Итак, эта 3-я часть блога, а также заключительная часть, так как я буду освещать последние темы по математике и статистике, лежащие в основе машинного обучения.
Если вы не видели мой предыдущий блог, проверьте его. Вот ссылка на него.
Часть 1 -
Часть 2 -
Итак, без дальнейших задержек, давайте приступим к заключительной части серии.

В заключительной части осталось две темы. Многовариантное исчисление | Алгоритм и сложность. Итак, в этом блоге мы рассмотрим эти темы.
Многомерное исчисление
Прежде чем мы перейдем к определению, применению и всему прочему об исчислении, я просто хочу упомянуть, что я пишу этот блог, ожидая, что у вас есть общие знания об исчислении, такие как дифференциация и интеграция, потому что это может потребоваться для понимания темы.
Многовариантность означает несколько переменных. Следовательно, многомерное исчисление - это область исчисления, в которой задействовано несколько переменных. Многомерное исчисление также известно как частное дифференцирование, используемое для математической оптимизации заданной функции (в основном выпуклой, поскольку выпуклая функция имеет минимумы). Используя многомерное исчисление, мы можем легко оптимизировать наш алгоритм выпуклой функции до минимума или самой низкой точки, есть способы, при которых он может застрять в локальных минимумах, но есть способы их избежать.

Спуск градиентов
Градиентный спуск - это алгоритм машинного обучения, который работает итеративно, чтобы найти оптимальные значения для своих параметров. Он учитывает заданную пользователем скорость обучения и начальные значения параметров.
Формула:

Зачем нам это нужно?
Обычно мы находим формулу, которая дает нам оптимальные значения для нашего параметра. Но в этом алгоритме он сам находит значение!
Некоторые основные правила вывода:
(A) Скалярное множественное правило:

(B) Правило суммы:
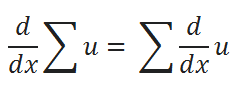
(C) Правило силы:

(D) Правило цепочки:

Давайте рассмотрим пример, чтобы узнать больше о градиентном спуске и многомерном исчислении.
Градиентный спуск в линейной регрессии:
В линейной регрессии цель модели - получить наиболее подходящую линию регрессии для прогнозирования значения y на основе заданного входного значения (x). Во время обучения модели модель вычисляет функцию стоимости, которая измеряет среднеквадратичную ошибку между прогнозируемым значением (прогноз) и истинным значением (y). Модель нацелена на минимизацию функции стоимости.
Чтобы минимизировать функцию стоимости, модель должна иметь наилучшее значение? 1 и? 2. Первоначально модель выбирает значения? 1 и? 2 случайным образом, а затем периодически обновляет эти значения, чтобы минимизировать функцию стоимости, пока она не достигнет минимума. К тому времени, когда модель достигнет функции минимальной стоимости, она будет иметь наилучшие значения? 1 и? 2. Используя эти окончательно обновленные значения? 1 и? 2 в уравнении гипотезы линейного уравнения, модель предсказывает значение y наилучшим образом.
Функция расчета стоимости линейной регрессии.


Алгоритм градиентного спуска для линейной регрессии:

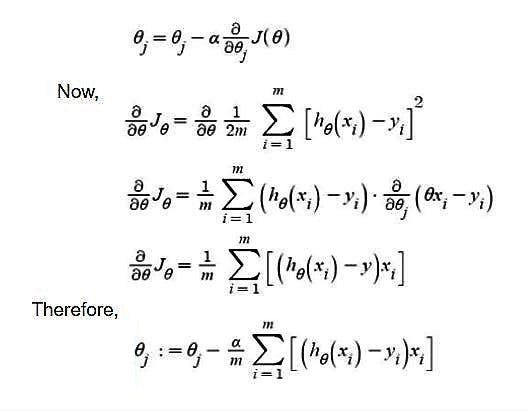
-> ?j : Weights of the hypothesis. -> h?(xi) : predicted y value for ith input. -> j : Feature index number (can be 0, 1, 2, ......, n). -> ? : Learning Rate of Gradient Descent. Note: Here '?' represents Theta
Алгоритм и сложность
Обзор алгоритмов машинного обучения
При обработке данных для моделирования бизнес-решений вы чаще всего используете контролируемые и неконтролируемые методы обучения.
Актуальной темой в настоящее время являются методы обучения с полу-контролируемым обучением в таких областях, как классификация изображений, где есть большие наборы данных с очень немногими помеченными примерами.
Здесь я собираюсь упомянуть виды алгоритмов машинного обучения, сгруппированные по сходству.

Алгоритмы регрессии
Наиболее популярные алгоритмы регрессии:
- Регрессия методом наименьших квадратов (OLSR)
- Линейная регрессия
- Логистическая регрессия
- Пошаговая регрессия
- Сплайны с многомерной адаптивной регрессией (MARS)
- Локально оцененное сглаживание диаграммы рассеяния (LOESS)
Алгоритмы на основе экземпляров
Самыми популярными алгоритмами на основе экземпляров являются:
- k-ближайший сосед (kNN)
- Обучающее векторное квантование (LVQ)
- Самоорганизующаяся карта (SOM)
- Локально-взвешенное обучение (LWL)
- Машины опорных векторов (SVM)
Алгоритмы регуляризации
Наиболее популярные алгоритмы регуляризации:
- Хребтовая регрессия
- Оператор наименьшей абсолютной усадки и выбора (LASSO)
- Эластичная сетка
- Регрессия наименьшего угла (LARS)
Алгоритмы дерева решений
Наиболее популярные алгоритмы дерева решений:
- Дерево классификации и регрессии (CART)
- Итерационный дихотомизатор 3 (ID3)
- C4.5 и C5.0 (разные версии мощного подхода)
- Автоматическое обнаружение взаимодействия методом хи-квадрат (CHAID)
- Решение Пень
- M5
- Деревья условных решений
Алгоритмы кластеризации
Наиболее популярные алгоритмы кластеризации:
- k-средства
- k-медианы
- Максимизация ожиданий (EM)
- Иерархическая кластеризация
Алгоритмы искусственной нейронной сети
Наиболее популярные алгоритмы искусственной нейронной сети:
- Перцептрон
- Многослойные персептроны (MLP)
- Обратное распространение
- Стохастический градиентный спуск
- Сеть Хопфилда
- Сеть радиальных базисных функций (RBFN)
Алгоритмы глубокого обучения
Наиболее популярные алгоритмы глубокого обучения:
- Сверточная нейронная сеть (CNN)
- Рекуррентные нейронные сети (RNN)
- Сети с долгой краткосрочной памятью (LSTM)
- Сложенные автокодеры
- Глубокая машина Больцмана (DBM)
- Сети глубокого убеждения (DBN)
Алгоритмы уменьшения размерности
Наиболее популярные алгоритмы уменьшения размерности:
- Анализ главных компонентов (PCA)
- Регрессия главных компонентов (ПЦР)
- Регрессия частичных наименьших квадратов (PLSR)
- Картирование Саммона
- Многомерное масштабирование (MDS)
- Проекционное преследование
- Линейный дискриминантный анализ (LDA)
- Дискриминантный анализ смеси (MDA)
- Квадратичный дискриминантный анализ (QDA)
- Гибкий дискриминантный анализ (FDA)
Чтобы узнать больше о таких алгоритмах, посетите ссылку ниже -
Вычислительная сложность моделей машинного обучения

Сложность времени можно рассматривать как меру того, насколько быстро или медленно алгоритм будет работать для входного размера. Сложность по времени всегда задается относительно некоторого размера ввода (например, n).
Сложность по пространству можно рассматривать как количество дополнительной памяти, которая требуется для выполнения вашего алгоритма. Как и временная сложность, она также задается относительно некоторого размера ввода (n).
Сложность алгоритма / модели часто выражается с помощью нотации Big O, которая определяет верхнюю границу алгоритма и ограничивает функцию только сверху.
На приведенном ниже графике показаны различные случаи. сложностей для алгоритмов.

Чтобы записать сложность вычислений, мы принимаем,
n = количество обучающих примеров, d = количество измерений данных,
k = количество соседей
Сложность K ближайших соседей для поиска k ближайшего соседа
Сложность времени обучения = O (knd)
Перебирает каждое обучающее наблюдение и вычисляет расстояние d между наблюдением обучающего набора и новым наблюдение.
Время линейно относительно количества экземпляров (n) и размеров (d).
Сложность пространства = O (nd)
K Ближайшие соседи хранят данные.
Тестирование занимает больше времени, потому что вам нужно сравнивать каждый тестовый экземпляр со всем данные обучения.
Сложность логистической регрессии
Сложность времени обучения означает в логистической регрессии решение задачи оптимизации.
Сложность времени обучения = O (nd)
Сложность пространства = O (d)
Примечание. Логистическая регрессия очень хороша для приложений с малой задержкой.
Сложность SVM
Сложность времени обучения = O (n²)
Примечание: если n большое, избегайте использования SVM.
Сложность времени выполнения = O (k * d)
K = количество опорных векторов, d = размерность данных
Сложность дерева решений
Сложность времени обучения = O (n * log (n) * d)
n = количество баллов в обучающем наборе
d = размерность данные
Сложность времени выполнения = O (максимальная глубина дерева)
Примечание. Мы используем дерево решений, когда у нас есть большие данные с невысокая размерность.
Сложность случайного леса
Сложность времени обучения = O (n * log (n) * d * k)
k = количество деревьев решений
Примечания: когда у нас есть большое количество данных с разумными характеристиками. Затем мы можем использовать многоядерность для распараллеливания нашей модели для обучения различных деревьев решений.
Сложность времени выполнения = O (глубина дерева * k)
Сложность пространства = O ( глубина дерева * k)
Примечание: случайный лес сравнительно быстрее, чем другие алгоритмы.
Сложность наивного байесовского метода
Сложность времени обучения = O (n * d)
Сложность времени выполнения = O (c * г)
Мы должны получить функцию для каждого класса 'c'
Я пытался предоставить важную информацию о многомерном исчислении | Алгоритм и сложность в этой последней части. Надеюсь, вы найдете здесь что-то полезное. Спасибо, что дочитали до конца. И если вам нравится мой блог, нажмите кнопку хлопка ниже. Сообщите мне, был ли мой блог действительно полезным. Кроме того, если вы не проверяли другие мои ЧАСТИ по той же теме, ниже приведены ссылки на них.
Часть 1 -
Часть 2 -