PCA для уменьшения размерности и визуализации данных

В современную эпоху искусственного интеллекта данные — это новое топливо. Благодаря цифровизации существуют различные инструменты, которые собирают данные обо всем в мире. Возьмем, к примеру, Facebook. Facebook собирает различные типы пользовательских данных, таких как возраст, пол, связи и многое другое. Такие данные могут иметь более 1000 таких признаков. Для работы с такими многомерными данными для их обработки и создания надежных автоматизированных систем мы, люди, создали модели машинного обучения (ML), но у них есть ограничения. Они плохо работают, когда данные имеют высокую размерность с коллинеарностью между функциями. Данные с большими размерами и колинеарностью функций — это проклятие, поскольку они снижают интерпретируемость и влияют на производительность моделей машинного обучения. Другой аспект заключается в том, что мы, люди, можем интерпретировать данные только в 2D и 3D измерениях, поскольку человеческий глаз может их визуализировать, но данные с большими размерами также трудно визуализировать и интерпретировать.
Чтобы преодолеть вышеупомянутые проблемы, связанные с размерностью, пригодится PCA, который помогает уменьшить размерность данных для целей визуализации, а также упростить обучение моделей ML для создания высоконадежных решений.
Геометрическая интуиция PCA:
Для понимания концепции возьмем мелкомасштабные 2D-данные. Предположим, у нас есть данные из социальных сетей, и наша задача — угадать пол по имеющимся данным. Данные имеют две особенности:
f1: чернота волос - реально ценный признак
f2: рост людей - реально ценный признак.
Данные нанесены на график, и распределение точек данных показано на рисунке:

Здесь функция f2 имеет больший разброс, чем f1, что означает, что f2 имеет высокую дисперсию, и это более важная функция, поэтому мы можем пропустить f1 на основе дисперсии, поскольку она является мерой информации. Таким образом, цель уменьшения размерности достигается путем преобразования 2D-данных в 1D-данные. PCA применяет ту же концепцию для уменьшения размерности.
Математическая целевая функция PCA:
PCA пытается найти направление, в котором дисперсия точек данных, спроецированных на это направление, максимальна. Таким образом, цель PCA состоит в том, чтобы найти направление (вектор) u1, в котором разброс/дисперсия точек данных максимальны, и, таким образом, уменьшить размерность, выбрав только признаки с высокой дисперсией. Предположим, у нас есть набор данных D: {Xi} от i до n, распределение которых показано ниже, и предполагается, что данные стандартизированы по столбцам. (µ=0, стандартное отклонение=1):

Чтобы найти: u1 — единичный вектор (||u1||=1) ….. Направление с максимальной дисперсией. Для расчета дисперсии в направлении u1 нам потребуется:


В соответствии с целью PCA задача состоит в том, чтобы найти u1 такое, что дисперсия проекции {Xi’} i=1 на n будет максимальной. Следовательно, дисперсия

Таким образом, исходя из предположения, что данные стандартизированы по столбцу, где уравнение X_mean = 0 становится,

Итак, целевая функция задачи оптимизации:

Мы можем решить эту проблему оптимизации, попробовав случайные векторы u1 и выбрав вектор, который дает максимальное значение дисперсии.
Решение задачи оптимизации:› Собственное значение и собственный вектор
Собственный вектор (V) есть не что иное, как направление u1, в котором дисперсия максимальна, значение, соответствующее собственному вектору, есть собственное значение (ƛ). Предположим, у нас есть набор данных с 10 измерениями, как показано ниже:

Шаги по поиску собственных значений и векторов:
- Выполните стандартизацию столбца по заданным данным, используя среднее значение из столбцов и стандартное отклонение.


2. Рассчитать ковариационную матрицу.
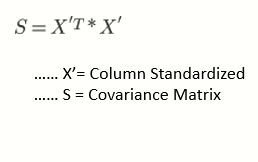

Ковариационная матрица будет квадратной матрицей размерности 10*10.
3. Найдите собственные значения и векторы, соответствующие ковариационной матрице. Расчет объяснен в ссылке. Мы получим 10 собственных значений и векторов, поскольку наша ковариационная матрица имеет размерность 10 * 10.
4. Выберите лучшие собственные векторы, которые сохраняют максимум информации. Предположим, если вы хотите сохранить 99% информации, вы можете проверить объяснение дисперсии (дисперсия является мерой информации) следующим образом:

Приведенный выше расчет даст нам % сохраненной информации. Теперь, если предположить, что из 10 лучших собственных значений, используя только 5 верхних собственных значений, мы получаем 99% сохраненной информации, тогда мы можем выбрать эти 5 собственных значений и соответствующие векторы и отбросить все остальные. Тогда мы можем сказать, что успешно уменьшили исходные 10-мерные данные до 5-мерных, сохранив 99% информации.

Теперь с такой уменьшенной размерностью данных мы можем легко визуализировать и строить модели машинного обучения на основе этих данных.
Пример:

Справочные ссылки: