Любой ненулевой recurrent_dropout дает NaN потерь и веса; последние равны либо 0, либо NaN. Бывает для сложенных, неглубоких, stateful, return_sequences = любое, с & без Bidirectional(), activation='relu', loss='binary_crossentropy'. NaN встречаются в нескольких пакетах.
Какие-нибудь исправления? Помощь приветствуется.
УСТРАНЕНИЕ НЕИСПРАВНОСТЕЙ:
recurrent_dropout=0.2,0.1,0.01,1e-6kernel_constraint=maxnorm(0.5,axis=0)recurrent_constraint=maxnorm(0.5,axis=0)clipnorm=50(эмпирически определено), оптимизатор Nadamactivation='tanh'- нет NaN, вес стабилен, протестировано до 10 партийlr=2e-6,2e-5- нет NaN, вес стабилен, протестировано до 10 партийlr=5e-5- нет NaN, вес стабилен, для 3 партий - NaN в партии 4batch_shape=(32,48,16)- большие потери для 2 партий, NaN на 3 партии
ПРИМЕЧАНИЕ: batch_shape=(32,672,16), 17 вызовов train_on_batch на пакет
СРЕДА:
- Keras 2.2.4 (бэкэнд TensorFlow), Python 3.7, Spyder 3.3.7 через Anaconda
- GTX 1070 6 ГБ, i7-7700HQ, 12 ГБ ОЗУ, Win-10.0.17134 x64
- CuDNN 10+, новейшие диски Nvidia
ДОПОЛНИТЕЛЬНАЯ ИНФОРМАЦИЯ:
Расхождение моделей является спонтанным и происходит при разных обновлениях поезда даже с фиксированными начальными числами - случайными начальными числами Numpy, Random и TensorFlow. Кроме того, при первом расхождении веса слоя LSTM все нормальны - только позже переходят к NaN.
Ниже по порядку: (1) входы в LSTM; (2) LSTM выходов; (3) Dense(1,'sigmoid') выходов - три последовательных, по Dropout(0.5) между каждым. Предыдущий (1) - это Conv1D слой. Справа: веса LSTM. "BEFORE" = 1 поезд до обновления; "AFTER = 1 поезд обновлен после
ДО расхождения: 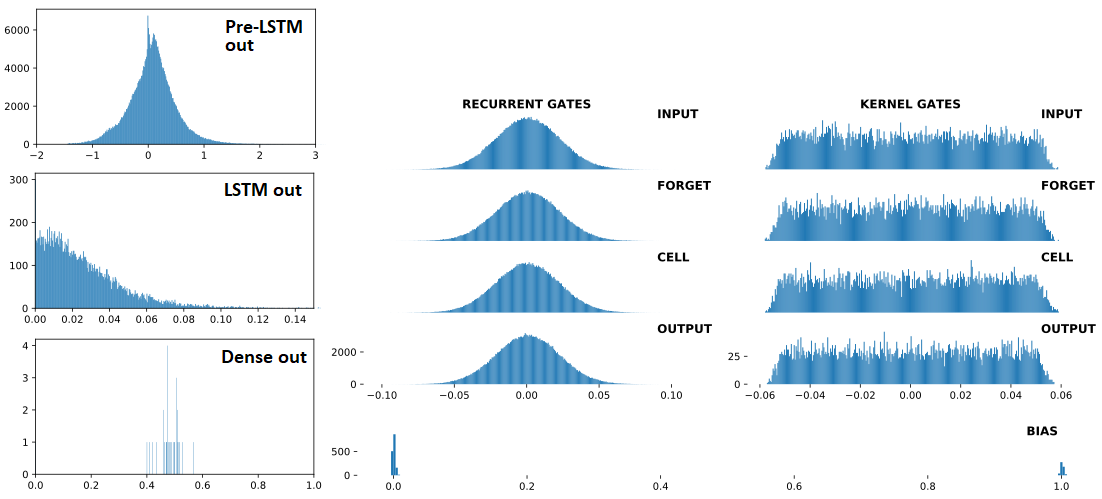
AT расхождения: 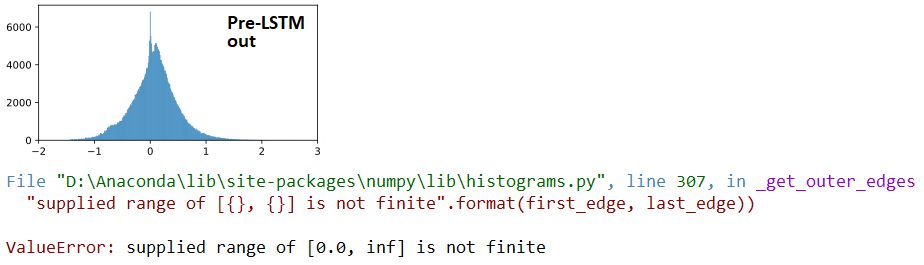
## LSTM outputs, flattened, stats
(mean,std) = (inf,nan)
(min,max) = (0.00e+00,inf)
(abs_min,abs_max) = (0.00e+00,inf)
ПОСЛЕ расхождения: 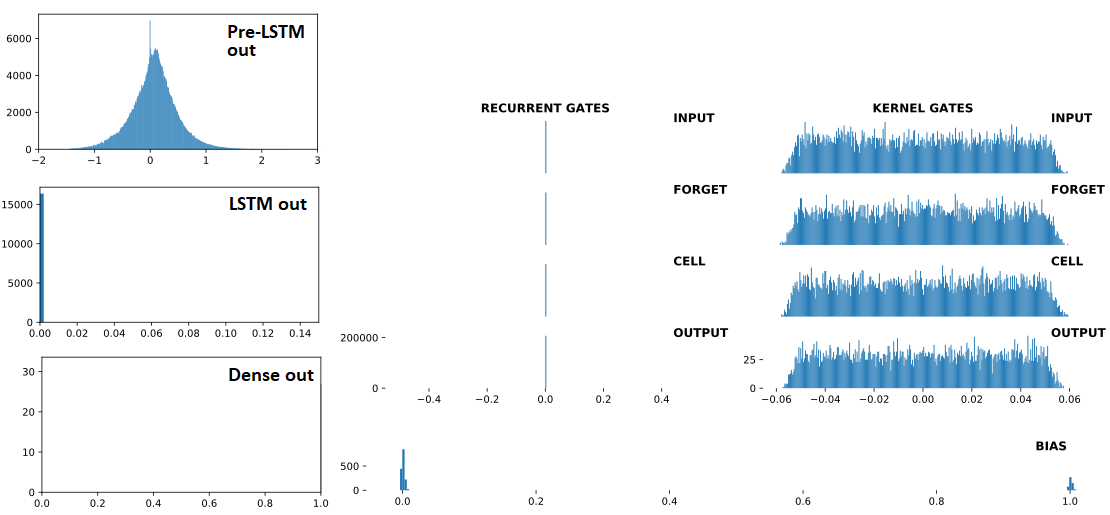
## Recurrent Gates Weights:
array([[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., 0.],
[ 0., -0., -0., ..., -0., 0., 0.],
...,
[nan, nan, nan, ..., nan, nan, nan],
[ 0., 0., -0., ..., -0., 0., -0.],
[ 0., 0., -0., ..., -0., 0., 0.]], dtype=float32)
## Dense Sigmoid Outputs:
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]], dtype=float32)
МИНИМАЛЬНЫЙ ВОСПРОИЗВОДИМЫЙ ПРИМЕР:
from keras.layers import Input,Dense,LSTM,Dropout
from keras.models import Model
from keras.optimizers import Nadam
from keras.constraints import MaxNorm as maxnorm
import numpy as np
ipt = Input(batch_shape=(32,672,16))
x = LSTM(512, activation='relu', return_sequences=False,
recurrent_dropout=0.3,
kernel_constraint =maxnorm(0.5, axis=0),
recurrent_constraint=maxnorm(0.5, axis=0))(ipt)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt,out)
optimizer = Nadam(lr=4e-4, clipnorm=1)
model.compile(optimizer=optimizer,loss='binary_crossentropy')
for train_update,_ in enumerate(range(100)):
x = np.random.randn(32,672,16)
y = np.array([1]*5 + [0]*27)
np.random.shuffle(y)
loss = model.train_on_batch(x,y)
print(train_update+1,loss,np.sum(y))
Наблюдения: следующее ускоряет расхождение:
- Высшее
units(LSTM) - Более # слоев (LSTM)
- Выше
lr‹< нет расхождения при<=1e-4, протестировано до 400 поездов - Меньше
'1'меток ‹< нет расхождений сyниже, даже сlr=1e-3; протестировано до 400 поездов
y = np.random.randint(0,2,32) # makes more '1' labels
ОБНОВЛЕНИЕ: не исправлено в TF2; воспроизводимый также с использованием from tensorflow.keras импорта.

recurrent_dropout=0(хотя модель изо всех сил пытается учиться, веса не плохо себя ведут) - person OverLordGoldDragon schedule 16.08.2019recurrent_dropoutпроблематична - person OverLordGoldDragon schedule 16.08.2019