Иногда во время разработки, например. В коде C вы можете случайно проиндексировать массив за пределами его последнего элемента, что приведет к чтению по существу случайного фрагмента памяти. Я много работаю с массивами double и заметил, что когда это происходит, double, создаваемое из случайной памяти, часто бывает очень большим, например, больше, чем 1e+300. Интересно, почему это так.
Если бы 64 бита, используемые для интерпретации double, были действительно случайными, я бы ожидал, что показатель степени double будет равномерно распределен от 0 до 308 (игнорируя знак степени) из-за того, как числа с плавающей запятой расположены в памяти используя научную (экспоненциальную) запись. Конечно, значения случайно выбранных битов в памяти сами по себе не распределяются случайным образом, а соответствуют некоторому значимому состоянию любого процесса, установившего эти значения.
Чтобы исследовать этот эффект, я написал следующий скрипт Python 3, который отображает распределение действительно случайно сгенерированных doubles и doubles, взятых из случайной, но неиспользуемой памяти:
import random, struct
import numpy as np
import matplotlib.pyplot as plt
N = 10000
def random_floats(N=1):
return np.array(struct.unpack('d'*N, bytes(random.randrange(256) for _ in range(8*N))))
def exp_hist(a, label=None):
a = a[~np.isnan(a)]
a = a[~np.isinf(a)]
a = a[a != 0]
if len(a) == 0:
print('Zeros only!')
return
a = np.abs(np.log10(np.abs(a)))
plt.hist(a, range=(0, 350), density=True, alpha=0.8, label=label)
# Floats generated from uniformly random bits
a = random_floats(N)
exp_hist(a, 'random')
# Floats generated from memory content
a = np.empty(N)
exp_hist(a, 'memory')
plt.xlabel('exponent')
plt.legend()
plt.savefig('plot.png')
Типичный результат запуска этого скрипта показан ниже:
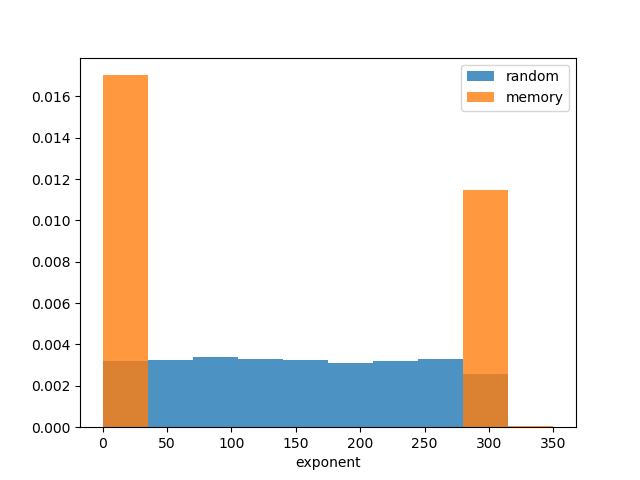
Показатели действительно случайно сгенерированных doubles действительно равномерно распределены.
Показатели doubles, интерпретированные из содержимого памяти, либо очень малы, либо очень велики. На самом деле большая часть неиспользуемой памяти обнуляется, что приводит к большому количеству значений 0, что имеет смысл. Однако, как я часто сталкиваюсь с доступом к памяти без возврата, также появляется много значений около 1e+300.
Я хотел бы получить объяснение этого большого количества чрезвычайно больших doubles.
Примечание по запуску скрипта
Если вы хотите попробовать сценарий самостоятельно, имейте в виду, что вам, возможно, придется запустить его несколько раз, чтобы появилось что-нибудь интересное. Может случиться так, что каждое отдельное число, считанное из содержимого памяти, будет 0, и в этом случае он сообщит вам об этом. Если это происходит неоднократно, попробуйте уменьшить N (количество используемых doubles).
double. - person Eric Postpischil schedule 11.12.2019a = np.abs(np.log10(np.abs(a)))? Зачем брать абсолютное значение журнала? - person Patricia Shanahan schedule 11.12.2019abs()должен сделать число положительным, так какlog10()не работает при отрицательных значениях. Результатомlog10()является показатель степени исходного числа, который может быть любым от примерно-323до308(т. е. диапазонdoubles составляет примерно от1e-323до1e+308, независимо от знака). Меня не волнует знак экспоненты, только то, что он далек от1, поэтому я беру ещеabs(). - person jmd_dk schedule 11.12.2019