Представьте, что вам нужно просмотреть 2,5 ГБ (не часто, но время от времени) записи журнала неудачной сборки программного обеспечения - 3 миллиона строк - для поиска ошибки или регресса, произошедшего в строке 1M. Вероятно, это даже не выполнимо вручную! Тем не менее, одним из умных подходов к тому, чтобы сделать его управляемым, могло бы быть различие строк с недавней успешной сборкой в надежде, что ошибка приведет к появлению необычных строк в журналах.
Стандартный md5 diff будет работать быстро, но все равно произведет по крайней мере сотни тысяч строк-кандидатов для просмотра, потому что он выявляет различия на уровне символов между строками. Нечеткое различие с использованием кластеризации k-ближайших соседей из машинного обучения (что-то вроде logreduce) дает около 40 000 строк-кандидатов, но для завершения требуется час. Наше решение создает 20 000 строк-кандидатов за 20 минут вычислений - и, благодаря магии открытого исходного кода, это всего лишь около сотни строк кода Python.
Приложение представляет собой комбинацию нейронных встраиваний, которые кодируют семантическую информацию в словах и предложениях, и хеширования с учетом местоположения, которое эффективно назначает приблизительно близлежащие элементы одним и тем же сегментам, а удаленные элементы - разным сегментам. Комбинирование вложений с LSH - отличная идея, которая кажется менее десятилетней старой.

Примечание. Мы использовали Tensorflow 2.2 на ЦП с нетерпеливым выполнением для обучения передачи и scikit-learn NearestNeighbor для k-ближайших соседей. Существуют сложные реализации приближенных ближайших соседей, которые были бы лучше для решения ближайших соседей на основе модели.
Что такое вложения и зачем они нам понадобились
Сборка горячих слов - это типичная (полезная!) Отправная точка для решения проблем дедупликации, поиска и сходства вокруг неструктурированного или частично структурированного текста. Этот тип кодирования набора слов выглядит как словарь с отдельными словами и их количеством. Вот как будет выглядеть предложение войти в систему, проверить журнал.
{«Журнал»: 2, «вход»: 1, «ошибка»: 1, «проверка»: 1}
Эта кодировка также может быть представлена с помощью вектора, где индекс соответствует слову, а значение - счетчику. Вот «ошибка входа в систему, проверка журнала» как вектор, где первая запись зарезервирована для подсчета слов «журнала», вторая - для подсчета слов «в» и так далее.
[2, 1, 1, 1, 0, 0, 0, 0, 0, …]
Обратите внимание, что вектор состоит из множества нулей. Записи с нулевым значением представляют все другие слова в словаре, которых нет в этом предложении. Общее количество возможных векторных записей или размерность вектора - это размер словаря вашего языка, который часто составляет миллионы или больше, но может доходить до сотен тысяч с помощью некоторых хитрых уловок.
Теперь давайте посмотрим на словарные и векторные представления «аутентификации проблемы». Слова, соответствующие первым пяти элементам вектора, вообще не появляются в новом предложении.
{«Проблема»: 1, «проверка подлинности»: 1}
[0, 0, 0, 0, 1, 1, 0, 0, 0,…]
Эти два предложения семантически похожи, что означает, что они означают по существу одно и то же, но лексически различны настолько, насколько это возможно, то есть у них нет общих слов. В настройке нечеткого различия мы могли бы сказать, что эти предложения слишком похожи, чтобы выделить, но md5 и кодирование документов k-hot с помощью kNN не поддерживают это.

Снижение размерности использует линейную алгебру или искусственные нейронные сети для размещения семантически похожих слов, предложений и строк журнала рядом друг с другом в новом векторном пространстве, используя представления, известные как вложения. В нашем примере «ошибка входа, проверка журнала» может иметь пятимерный вектор встраивания.
[0.1, 0.3, -0.5, -0.7, 0.2]
и «проблема аутентификации» может быть
[0.1, 0.35, -0.5, -0.7, 0.2]
Эти векторы вложения близки друг к другу по меркам расстояния, таким как косинусное сходство, в отличие от их k-горячих векторов из набора слов. Плотные низкоразмерные представления действительно полезны для коротких документов, таких как строки сборки или системный журнал.
На самом деле, вы заменили бы тысячи или более измерений словаря всего 100 измерениями для вложения, богатыми информацией (а не пятью). Современные подходы к снижению размерности включают разложение по сингулярным значениям матрицы совпадения слов (GloVe) и специализированные нейронные сети (word2vec, BERT, ELMo).

А как насчет кластеризации? Вернуться к приложению журнала сборки
Мы внутри себя шутим, что Netflix - это сервис для ведения журналов, который иногда транслирует видео в потоковом режиме. Мы обрабатываем сотни тысяч запросов в секунду в области мониторинга исключений, обработки журналов и потоковой обработки. Возможность масштабирования наших решений НЛП просто необходима, если мы хотим использовать прикладное машинное обучение в областях телеметрии и журналирования. Вот почему мы позаботились о масштабировании нашей дедупликации текста, поиска семантического сходства и обнаружения текстовых выбросов - другого пути нет, если бизнес-задачи нужно решать в режиме реального времени.
Наше решение diff включает в себя встраивание каждой строки в вектор малой размерности и (при необходимости точную настройку или одновременное обновление модели встраивания), назначение ее кластеру и определение линий в разных кластерах как разных. Хеширование с учетом местоположения - это вероятностный алгоритм, который позволяет назначать кластеры с постоянным временем и выполнять поиск ближайших соседей с почти постоянным временем.
LSH работает путем сопоставления векторного представления со скалярным числом или, точнее, с набором скаляров. В то время как стандартные алгоритмы хеширования стремятся избежать коллизий между любыми двумя входами, которые не совпадают, LSH стремится избегать коллизий, если входы находятся далеко друг от друга, и продвигать их, если они разные, но расположены близко друг к другу. в векторном пространстве.
Вектор внедрения для ошибка входа в систему, журнал проверки может быть сопоставлен с двоичным числом 01 - и 01 тогда представляет кластер. Вектор внедрения для аутентификации проблемы с высокой вероятностью будет отображаться в одно и то же двоичное число 01. Таким образом LSH обеспечивает нечеткое сопоставление и обратную задачу - нечеткое различие. Ранние приложения LSH были над многомерными векторными пространствами из набора слов - мы не могли придумать ни одной причины, по которой он не работал бы с встраиваемыми пространствами так же хорошо, и есть признаки того, что другие имели имели та же мысль.

Работа, которую мы проделали по применению LSH и нейронных встраиваний в текстовом обнаружении выбросов в журналах сборки, теперь позволяет инженеру просматривать небольшую часть строк журнала для выявления и исправления ошибок в потенциально критически важном для бизнеса программном обеспечении, а также позволяет нам достичь семантической кластеризации практически любой строки журнала в реальном времени.
Теперь мы привносим это преимущество семантического LSH в каждую сборку Netflix. Семантическая часть позволяет нам группировать кажущиеся непохожими элементы на основе их значения и отображать их в отчетах о выбросах.
Несколько примеров
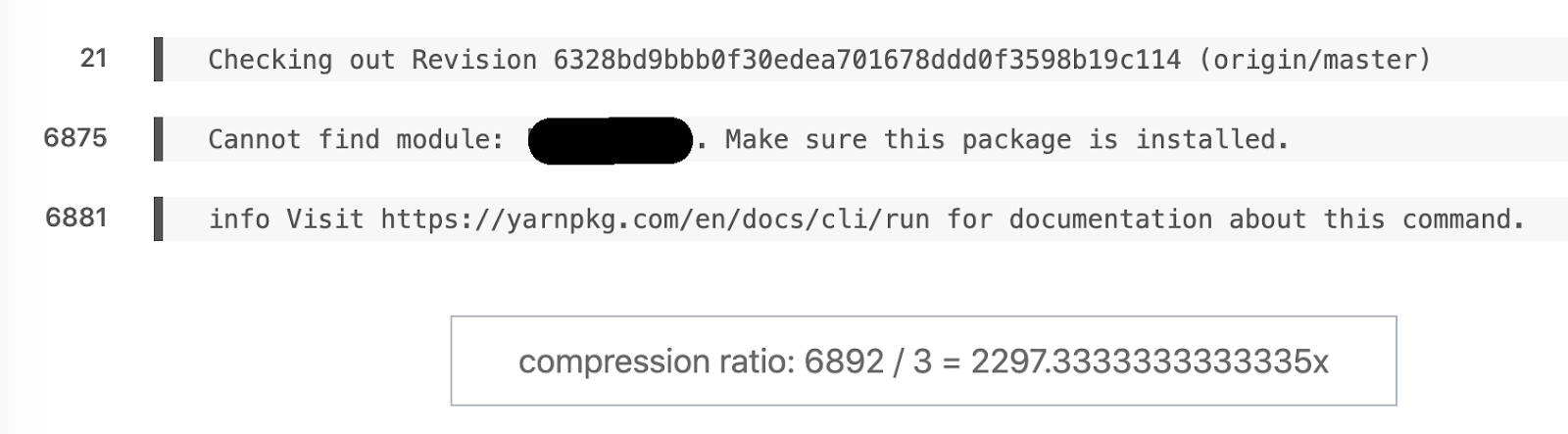
Это наш любимый пример семантического различия, с 6892 строк до всего 3.
Другой пример: эта сборка произвела 6044 строки, но в отчете осталась только 171. И основная проблема всплыла почти сразу на строке 4036.

Возвращаясь к примеру в начале, как мы получили такие большие журналы в сборках? Некоторые из наших тысяч заданий сборки стресс-тесты против потребительской электроники, где они выполняются в режиме трассировки. Объем данных, которые они производят, трудно использовать без предварительной обработки. В одном примере на более легком конце для синтаксического анализа сокращается с 91366 до 455 строк.
степень сжатия: 91366/455 = 200x

Существуют различные примеры, которые также отражают семантические различия между различными фреймворками, языками и сценариями сборки.
Заключение
Зрелое состояние продуктов и SDK для обучения передаче данных с открытым исходным кодом позволило нам решить семантический поиск ближайшего соседа с помощью LSH в очень небольшом количестве строк кода. Мы особенно заинтересовались особыми преимуществами, которые переносное обучение и точная настройка могут принести приложению. Мы рады возможности решать такие проблемы и помогать людям делать то, что они делают, лучше и быстрее, чем раньше.
Мы надеемся, что вы подумаете о том, чтобы присоединиться к Netflix и стать одним из замечательных коллег, чью жизнь мы облегчаем с помощью машинного обучения. Вовлеченность - основная ценность Netflix, и мы особенно заинтересованы в формировании разнообразных точек зрения на наши технические команды. Так что, если вы занимаетесь аналитикой, инженерией, наукой о данных или любой другой областью и имеете опыт, нетипичный для отрасли, мы особенно хотели бы получить известие от вас!
Если у вас есть какие-либо вопросы о возможностях Netflix, обратитесь к авторам в LinkedIn.