Современные передовые языковые модели основаны на архитектуре преобразователя [1]. Архитектура преобразователя, в остальном ничем не отличающаяся от MLP (многослойный персептрон), опирается на механизм внимания. Внимание предоставляет сети возможность извлекать долгосрочные отношения в заданных последовательностях слов, что имеет решающее значение для понимания естественного языка. Прежде чем приступить к основному обсуждению, я кратко объясню встраивания слов. Для простоты я представлю «основное внимание к себе», которое я называю так, поскольку это простейшая форма внимания к себе. Затем я подробно остановлюсь на внимании с масштабируемым скалярным произведением и многоголовом внимании.
Внимание — это общий термин, который может принимать различные формы, например. аддитивное внимание [2]. В этом тексте внимание относится к «точечному произведению внимания». Следует также отметить, что само-внимание — это форма внимания, сосредоточенная на отношениях «внутри» последовательности.
Вложение слов
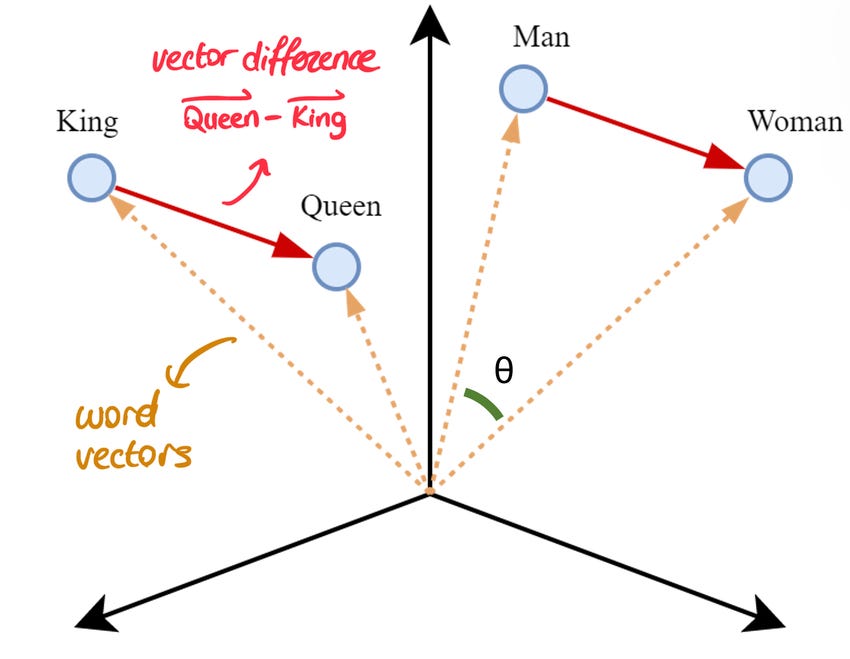
Встраивание слов — это представление слов (или токенов) в виде векторов в многомерном пространстве. Это представление может быть изучено из большого корпуса, например, с использованием методов word2vec [3], чтобы результирующие векторы встраивания кодировали семантические отношения внутри корпуса. В частности, ожидается, что векторы встраивания двух семантически связанных слов будут сходными с точки зрения направления, если предположить, что все векторы вложения имеют единичную длину. Рисунок 1 иллюстрирует векторы слов в трехмерном пространстве. Такое выученное представление слов может также отражать косвенные отношения. Например, ожидается, что векторные различия (женщина-мужчина) и (королева-король) будут одинаковыми, что показано красным цветом на рисунке 1.
Основное внимание к себе
Я использую термин базовое внимание к себе для обозначения простейшей формы внимания к себе. Уравнение (1) представляет собой математическое выражение базового внутреннего внимания, где x представляет собой последовательность слов, как показано на рисунке 2, dₛ — это длина последовательности, которая представляет собой количество слов (или токенов) в последовательности. входная последовательность, а dₘ — размерность вложения слова.
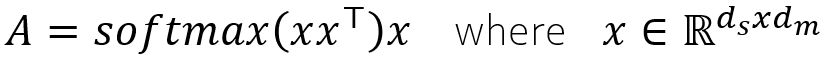

Выражение softmax(xxᵀ)x можно понять в три шага:
(i) xxᵀ: оценка сходства между каждым словом.
(ii) softmax(xxᵀ) : конвертировать оценки сходства в веса. На этом этапе оценки сходства преобразуются в значения от 0 до 1.
(iii) softmax(xxᵀ)x: взвешенная сумма функций из самих входных данных ( внимание к себе).
Давайте подробно рассмотрим каждый шаг.
Уравнение (2) показывает умножение матриц для вычисления показателей сходства между словами. xⁱxʲᵀ дает оценку сходства между i-м и j-м словами в последовательности. Таким образом, для dₛ слов имеется dₛ × dₛ баллов. Обратите внимание, что xxᵀ — симметричная матрица.
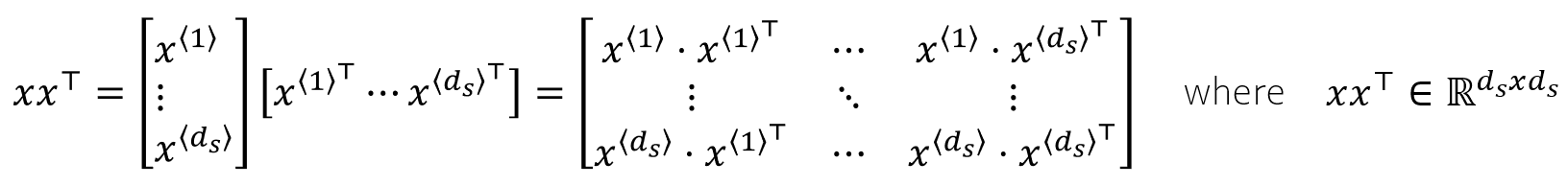
Косинусное подобие, данное в уравнении (3), равно скалярному произведению векторов единичной длины. Таким образом, xⁱxʲᵀ по сути является косинусным сходством между двумя векторами слов.

Косинусное сходство — это мера того, насколько похожи два вектора. Когда два вектора похожи, угол (θ) между ними мал, а это означает, что cos(θ) велик и ограничен единицей. Следовательно, скалярное произведение пропорционально сходству векторов, как указано в уравнении (3).
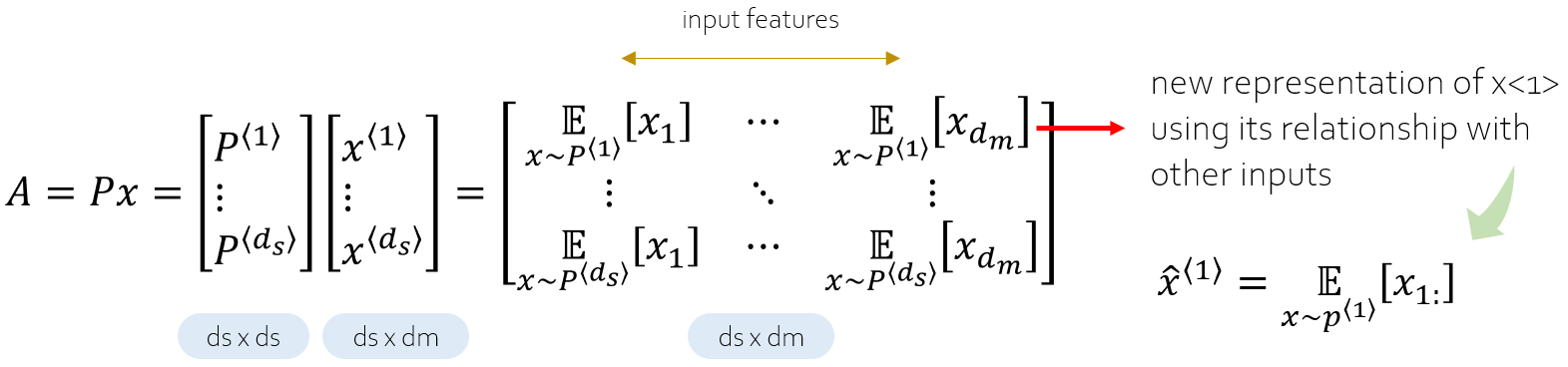
На втором этапе мы применяем softmax к показателям сходства, как указано в уравнении (4), где P — матрица dₛ × dₛ. Pⁱ — это сходство i-го слова с каждым словом в последовательности, сумма всех элементов Pⁱ которого равна 1. В В этом смысле оценки сходства преобразуются в веса с помощью softmax.

Последний шаг — это взвешенная сумма. Используя показатели сходства, каждое слово восстанавливается с учетом его связи со всеми словами в последовательности. В частности, k-й признак (или элемент) i-е слово в последовательности определяется скалярным произведением между Pⁱ и xₖ, где xₖ — это k й столбец ввода x. Этот скалярный продукт в основном представляет собой ожидание по размерам признаков с использованием оценок сходства в качестве весов. Таким образом, новое представление i-го слова кодирует его сходство с каждым словом в последовательности. На рис. 3 показан шаг взвешенного суммирования.
Например, при рассмотрении входной последовательности, представленной на рисунке 2, первая характеристика результирующего представления слова внимание определяется взвешенной суммой первых характеристик всех слов в последовательности с использованием оценок сходства.
Рисунок 4 демонстрирует числовой пример трех шагов базового само-внимания, который резюмирует концепцию. Пространство вложения предполагается трехмерным. В этом примере векторы слов не представляют изученные вложения, а являются случайными.

Точечный продукт Внимание
Математическое выражение скалярного произведения внимания дано в уравнении (5), где Q, K и V называются запросом, ключ и значение соответственно, вдохновленные базами данных.
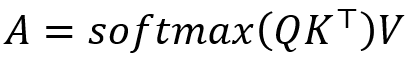
Это обобщенная форма само-внимания, когда Q = K = V, тогда операция становится само-вниманием и фокусируется на отношениях внутри последовательности. Однако в обобщенном виде внимание можно осуществлять на двух разных последовательностях. Например, предположим, что Q из последовательности 1, а K и V из последовательности 2. . Это означает, что последовательность 2 будет реконструирована с использованием ее взаимосвязей с последовательностью 1, что и происходит на уровнях внимания кодера-декодера преобразователя.
Масштабированный точечный продукт Внимание
Масштабированное скалярное произведение внимания, указанное в уравнении (6), представляет собой слегка модифицированную версию скалярного произведения внимания, так что показатели сходства (QKᵀ) масштабируются с помощью √dₖ. Причина в том, что если предположить, что Q и K имеют форму dₛ × dₖ и являются независимыми случайными величинами со средним значением 0 и дисперсией 1, их скалярное произведение имеет среднее значение 0 и дисперсию дₖ. Обратите внимание, что dₛ — это длина последовательности, а dₖ — размерность объекта. С этой модификацией изменения в dₖ не создают проблем.
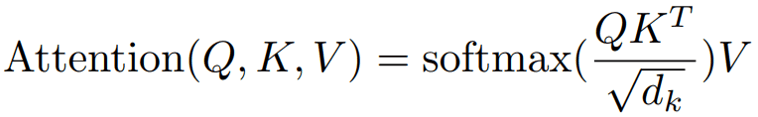
Многоголовое внимание
Многоголовое внимание — это расширенная форма масштабированного скалярного произведения внимания с изучаемыми параметрами в многоголовом режиме. На рис. 5 показано внимание с предшествующими линейными преобразованиями. Wᵢ(Q), Wᵢ(K) и Wᵢ(V) являются обучаемыми параметрами и реализуются как линейные слои.

Интуитивно понятно, что результирующие матрицы после линейных преобразований являются более полезными (или более богатыми) представлениями входных последовательностей, так что оценки сходства и шаг взвешенной суммы можно улучшить с помощью обучения. Рисунок 6 иллюстрирует общее внимание с несколькими головками. Входные последовательности Q, K и V имеют форму dₛ × dₘ. После линейных преобразований результирующие матрицы имеют размерность dₖ в пространстве признаков (обычно dᵥ = dₖ). После выполнения внимания над преобразованными матрицами результирующая матрица имеет форму dₛ × dₖ, и их h таких, что i = {1,…,h}. Они объединены таким образом, что dₛ × (dₖ × h) становится dₛ × dₘ. Наконец, над полученной матрицей выполняется еще одно линейное преобразование.

Следует отметить, что многоголовое внимание реализовано в виде самообслуживания в кодирующей и декодирующей частях архитектуры преобразователя в виде запросов (Q), ключей ( K), и значения (V) совпадают. На уровнях внимания кодировщик-декодер ключи и значения поступают из части кодировщика, а запросы поступают из части декодера, как объяснено в точке часть внимания к продуктуна примере.
Многоголоваяформавнимания предоставляет трансформеру возможность сосредоточиться на ассоциациях внутри последовательностей (или между последовательностями), учитывая различные аспекты, т.е. семантические и синтаксические.
Заключение
В этом тексте разъяснялся механизм внимания, то есть многоголовое внимание, в архитектуре преобразователя. Метод основан на косинусном сходстве между векторами слов. Многоголовное внимание может выявить долгосрочные отношения внутри последовательностей или между ними. Внимание можно использовать не только в текстах, но и в изображениях [4].
Рекомендации
[1] А. Васвани, Н. Шазир, Н. Пармар, Дж. Ушкорейт, Л. Джонс, А. Н. Гомес, Л. Кайзер и И. Полосухин, «Внимание — это все, что вам нужно», в Достижениях в области нейронных систем обработки информации, том. 30, 2017 г., стр. 5998–6008.
[2] Д. Багданау, К. Чо и Ю. Бенжио, «Нейронный машинный перевод путем совместного обучения выравниванию и переводу», в препринте arXiv arXiv: 1409.0473, сентябрь 2014 г.
[3] Т. Миколов, К. Чен, Г. Коррадо и Дж. Дин, «Эффективная оценка представлений слов в векторном пространстве», препринт arXiv arXiv: 1301.3781, 2013.
[4] А. Досовицкий и др., «Изображение стоит 16x16 слов: трансформеры для распознавания изображений в масштабе», в препринте arXiv arXiv: 2010.11929, 2020.