Я прочитал несколько книг и статей о сверточной нейронной сети, кажется, я понимаю концепцию, но не знаю, как ее представить, как на изображении ниже: 
(источник: what-when-how.com)
{kind=link}
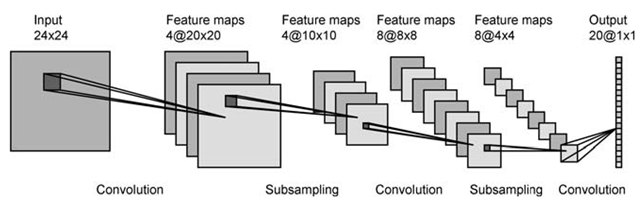
из 28x28 нормализованных пикселей INPUT мы получаем 4 карты признаков размером 24x24. но как их получить? изменение размера ВХОДНОГО изображения? или выполнение преобразований изображений? а какие превращения? или разрезать входное изображение на 4 части размером 24x24 на 4 угла? Я не понимаю процесс, мне кажется, что они разрезают или изменяют размер изображения на более мелкие изображения на каждом этапе. пожалуйста, помогите спасибо.
convolutional NN), но большинство людей, похоже, сосредотачиваются на объяснении того, как работает CNN, и игнорируют то, как получить часть карт функций. Я был смущен (и зол тоже), пока не нашел этот сайт: www1.i2r.a-star.edu.sg/~irkhan/conn2.html Здесь все объясняется простым английским языком. - person Yukio Fukuzawa schedule 20.04.2013