граммах.
Мы можем выполнять другие операции с данными НЛП, такие как стемминг и лемматизация, которые мы здесь не рассматриваем.
В следующем коде мы напишем функцию, которая выполняет вышеуказанные операции над предложениями. Он также будет отвечать за генерацию точных n-грамм.
def generate_ngrams(sentence, ngram=1):
# first lets convert the senetence into lower case
sentence_lower = sentence.lower()
sentence = re.sub(r'[^a-zA-Z0-9\s]', ' ', sentence_lower)
# Remove stopwords, and punctuation
stop = set(stopwords.words('english') + list(string.punctuation))
# tokenize and display tokenized sentence
clean_words = [i for i in word_tokenize(sentence) if i not in stop]
print(f"\n===Tokens:=== \n{clean_words}\n")
# Generate the n-grams of any size
ngrams = zip(*[clean_words[i:] for i in range(ngram)])
return [" ".join(ngram) for ngram in ngrams]
В функцию мы передаем параметры sentence и ngram. Мы присваиваем параметру ngram значение по умолчанию 1, которое вы можете изменить, чтобы сгенерировать n-грамм желаемого размера.
Давайте протестируем функцию:
# Generate n-grams of N=4 from the text text = 'Natural language Processing(NLP) is an awesome task! Learn N-grams today!' generate_ngrams(texts,4)

Это работает отлично. Давайте теперь погрузимся в создание n-грамм!
Теперь, когда наши данные готовы к использованию, давайте приступим к созданию из них фактических n-грамм.
Генерация униграмм
Мы можем создать униграммы из каждого предложения, сгруппированного по каждому из трех классов настроений. Мы будем:
- Проверьте наиболее часто используемые слова.
- Визуализируйте наиболее часто используемые слова для каждой категории.
Получите каждое слово и сгенерируйте униграмму с положительным настроением:
# Initialize a dictionary to store the words together with their counts
positiveWords=defaultdict(int)
# 1. traverse the dataframe pick sentences with positive sentiment
# 1.1. traverse through sentences and pick each word and preprocess
# them with the generate_ngrams() functions we created
# 1.1.1 store the words in a defaultdict
# 2. convert the dictionary into a df
for text in train_set[train_set['Sentiment']=='positive']['Sentence']:
for word in generate_ngrams(text):
positiveWords[word]+=1
df_positive = pd.DataFrame(sorted(positiveWords.items(),key=lambda x:x[1],reverse=True))
Повторите приведенный выше код для каждого слова и сгенерируйте униграмму с «отрицательным» настроением:
negativeWords = defaultdict(int)
for text in train_set[train_set['Sentiment']=='negative']['Sentence']:
for word in generate_ngrams(text):
negativeWords[word]+=1
df_negative = pd.DataFrame(sorted(negativeWords.items(),key=lambda x:x[1],reverse=True))
Получите каждое слово и сгенерируйте униграмму, в которой настроение является «нейтральным»:
for text in train_set[train_set['Sentiment']=='neutral']['Sentence']:
for word in generate_ngrams(text):
neutralWords[word]+=1
df_neutral = pd.DataFrame(sorted(neutralWords.items(),key=lambda x:x[1],reverse=True))
Давайте визуализируем количество униграмм:
x_positive = df_positive[0][:10]
y_positive = df_positive[1][:10]
x_negative = df_negative[0][:10]
y_negative = df_negative[1][:10]
x_neutral = df_neutral[0][:10]
y_neutral = df_neutral[1][:10]
fig, ax = plt.subplots(3, 1, figsize=(10, 7), layout='tight', dpi=100)
ax[0].bar(x_positive, y_positive, color='g')
ax[0].set_title('Top 10 words with positive sentiment')
ax[0].set_xlabel('Words in the positive df')
ax[0].set_ylabel('Count')
ax[1].bar(x_negative, y_negative, color='r')
ax[1].set_title('Top 10 words with negative sentiment')
ax[1].set_xlabel('Words in the negative df')
ax[1].set_ylabel('Count')
ax[2].bar(x_neutral, y_neutral, color='gray')
ax[2].set_title('Top 10 words with neutral sentiment')
ax[2].set_xlabel('Words in the neutral df')
ax[2].set_ylabel('Count')
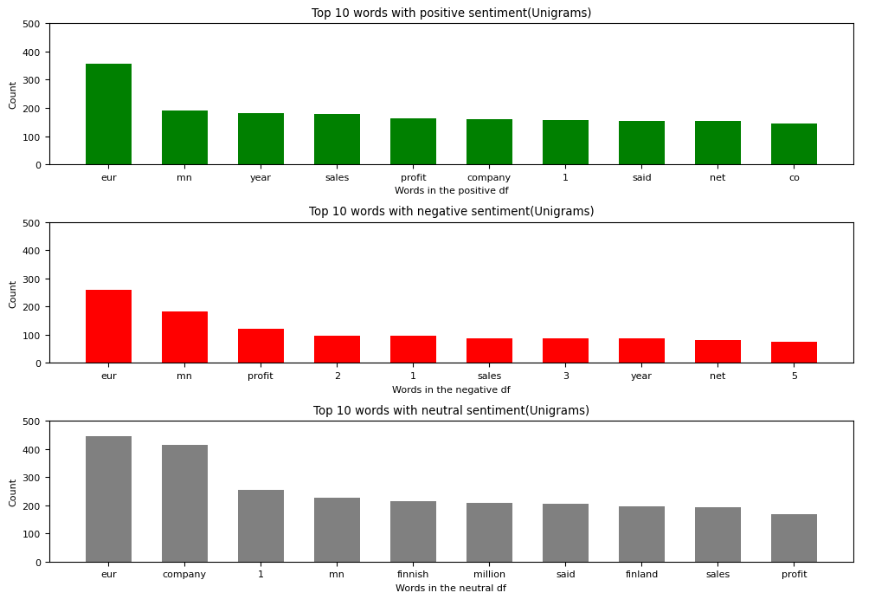
Генерация биграмм
Чтобы создать биграммы, мы не забудем вызвать функцию generate_ngrams() со значением параметра ngram равным 2.
# Defined new dictionaries positiveWords_bi=defaultdict(int) negativeWords_bi=defaultdict(int) neutralWords_bi=defaultdict(int)
Получите слова и сгенерируйте биграммы, где настроения «положительны»:
# Creating positive bigrams
for text in train_set[train_set['Sentiment']=='positive']['Sentence']:
for word in generate_ngrams(text, 2):
positiveWords_bi[word]+=1
df_positive_bi = pd.DataFrame(sorted(positiveWords_bi.items(),key=lambda x:x[1],reverse=True))
df_positive_bi
Получите слова и сгенерируйте биграммы, где настроение «негативное»:
# Creating negative bigrams
for text in train_set[train_set['Sentiment']=='positive']['Sentence']:
for word in generate_ngrams(text, 2):
negativeWords_bi[word]+=1
df_negative_bi = pd.DataFrame(sorted(negativeWords_bi.items(),key=lambda x:x[1],reverse=True))
df_negative_bi
Получите слова и сгенерируйте биграммы, где настроение является «нейтральным»:
# Creating neutral bigrams
for text in train_set[train_set['Sentiment']=='positive']['Sentence']:
for word in generate_ngrams(text, 2):
neutralWords_bi[word]+=1
df_neutral_bi = pd.DataFrame(sorted(neutralWords_bi.items(),key=lambda x:x[1],reverse=True))
df_neutral_bi
Визуализация:
x_positive_bi = df_positive_bi[0][:10]
y_positive_bi = df_positive_bi[1][:10]
print(x_positive_bi)
x_negative_bi = df_negative_bi[0][:10]
y_negative_bi = df_negative_bi[1][:10]
x_neutral_bi = df_neutral_bi[0][:10]
y_neutral_bi = df_neutral_bi[1][:10]
fig, ax = plt.subplots(3, 1, figsize=(10, 7), layout='tight', dpi=100)
ax[0].bar(x_positive_bi, y_positive_bi, color='g', width= 0.6)
ax[0].set_title('Top 10 words with positive sentiment(Bigrams)')
ax[0].set_xlabel('Words in the positive df')
ax[0].set_ylabel('Count')
ax[1].bar(x_negative_bi, y_negative_bi, color='r', width= 0.6)
ax[1].set_title('Top 10 words with negative sentiment(Bigrams)')
ax[1].set_xlabel('Words in the negative df')
ax[1].set_ylabel('Count')
ax[2].bar(x_neutral_bi, y_neutral_bi, color='gray', width= 0.6)
ax[2].set_title('Top 10 words with neutral sentiment(Bigrams)')
ax[2].set_xlabel('Words in the neutral df')
ax[2].set_ylabel('Count')

Генерация триграмм
Чтобы создать триграммы, мы не забудем вызвать функцию generate_ngrams() со значением параметра ngram равным 3.
positiveWords_tri = defaultdict(int) negativeWords_tri = defaultdict(int) neutralWords_tri = defaultdict(int)
Получите слова и сгенерируйте триграммы, где настроение «положительно»:
# Creating positive trigrams
for text in train_set[train_set['Sentiment']=='positive']['Sentence']:
for word in generate_ngrams(text, 3):
positiveWords_tri[word] += 1
df_positive_tri = pd.DataFrame(sorted(positiveWords_tri.items(),key=lambda x:x[1],reverse=True))
df_positive_tri
Получите слова и сгенерируйте триграммы, где настроение «негативное»:
for text in train_set[train_set['Sentiment']=='negative']['Sentence']:
for word in generate_ngrams(text, 3):
negativeWords_tri[word]+=1
df_negative_tri = pd.DataFrame(sorted(negativeWords_tri.items(),key=lambda x:x[1],reverse=True))
df_negative_tri
Получите слова и сгенерируйте триграммы, где настроение является «нейтральным»:
# # Creating neutral trigrams
for text in train_set[train_set['Sentiment']=='neutral']['Sentence']:
for word in generate_ngrams(text, 3):
neutralWords_tri[word]+=1
df_neutral_tri = pd.DataFrame(sorted(neutralWords_tri.items(),key=lambda x:x[1],reverse=True))
df_neutral_tri
Визуализация:
x_positive_tri = df_positive_tri[0][:10]
y_positive_tri = df_positive_tri[1][:10]
x_negative_tri = df_negative_tri[0][:10]
y_negative_tri = df_negative_tri[1][:10]
x_neutral_tri = df_neutral_tri[0][:10]
y_neutral_tri = df_neutral_tri[1][:10]
fig, ax = plt.subplots(3, 1, figsize=(12, 8), layout='tight', dpi=110)
ax[0].bar(x_positive_tri, y_positive_tri, color='g', width= 0.6)
ax[0].set_title('Top 10 words with positive sentiment(Trigrams)')
ax[0].set_xlabel('Words in the positive df')
ax[0].set_ylabel('Count')
ax[1].bar(x_negative_tri, y_negative_tri, color='r', width= 0.6)
ax[1].set_title('Top 10 words with negative sentiment(Trigrams)')
ax[1].set_xlabel('Words in the negative df')
ax[1].set_ylabel('Count')
ax[2].bar(x_neutral_tri, y_neutral_tri, color='gray', width= 0.6)
ax[2].set_title('Top 10 words with neutral sentiment(Trigrams)')
ax[2].set_xlabel('Words in the neutral df')
ax[2].set_ylabel('Count')

Последние мысли
В этой статье мы узнали следующее:
- Что такое n-граммы?
- Классификация и примеры униграмм, биграмм и триграмм.
- Реализация любого размера n-грамм с помощью библиотеки
nltkPython из набора данных. - Предварительная обработка данных или текста для эффективного создания n-грамм — важный шаг в выполнении задач НЛП с использованием n-грамм.
- Как визуализировать n-граммы и получить их количество на основе настроений.
Как правило, n-граммы, где n > 1 работают лучше всего, поскольку они несут больше информации о контексте в целом.
Примечание редактора. Heartbeat — это интернет-издание и сообщество, созданное участниками и посвященное предоставлению лучших образовательных ресурсов для специалистов по науке о данных, машинному обучению и глубокому обучению. Мы стремимся поддерживать и вдохновлять разработчиков и инженеров из всех слоев общества.
Независимая от редакции, Heartbeat спонсируется и публикуется Comet, платформой MLOps, которая позволяет специалистам по данным и командам машинного обучения отслеживать, сравнивать, объяснять и оптимизировать свои эксперименты. Мы платим нашим авторам и не продаем рекламу.
Если вы хотите внести свой вклад, перейдите к нашему призыву к участию. Вы также можете подписаться на получение нашего еженедельного информационного бюллетеня (Еженедельник глубокого обучения), заглянуть в блог Comet, присоединиться к нам в Slack и подписаться на Comet в Twitter и LinkedIn для получения ресурсов и событий. и многое другое, что поможет вам быстрее создавать более качественные модели машинного обучения.