
Насколько точна Amazon Transcribe на южноафриканском английском?
Измерение точности транскрипции при отсутствии достоверной информации
Алекса, сыграй« Богемскую рапсодию ». Хорошо, звоню бабушке! Все мы были там с нашими цифровыми помощниками, особенно те из нас, кто говорит по-английски с одним из многих акцентов, с которыми эти помощники борются (в основном, с любыми другими акцентами, кроме американского или британского). Многие облачные сервисы, такие как предлагаемые Amazon и Google, теперь предлагают свои собственные сервисы преобразования речи в текст. Они часто упоминаются как имеющие очень высокую степень точности. Например, блог this обнаружил, что частота ошибок составляет всего 3–5% при тестировании этих сервисов на речи подкастов. Однако для многих реальных приложений требуется, чтобы преобразование речи в текст выполнялось в менее чем идеальных условиях шума, на динамиках с множеством разных акцентов. В этом блоге мы исследуем, как Amazon Transcribe работает с различными акцентами южноафриканского английского языка.
Данные
Набор данных, который мы используем для этих тестов, включает набор сообщений голосовой почты, отправляемых в центр обработки вызовов, в которых клиентов просят предоставить отзывы об услугах, которые они только что получили. Носители английского языка на первом или втором языке из Южной Африки. Общая продолжительность набора данных составляет около 290 часов аудио, что, насколько нам известно, является самым большим корпусом транскрибированных аудио на английском языке из Южной Африки.

Статистика набора данных показана на рисунке выше. Из этих 47 000 голосовых сообщений мы собрали приблизительно 63 500 аннотаций, расшифрованных аннотаторами, не являющимися экспертами, при этом 15% голосовых сообщений были аннотированы несколько раз для обеспечения контроля качества. Идея заключалась в том, чтобы использовать эти многократно записанные голосовые сообщения, чтобы получить некоторое представление о точности наших аннотаторов.
Соглашение между аннотаторами
Обычно, если нас интересует точность транскрипции, мы вычисляем коэффициент ошибок по словам (WER), чтобы получить ответ. Этот подход полезен для сравнения транскрипций, созданных системой преобразования текста в речь, с исходной справкой, созданной опытным аннотатором. Основная истина может использоваться как эталонная транскрипция, а выходные данные распознавателя речи - это транскрипция гипотез.
Однако что произойдет, если мы захотим сравнить друг с другом неопытных людей-аннотаторов? В этом случае ни одна из транскрипций не является основной ссылкой на правду. Без основополагающей истины мы больше не можем измерить «точность» как таковую, а скорее можем рассматривать уровень согласия как показатель точности. По аналогии, если бы мы попросили несколько студентов написать тест по математике, для которого не было меморандума, одним из способов составления меморандума было бы предположить, что наиболее часто задаваемые ответы, вероятно, будут правильными. У этого метода есть свои недостатки, но, к счастью, транскрипция намного проще, чем расчет, поэтому эти недостатки вряд ли будут иметь большое влияние.
Лучшая метрика
К сожалению, расчет WER не является коммутативным, т.е. мы получим другой ответ, если поменяем местами ссылку и гипотезу. Это демонстрируется примерами на рисунке ниже, где изменение порядка транскрипции приводит к другому WER, равному 40% или 44,44%. Чтобы измерить попарное согласие между аннотаторами, нам нужна коммутативная метрика, чтобы измерить степень, на которую различаются транскрипции.

Вот где в игру вступает нормализованный WER. Нормализованный WER делает простую модификацию WER, чтобы сделать его коммутативным. Вместо того, чтобы использовать длину контрольной транскрипции в качестве знаменателя, он использует длину самой длинной из двух транскрипций. Это означает, что порядок транскрипции больше не важен. Это еще раз показано в примерах на рисунке выше, где нормализованный WER остается 40% независимо от порядка транскрипции.
Нормализованный WER имеет дополнительное преимущество, заключающееся в том, что он имеет максимум 100% (нет согласия) и минимум 0% (полное согласие), что упрощает интерпретацию, чем WER, который может иметь значения, превышающие 100%. Нормализованный WER эквивалентен другому показателю, известному как коэффициент ошибок совпадения (MER), который более подробно обсуждается здесь вместе с другими показателями точности транскрипции.
Насколько хороши люди-аннотаторы?
Используя нормализованный WER, мы можем вычислить попарное согласие между всеми транскрипциями, выполненными несколькими аннотаторами. Затем мы можем усреднить попарное согласие каждого аннотатора, что дает нам приблизительную меру индивидуальной точности каждого аннотатора. Это показано на графике ниже. Мы видим, что аннотаторы варьируются от WER 44,9% до 17,6%, при этом медиана и среднее значение находятся в диапазоне 23–24%.
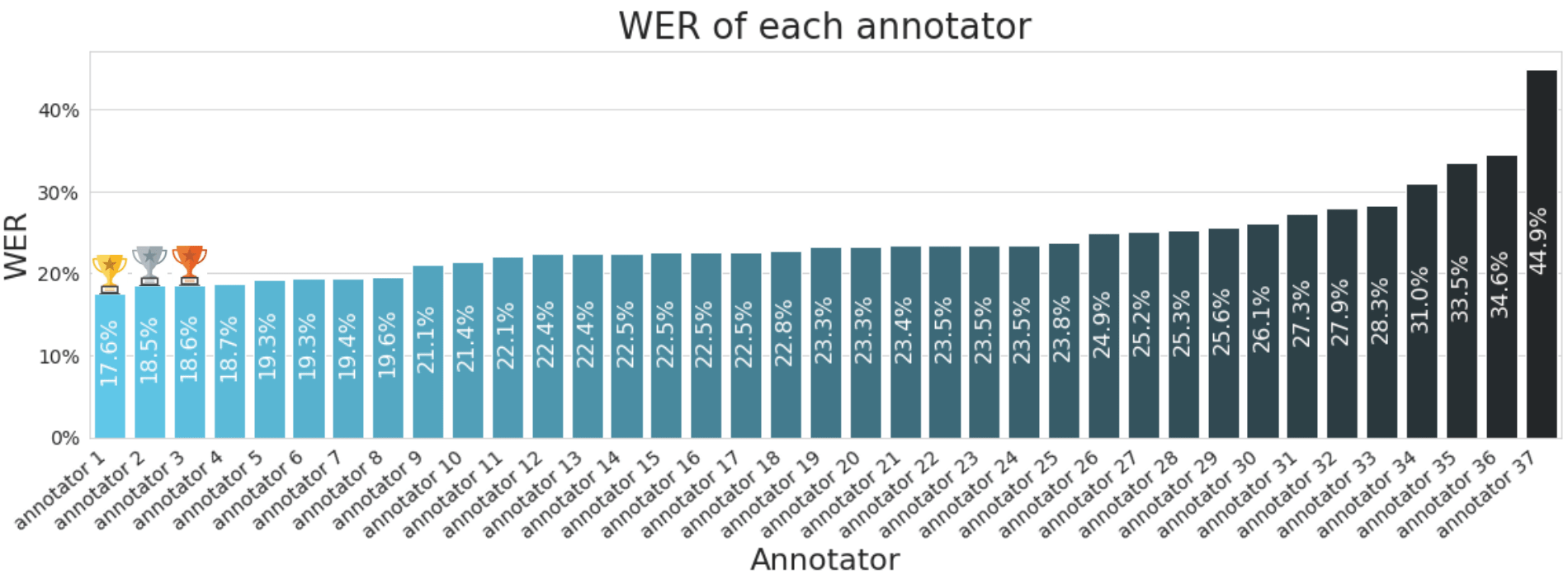
Мы можем интерпретировать эти результаты как расхождение в среднем 2,3 слова на каждые 10 слов между аннотаторами. Это очень похоже на то, что обнаружили исследователи из Кембриджа в этой статье, которые обнаружили средний уровень ошибок в 23,5% между тремя парами профессиональных служб транскрипции для людей.
Стоит отметить, что источником некоторых из этих ошибок является не то, что мы можем классифицировать как настоящую «ошибку». Аннотации очищаются перед выполнением вычисления WER, однако очистка не идеальна, и поэтому все же возникают случаи множественного или неправильного написания слова. Например, написание американского английского и британского английского языков, например color / color и finalize / finalize.
Также важно отметить, что межчеловеческие ошибки сильно отличаются от человеческих и автоматических сервисов преобразования речи в текст. Несмотря на то, что ошибка между людьми составляет около 20%, при ближайшем рассмотрении транскрипции обычно семантически очень похожи. Это не относится к службам автоматического преобразования речи в текст. Поэтому нечестно напрямую сравнивать WER между аннотаторами с человеческими и автоматическими преобразованиями речи в текст.
Человек против ИИ - Amazon Transcribe
Как упоминалось ранее, если у кого-то есть доступ к достоверным источникам информации, измерение WER - довольно тривиальная задача. Однако, если у вас есть человеческие расшифровки, не являющиеся экспертами, которые не обязательно являются абсолютной истиной, проблема усложняется. Диаграмма Венна ниже демонстрирует задачу. Есть частичное совпадение между человеческой транскрипцией, полученной из краудсорсинга, и «истинной» транскрипцией. Кроме того, транскрипция Amazon Transcribe частично совпадает с «истинной» транскрипцией. Мы хотели бы использовать человеческие транскрипции, которые являются приближением «истинной» транскрипции, чтобы оценить WER Amazon Transcribe.
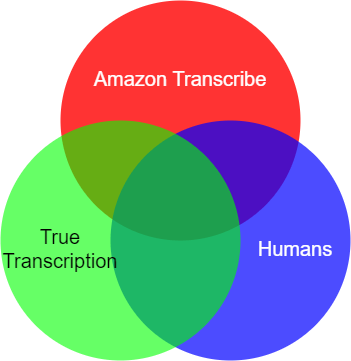
Чем люди отличаются от Amazon Transcribe?
Мы подходим к проблеме оценки количества ошибок в Amazon Transcribe с двух разных точек зрения. Первый - просто сравнить WER между всеми транскрипциями, созданными нами человеком, и транскрипциями Amazon Transcribe. Если мы сделаем это, мы обнаружим, что WER составляет 25%. Если бы у нас была достоверная справочная информация, мы бы приняли это значение в качестве своего окончательного ответа. Однако мы уже видели из разногласий между разными аннотаторами, что у нас явно есть некоторые ошибки в нашей человеческой транскрипции. Это означает, что истинная частота ошибок при расшифровке Amazon, вероятно, будет ниже, чем это.

Чтобы показать, почему, рассмотрим следующие два сценария. В сценарии 1 мы предполагаем, что человеческие аннотации верны на 100%. В этом случае ошибкой Amazon Transcribe будет измеренное нами значение WER, которое составляет 25%. В сценарии 2 мы предполагаем, что Amazon Transcribe на 100% верен. Итак, источником 25% WER будут человеческие аннотации. На самом деле мы знаем, что ни человеческие аннотации, ни Amazon Transcribe не являются на 100% правильными. Таким образом, мы можем рассматривать измеренную WER в 25% как верхнюю границу WER Amazon Transcribe, потому что на самом деле источником ошибки будет не только Amazon Transcribe, но и частично человеческая ошибка. Этот аргумент продемонстрирован на рисунке выше с примерами.
Сколько человеческих исправлений необходимо для исправления Amazon Transcribe?
Второй угол, с которого мы подходим к вопросу об уровне ошибок Amazon Transcribe, - это посмотреть на количество правок, которые должен внести человек-аннотатор, чтобы исправить Amazon Transcribe. Мы измерили это так, чтобы аннотаторы выполняли несколько иную задачу транскрипции, чем раньше. Для всего, что обсуждалось до этого момента, аннотаторы давали звук голосовой почты и пустое текстовое поле, где они могли ввести транскрипцию. Теперь вместо пустого текстового поля мы предоставили аннотаторам транскрипцию Amazon Transcribe и попросили их исправить ее. Это позволяет нам напрямую измерять количество изменений (вставок, удалений и замен), которые делает человек-аннотатор для исправления Amazon Transcribe. Мы называем эту задачу транскрипцией с предварительной маркировкой.
Одна из проблем этого подхода заключается в том, что аннотаторы теперь склонны к транскрипции, которую им дают. Мы можем представить, что если слово трудно услышать, аннотатор, скорее всего, оставит предварительную маркировку этого слова в Amazon Transcribe. Кроме того, если у нас есть уставшие или, возможно, немного ленивые аннотаторы (у всех нас бывают эти пятницы после обеда ...), они, вероятно, пропустят исправления, которые необходимо внести, или, что более злонамеренно, они могут оставить транскрипцию Amazon без изменений, чтобы получить быстрее справляться со своей рабочей нагрузкой.
Следовательно, лучший способ измерить количество правок, необходимых для исправления транскрипции, - это не измерить средний WER, а скорее посмотреть на аннотаторов с самым высоким WER, потому что эти аннотаторы явно нашли больше исправлений и поэтому, вероятно, вносили изо всех сил стараясь исправить транскрипцию. Та же самая логика часто применяется, когда у одного есть несколько транскрипций одного и того же аудио и нужно выбрать лучшую. Простая эвристика состоит в том, чтобы выбрать самую длинную транскрипцию, поскольку человек, написавший больше всего, вероятно, приложил больше усилий для их транскрипции. Это обсуждается в этой статье, где показано, что эта эвристика довольно хорошо работает на практике.
Гистограмма ниже показывает WER каждого аннотатора для предварительно помеченной задачи аннотации. Мы видим, что аннотаторы, внесшие наибольшее количество изменений, имеют коэффициент ошибок около 17%, что эквивалентно исправлению 1,7 слова на каждые 10 слов в выводе Amazon Transcribe. На другом конце спектра мы видим аннотаторов с очень низким уровнем ошибок, что указывает на то, что они не вносили много изменений в вывод Amazon Transcribe.
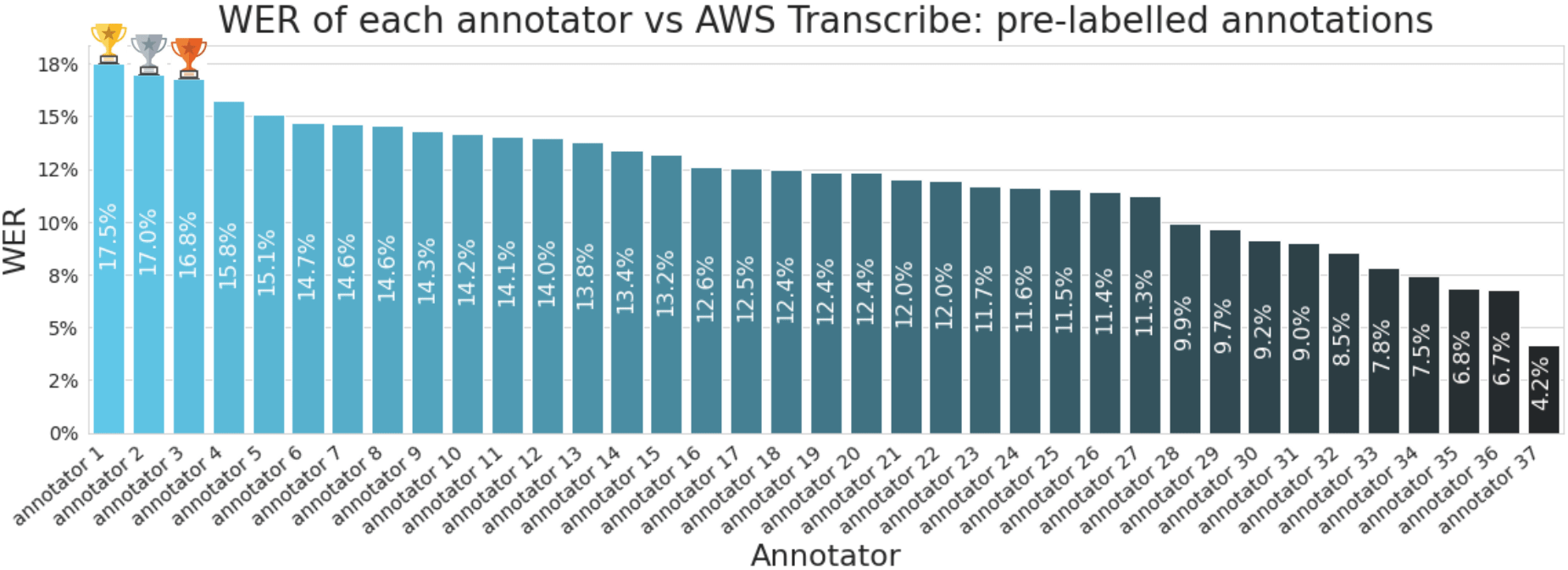
В действительности истинный WER, вероятно, выше 17%, предложенных в эксперименте до маркировки. Первая причина уже упоминалась: аннотаторы склонны использовать слова «услышанные» Amazon Transcribe, поскольку у них есть доступ к продукции Amazon Transcribe. Вторая причина заключается в том, что даже самые лучшие аннотаторы могут иногда пропускать исправления, которые необходимо внести. В результате мы можем думать о 17% WER из эксперимента до маркировки как о нижней границе истинного WER.
Собираем все вместе
Мы увидели, что наши человеческие транскриберы несовершенны, и в результате у нас нет точной базовой транскрипции, на основании которой можно было бы измерить эффективность Amazon Transcribe. Чтобы обойти эту проблему, мы измерили уровень ошибок Amazon Transcribe двумя разными способами. Сначала мы сравнили Amazon Transcribe с нашими ошибочными человеческими транскрипциями, чтобы получить верхнюю границу WER. Оказалось, что это около 25%. Затем мы передали нашим аннотаторам результаты Amazon Transcribe и попросили их исправить их, чтобы измерить, сколько правок требуется для исправления транскрипции Amazon Transcribe. Это дало нам нижнюю границу WER, которая составила около 17%. Таким образом, мы можем сказать, что Amazon Transcribe имеет WER 17–25% на большом корпусе аудио с южноафриканским акцентом на английском языке.
Благодарности
Эта работа была бы невозможна без фантастической работы, проделанной всеми в команде Tesserae. Эшли Грицман, наш технический директор, который ежедневно поддерживает и вдохновляет нас. Гилад Эвен-Тов и Джей Мейеровиц, фантастические инженеры, стоящие за нашей платформой аннотаций. Картика Мистри и Люто Мативэйна из команды BizOps за координацию наших проектов и команды аннотаций. И, конечно же, большое спасибо нашему бесстрашному лидеру Стю Айверсону. Наконец, хочу поблагодарить всех наших аннотаторов за их усердную работу и Standard Bank за то, что сделали этот проект возможным.
О нас
Искусственный интеллект будет определять сектор финансовых услуг в течение следующих пяти лет, но компании изо всех сил пытаются внедрить ИИ из-за двух основных проблем: доступа к качественным данным и доступа к высококлассным талантам. В Tesserae мы создаем единственную полнофункциональную платформу искусственного интеллекта, ориентированную на отрасль финансовых услуг, включая крупномасштабную платформу крауд-лейбла и рынок современных моделей искусственного интеллекта. Tesserae была основана вместе со Standard Bank Group, чтобы помочь компаниям использовать свои данные при создании рабочих мест на африканском континенте.
использованная литература
Cloud Compiled, Сравнение API транскрипции: Google Speech-to-text, Amazon, Rev.ai, Cloud Compiled Blog, 2020. [Online]. Доступно: https://cloudcompiled.com/blog/transcription-api-comparison/.
А. С. Моррис, В. Майер и П. Грин, От WER и RIL к MER и WIL: улучшенные меры оценки для распознавания связанной речи, в Proc. INTERSPEECH, Остров Чеджу, Корея, 2004 г. [онлайн]. Доступно: https://www.isca-speech.org/archive/archive_papers/interspeech_2004/i04_2765.pdf.
Ю. Гаур, В. С. Ласецки, Дж. П. Бигхэм и Ф. Метце, Влияние качества автоматического распознавания речи на латентность транскрипции человека, в Proc. W4A, Монреаль, Канада, 2016 г. [Online]. Доступно: https://www.cs.cmu.edu/~fmetze/interACT/Publications_files/publications/asr_threshold_w4a.pdf.
Р. К. ван Дален, К. М. Книлл, П. Циакулис и М. Дж. Ф. Гейлс, Улучшение транскрипции из нескольких источников с использованием распознавателя речи, в Proc. ICASSP, Квинсленд, Австралия, 2015 г. [Online]. Доступно: https://www.repository.cam.ac.uk/bitstream/handle/1810/247607/van%20Dalen%20et%20al%202015%20Proceedings%20of%20the%20IEEE%20International%20Conference%20on%20Acoustics % 2c% 20Speech% 20and% 20Signal% 20Processing% 20% 28ICASSP% 29.pdf? Sequence = 1 & isAllowed = y .