Важная стратегия для специалистов по данным

Данные называют новой нефтью 21 века. Очень важно манипулировать данными, чтобы извлечь и использовать правильную информацию для решения наших проблем. Работа с данными может быть интересной, а иногда и утомительной для людей. Как правильно сказано: «Специалисты по обработке данных тратят 80% своего времени на очистку данных». Будучи частью этого пакета, я прохожу тот же процесс, когда сталкиваюсь с новым набором данных. То же действие не ограничивается до тех пор, пока система машинного обучения (ML) не будет внедрена и развернута в производственной среде. При создании прогнозов в реальном времени данные могут измениться из-за не интуитивных и непредвиденных обстоятельств, таких как ошибка из-за вмешательства человека, отправленные неверные данные, новая тенденция в данных, проблема при записи данных и многое другое. Простая система машинного обучения, состоящая из нескольких этапов, выглядит так, как показано на диаграмме ниже:
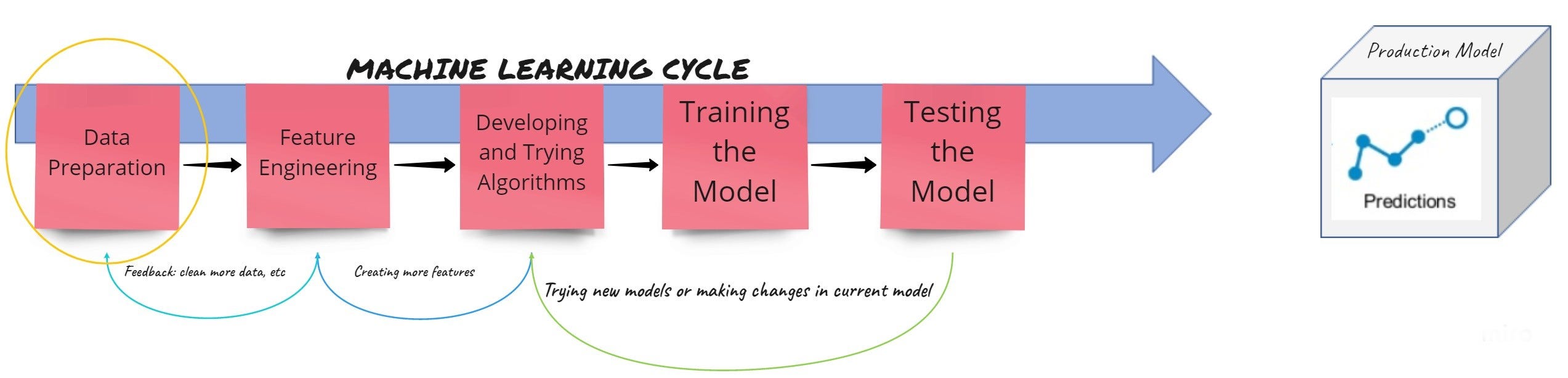
Это необходимо немного изменить, явно добавив или обозначив другой компонент, после подготовки данных и до разработки функций мы называем это Проверка данных:
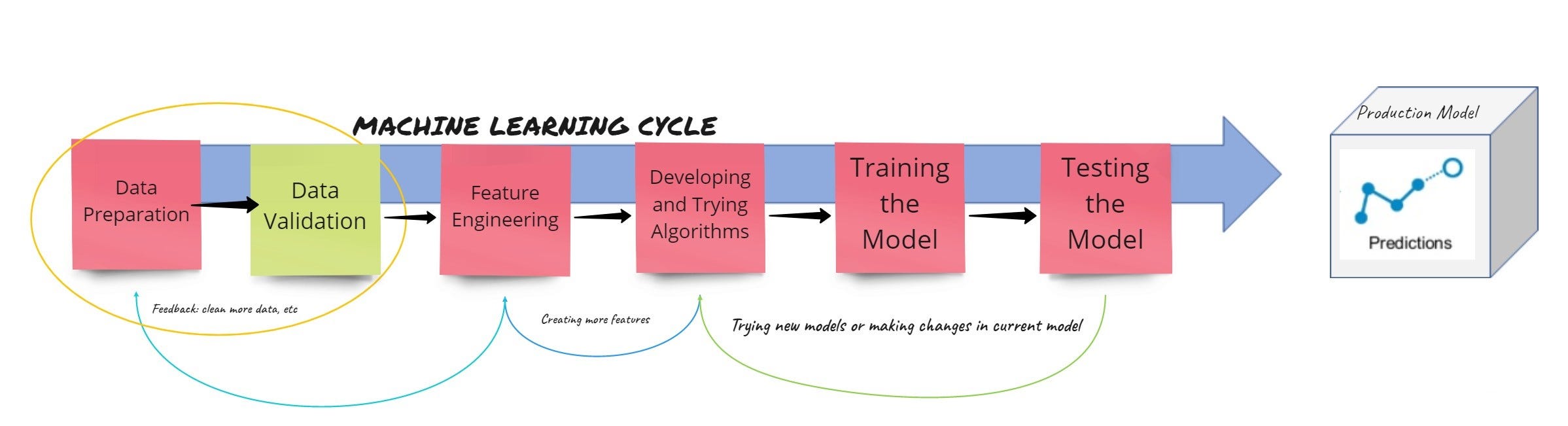
Статья посвящена тому, почему важна проверка данных и как можно использовать разные стратегии, чтобы без труда интегрировать их в свой конвейер. После некоторой работы я узнал, как реализовать сценарии, которые будут выполнять проверку данных, чтобы сэкономить время. Кроме того, я автоматизировал их, используя некоторые из готовых пакетов, тем самым ускоряя свою игру!
Услышь мою историю!

По данным Gartner, почти 85% проектов не попадут в производство. Конвейеры машинного обучения (ML) обычно сталкиваются с несколькими сбоями при запуске в производство. Одна из основных проблем, с которой я довольно часто сталкиваюсь, - это снижение качества данных. Проведение нескольких часов в день, может быть, несколько раз в месяц, и выяснение того, что полученные данные по какой-то причине неприемлемы, могут быть весьма утешительными, но в то же время разочаровывающими. Многие причины могут способствовать изменению типа данных, например, введению текста вместо целого числа, целочисленного значения на выбросе (вероятно, в 10 раз больше) или целого определенного столбца не был получен в потоке данных, чтобы упомянуть несколько. Вот почему так важно добавить этот дополнительный шаг. Проверка вручную может потребовать дополнительных усилий и времени. Автоматизация (до некоторой степени) может снизить нагрузку на команду Data Science. Я вижу несколько основных преимуществ, интегрировав автоматизированную проверку данных в конвейер:
- Экономит время на пару часов
- Меньше разочарований среди членов команды
- Более продуктивно за счет сосредоточения внимания на других областях
- Пытаемся сделать вашу серийную модель более точной;)
Сообщество Python уже создало несколько выдающихся пакетов, которые очень грамотно решают эти проблемы. Я собираюсь поделиться некоторыми из них, которые я исследовал, и о том, как я спроектировал свои сценарии, чтобы сделать их частью моего конвейера.
Источник данных: я взял самый последний набор данных, чтобы показать, как можно реализовать эти пакеты. Вот ссылка для получения данных.
Пакеты проверки данных
Пандера:
Pandera предоставляет очень простой и гибкий API для выполнения проверки данных для фрейма данных или данных серии. Это также помогает в выполнении сложной статистической проверки, такой как проверка гипотез, например two_sample_ttest. Более подробную информацию о пакете и использовании можно найти здесь.
Возьмите образец из 10 строк из набора данных:

Как мы видим, существует несколько столбцов с разными типами данных: String, Int, Float, Datetime. Нам нужно определить схему ожидаемых данных. Я определил простую схему без каких-либо строгих правил проверки данных, как показано в приведенном выше коде. В зависимости от ожидаемого типа данных мы можем использовать pa.Int для Integer, pa.String для String, pa.Float для float или pa.DateTime, если есть дата и время . Здесь мы устанавливаем nullable = True, если мы ожидаем NaN значений, иначе False. Более того, если мы установим coerce = True, он преобразует столбец в ожидаемый тип данных без каких-либо ошибок. Например, преобразование float в int, int в строку и т. д. При проверке данных выводом будет сам фрейм данных, поскольку он проходит все проверки (попробуйте !!!). Если это не удастся, результат будет выглядеть примерно так:
Traceback (most recent call last): ... ValueError: cannot convert float NaN to integer
Я исследовал некоторые удивительные возможности Pandera, которые я постараюсь объяснить как можно подробнее.
Установка обязательных столбцов:
Иногда столбцы могут быть необязательными и необязательными. В таком случае мы можем установить required = False. По по умолчанию required = True для всех столбцов.
Как видно на скриншоте ниже, он вернул данные в виде выходных данных без каких-либо ошибок.

Попробуйте установить required = True для того же столбца и снова запустите указанный выше код.
Обработка новых столбцов:
По умолчанию, если новый столбец добавляется к фрейму данных и не определен в схеме, ошибка не возникает. Однако при желании можно установить strict = True.
Выполняя приведенный выше код, мы видим ниже, что он вызывает ошибки, которые ‘extra_column’ не определены в схеме.

Если вы видите мой код, я добавил lazy = True, который дает более подробное представление, как показано ниже:

Проверка индекса:
Индекс также может быть проверен, если существует какой-либо конкретный шаблон или имеет какое-либо особое значение в наборе данных. Например, см. Ниже:
Я создал и установил этот столбец в качестве индекса, чтобы показать, как мы можем выполнять проверку индекса. Вне скобок схемы можно указать ожидаемый формат индекса. Опять же, результат такой же, как и раньше.

Здесь мы выполнили единую проверку индекса. Аналогичным образом можно выполнить проверку MultiIndex. Проверьте здесь.
Преобразования DataSchema:

После того, как мы определили схему для проверки данных, можно преобразовать схему в самом конвейере после того, как были введены новые столбцы из-за дополнительных вычислений (что происходит в 100% случаев). Допустим, изначально у нас есть только столбцы Id, County, Province_State, Country_Region, Population. Мы добавляем в схему новые столбцы Weight, Date, Target, TargetValue следующим образом:
При печати схемы, как показано выше, мы получаем следующее:

С другой стороны, при необходимости мы также можем удалить некоторые столбцы из схемы, как показано ниже:

Проверка свойств столбца:
Более подробную проверку столбца можно выполнить с помощью объекта Проверить следующим образом:
В Pandera есть несколько встроенных проверок, которые можно использовать напрямую, например better_than_or_equal_to, less_than. Пользовательская проверка также может быть пройдена, например, здесь мы использовали аргумент лямбда для вычисления длины строки. Это одна из лучших функций Pandera, которая может принести гораздо больше пользы стратегии проверки данных. Подробнее здесь
Как и когда использовать:
- Я создаю отдельные сценарии, которые запускаются и выдают отчет о проверке после получения окончательных данных, прежде чем они перейдут к следующему шагу. Люди также могут интегрировать их как часть предварительной обработки.
- Их также можно использовать напрямую как декораторы. Смотрите, как здесь.
- Помимо использования непосредственно во фрейме данных, его также можно применить к серии, конкретной проверке столбца или даже поэлементной проверке .
- Благодаря гибкости операции с регулярными выражениями также могут выполняться с данными с помощью Pandera.
- Важно отметить, что с самого начала у вас не будет идеальной схемы проверки данных. Скорее всего, вы сделаете схему проверки данных «идеальной», а конвейер машинного обучения более надежным, включив различные стратегии проверки, когда вы сталкиваетесь с данными в реальном времени в течение длительного периода времени.
Другие пакеты:
Большие Надежды:
Как следует из названия пакета, вы можете установить ожидания для данных, которые будут проверяться. Честно говоря, я настолько освоился с Pandera, что у меня не было возможности исследовать весь потенциал. Кажется, довольно легко реализовать и использовать простой пакет. Ниже приведен небольшой фрагмент реализации тех же данных:
Цербер:
Это еще один пакет, синтаксис которого похож на Pandera. Его можно более эффективно применять, когда данные представлены в формате словаря или JSON.
Более подробную информацию о пакете можно найти здесь.
Дуршлаг:
Это еще один отличный пакет, если ваши данные получены через сообщение формы XML, JSON или HTML. Другими словами, полезно проверять любой тип строк, сопоставлений и типов данных списков. Ниже приведены некоторые из их полезных ссылок:
Github: https://github.com/Pylons/colander
Документация: https://docs.pylonsproject.org/projects/colander/en/latest/
JsonSchema:
JsonSchema - это реализация схемы JSON для Python. Как следует из названия, этот пакет очень полезен для проверки данных JSON. Возьмите следующий пример с действительными данными JSON и недопустимыми данными JSON:
При запуске неверных данных будет выдана ошибка:

Как мы видим, цена должна быть числовой, но точнее была указана строка. Подробнее об этом можно прочитать здесь.
Заключение:
Может показаться, что в этом посте в основном доминирует Pandera, поскольку это один из часто используемых мной пакетов. Написание этого поста было исключительно для того, чтобы поделиться путешествием, в которое я отправился. Я уверен, что для конкретного случая использования эти пакеты могут принести больше пользы. Часто преодоление лишнего километра может привести к выдающимся результатам. Проверка данных - это определенно «лишняя миля». Разработка стратегий проверки данных может показаться дополнительной работой, но можно определенно получить большую выгоду, если сформировать такую привычку создавать автоматизированные сценарии, даже для заботы о мелочах.
Пожалуйста, не стесняйтесь делиться своими комментариями и предложениями, если они у вас есть!