Используйте Rook / EdgeFS для добавления хранилища в кластер Kubernetes

В своей статье Создайте собственное домашнее облачное хранилище (Часть 1) я построил базовую сетевую систему хранения (NAS) на основе GlusterFS и NFS Ganesha. В последующих статьях я показал, как использовать новое решение для хранения данных в домашнем кластере Kubernetes. Но компьютер, который я использовал в качестве хранилища, имеет только 150 гигабайт на жестком диске, что немного, если вы хотите работать с большими данными. Кроме того, в Kubernetes это было статическое хранилище, в котором вы заранее определяли фиксированные PersistentVolumes.
Мне нужно решение для динамического хранения, которое позволит мне предоставлять постоянные тома по мере необходимости. Чтобы использовать GlusterFS таким образом, вам нужно использовать Heketi, и, глядя на это, оказалось, что это довольно сложно настроить. Кроме того, Heketi, похоже, находится в своего рода режиме квази-обслуживания, и для его поддержки не хватает людей. Что очень плохо, так как это казалось очень гибкой, хотя и сложной системой распределения памяти.
Так что я собираюсь отбросить весь этот опыт, который мне пришлось делать много в моей карьере, и пойти совершенно в другом направлении. Погугливал, я нахожу несколько статей о создании систем хранения для Kubernetes, и многие из них говорят о том, насколько это сложно. Так что эта статья может быть немного длинной, но я попытаюсь объяснить, шаг за шагом, как настроить что-то, что работает, без использования непонятной терминологии или непонятных настроек ядра. Возможно, это не оптимально, но я полон решимости заставить его работать. Это только для моей домашней песочницы. Это не похоже на то, чтобы передавать потоковое видео в голодный Интернет.
Если вы запускаете кластер Kubernetes от облачного провайдера, такого как GCP или AWS, ничего из этого вам не понадобится. В эти системы встроено динамическое распределение томов. Я делаю это здесь, чтобы показать, что может происходить за кулисами, в соответствии с целью моей статьи Kubernetes from Scratch.

Я смотрю на Rook с EdgeFS как на относительно простое, но гибкое решение для хранения данных. Rook / EdgeFS - это строго решение Kubernetes, поэтому у вас не будет отдельного хранилища; все это будет включено в систему Kubernetes. Я собираюсь взять свою существующую систему без операционной системы и добавить три новых узла для обработки всего постоянного хранилища для остальной системы в качестве кластера EdgeFS.
Я собираюсь начать с машины, которую я построил в статьях Kubernetes from Scratch и Kubernetes from Scratch (Part 2) », и добавлю три новые виртуальные машины, каждая из которых будет полностью контролировать одну треть. нового внешнего накопителя емкостью 4 терабайта. Я выбрал три, потому что для кластеров три - это наименьшее число, которое хорошо работает. Мне, наверное, следовало купить три однотерабайтных диска, но у них была сделка по поводу одного диска 4T, и я не могу отказаться от сделки.
Если вы не читали статьи «Kubernetes from Scratch», вам понадобится хост, способный запускать несколько виртуальных машин, как минимум с 32 гигабайтами ОЗУ и примерно с десятком ядер ЦП. Он также должен иметь, по крайней мере, уже установленный и работающий узел Kubernetes панели управления вместе с обычным набором надстроек, таких как сеть и вход. В моем случае я использую отремонтированный стоечный сервер. Это не очень красиво, но в плоской блестящей коробке умещается много вычислительной мощности. А моя кошка любит валяться на нем, потому что там приятно и тепло.
Однако, прежде чем мы создадим виртуальную машину, я собираюсь разделить жесткий диск на три части, чтобы каждая новая виртуальная машина получала полный контроль над одним разделом.
После подключения внешнего диска используйте lsblk, чтобы найти его имя.
Поскольку на моем компьютере всего один диск емкостью четыре терабайта, легко сделать вывод, что это sdb. Он уже разделен на sdb1 и sdb2, но мы это отменим.
Швейцарский армейский нож форматирования дисков Linux - fdisk. Предполагая, что диск sdb, как в моем случае, и запустите sudo fdisk /dev/sdb. Когда появится приглашение, введите «m», чтобы получить список команд:
Первое, что я сделаю, это «g», чтобы создать новую пустую таблицу разделов:
Command (m for help): g Created a new GPT disklabel (GUID: 743C7681-2815-C044-B0F0-BB82C7427D0D).
Затем команда «n» создаст новый раздел:
Command (m for help): n
Partition number (1-128, default 1):
First sector (65535-976754640, default 65535):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (65535-976754640, default 976754640): 325584880
Первые два значения были значениями по умолчанию. Я использовал 325584880 для третьего значения, потому что это треть от 976754640. Теперь мы запускаем команду «n» для второго раздела:
Command (m for help): n
Partition number (2-128, default 2):
First sector (325584880-976754640, default 488432355):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (488432355-976754640, default 976754640): 651169760
На этот раз я использовал 651169760 для последнего сектора. Введите «n» еще раз для последнего раздела.
Command (m for help): n
Partition number (3-128, default 3):
First sector (651169760-976754640, default 651169760):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (651169760-976754640, default 976754640):
На этот раз я смог установить все параметры по умолчанию. Теперь перечислите таблицу разделов с помощью команды «p»:
Наконец, введите «w», чтобы записать новую таблицу разделов. Еще раз используйте команду lsblk, чтобы посмотреть на свои блочные устройства:
Теперь вы можете видеть, что sdb делится поровну на sdb1, sdb2 и sdb3.
Теперь нам нужны три виртуальные машины, каждая из которых получит по одному разделу. Я использовал команду virt-install KVM для создания виртуальной машины с одним vcpu, двумя гигабайтами ОЗУ и одним из новых разделов диска. Вот как выглядела команда:
Имя будет node1, а диск будет /dev/sdb1, первый раздел.
Примечание. По моему опыту, 2048 мегабайт ОЗУ недостаточно, я заменил их на 4096 и 2 виртуальных процессора. Вдобавок
/dev/sdb1не согласуется при перезагрузках. Вместо этого я рекомендую использовать/dev/disk/by-partuuid/<partition-uuid>. найдите раздел-uuid с помощью командыlsblk -O.
По мере установки виртуальной машины мы можем принять значения по умолчанию для большинства параметров. Когда он запрашивает имя хоста, вы должны использовать node1 для единообразия.
Примечание: следующий раздел больше не работает с установщиком, начиная с 06.06.2020. Я рекомендую использовать разделение по умолчанию и создать каталог
/storageпозже.
Когда дело доходит до подготовки диска, вам нужно будет сделать два раздела, 20-гигабайтный раздел для ОС, а остальное будет использоваться в качестве области хранения. Выберите «Управляемый - использовать весь диск» и следуйте инструкциям, чтобы создать первый 20-гигабайтный диск в формате xfs, загрузочный и смонтированный на /. Другой раздел также должен быть xfs и установлен на /storage. Вы можете выбрать ext4 или другую файловую систему, но xfs звучит очень круто, так почему бы и нет? Ваш последний экран будет выглядеть так:

Выберите «Завершить разбиение на разделы и записать изменения на диск» и ответьте «да», когда вас спросят, уверены ли вы.
Вам снова будут предложены вопросы. Для большинства из них вы можете принять стандартный или разумный ответ. Когда вас спросят, какое программное обеспечение установить, просто выберите OpenSSH, который нам понадобится для связи с сервером.
После завершения установки используйте virsh domifaddr node1, чтобы найти IP-адрес и добавить его в свой /etc/hosts. Затем вы можете скопировать ssh-ключи основного хоста на новый хост с помощью ssh-copy-id node1.
Теперь сделайте то же самое для node2 и node3. Измените имя на node2 и node3 и используйте второй и третий разделы, которые мы создали. В моем случае это были /dev/sdb2 и /dev/sdb3.
Теперь у нас есть три виртуальные машины с объемом памяти около 1,2 терабайта каждая. Следующий шаг - сделать каждую виртуальную машину узлом Kubernetes и присоединить ее к основному кластеру. Нам нужно использовать ssh для каждого узла и выполнить следующие задачи.
Чтобы подготовить новую виртуальную машину к установке, сначала убедитесь, что подкачка отключена:
Включите мосты и наложения, добавив пару строк в ваш /etc/modules-load.d/modules.conf файл:
overlay br_netfilter
И добавьте пару строк в свой /etc/sysctl.conf файл:
# added for kubernetes bridge net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-iptables = 1
Затем перезагрузите виртуальную машину, чтобы все вступило в силу.
Поскольку Kubernetes - это система оркестровки контейнеров, нам нужна система контейнеров, которую она может организовать. Вы можете использовать несколько контейнерных систем, но мы собираемся использовать containerd. Для Ubuntu это двухстрочная установка:
sudo apt-get update sudo apt-get install containerd
Теперь вы можете установить святую троицу Kubernetes, kubeadm/kubectl/kubelet.
Чтобы проверить, что kubeadm имеет доступ кcontainerd, который мы установили раньше, мы можем запустить sudo kubeadm config images pull. Он потратит некоторое время на создание нескольких необходимых ему изображений, и мы знаем, что он может разговаривать с containerd.
Теперь нам нужно join новый узел в существующий кластер. Вам нужно будет подключиться к своему узлу панели управления по ssh, в моем случае kube1, и получить новый токен, чтобы позволить новому узлу присоединиться:
rkamradt@kube1:~$ kubeadm token create --print-join-command
kubeadm join 192.168.122.39:6443 --token XXXXX.XXXXXXXXXXXXX \
--discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXX
Скопируйте вывод этого, а затем ssh на свой новый узел и запустите его (префикс sudo).
sudo kubeadm join 192.168.122.39:6443 --token XXXXX.XXXXXXXXXXXXX \
--discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXX
Вернувшись на свой основной хост, вы можете перечислить узлы:
rkamradt@beast:~$ kubectl get nodes NAME STATUS ROLES AGE VERSION kube1 Ready master 37d v1.18.1 kube2 Ready <none> 37d v1.18.1 kube3 Ready <none> 35d v1.18.1 kube4 Ready <none> 35d v1.18.1 node1 Ready <none> 13m v1.18.2
Некоторое время может не отображаться сообщение «Готов»; потребовалось несколько минут, чтобы перебрать все данные между новым узлом и кластером. Мы предоставили узлам только два гигабайта памяти, поэтому все немного затруднительно, но единственное, что мы должны запускать на новых узлах, - это связанные с хранилищем.
Теперь установите узлы Kubernetes на двух других виртуальных машинах.
После того, как все ваши узлы будут запущены, мы можем установить Rook и запустить кластер хранения. Сначала запустите базовую систему. На главном хосте запустите следующее:
git clone --single-branch --branch master \
https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/edgefs
kubectl create -f operator.yamlЭто было довольно просто. Теперь подождите минуту, а затем убедитесь, что все работает.
Вы заметите, что rook-discover - это daemonset. daemonset - это особый вид replicaset, который гарантирует, что на каждом рабочем узле работает один модуль. У нас шесть рабочих узлов, так что у вас должно быть шесть подов.
Как только все заработает, мы можем настроить топологию и развернуть кластер EdgeFS в подах Kubernetes. В каталоге rook/cluster/examples/kubernetes/edgefs находится файл с именемcluster.yaml, который нужно немного отредактировать. По большей части это нормально, но фактическое определение кластера в конце файла должно знать о наших узлах и дисках. Вот новое определение кластера для только что созданной установки:
Обратите внимание, что forspec.storage.directories.path существует только одна запись. У всех узлов должен быть один и тот же путь к подключенным дискам, который мы настроили ранее. Удалите определение кластера в конце cluster.yaml и замените его приведенным выше. Тогда вы можете применить это: kubectl apply -f cluster.yaml.
Я скопировал все эти файлы в репозиторий GitHub под названием storage-deploy. На нем я разделил cluster.yaml на два файла, clusterprep.yaml и cluster.yaml, последний файл содержал только определение кластера.
Через некоторое время вы должны увидеть что-то вроде этого:
Теперь у вас работает один модуль rook-edgefs-mgr и три модуля rook-edgefs-target. Целевые модули находятся на каждом из ваших узлов. Только что созданные узлы Kubernetes были преобразованы в edgefs узлы 1–3. Обратите внимание, что у вас также есть rook-edgefs-ui. Я собираюсь раскрыть это через вход (определения вы можете найти на вышеупомянутой странице GitHub). Затем, добавив rook.local в мой /etc/hosts файл, я могу перейти на https: //rook.local. Войдите в систему под именем пользователя admin и паролем edgefs и взгляните на свой кластер EdgeFS во всей красе графического интерфейса пользователя!
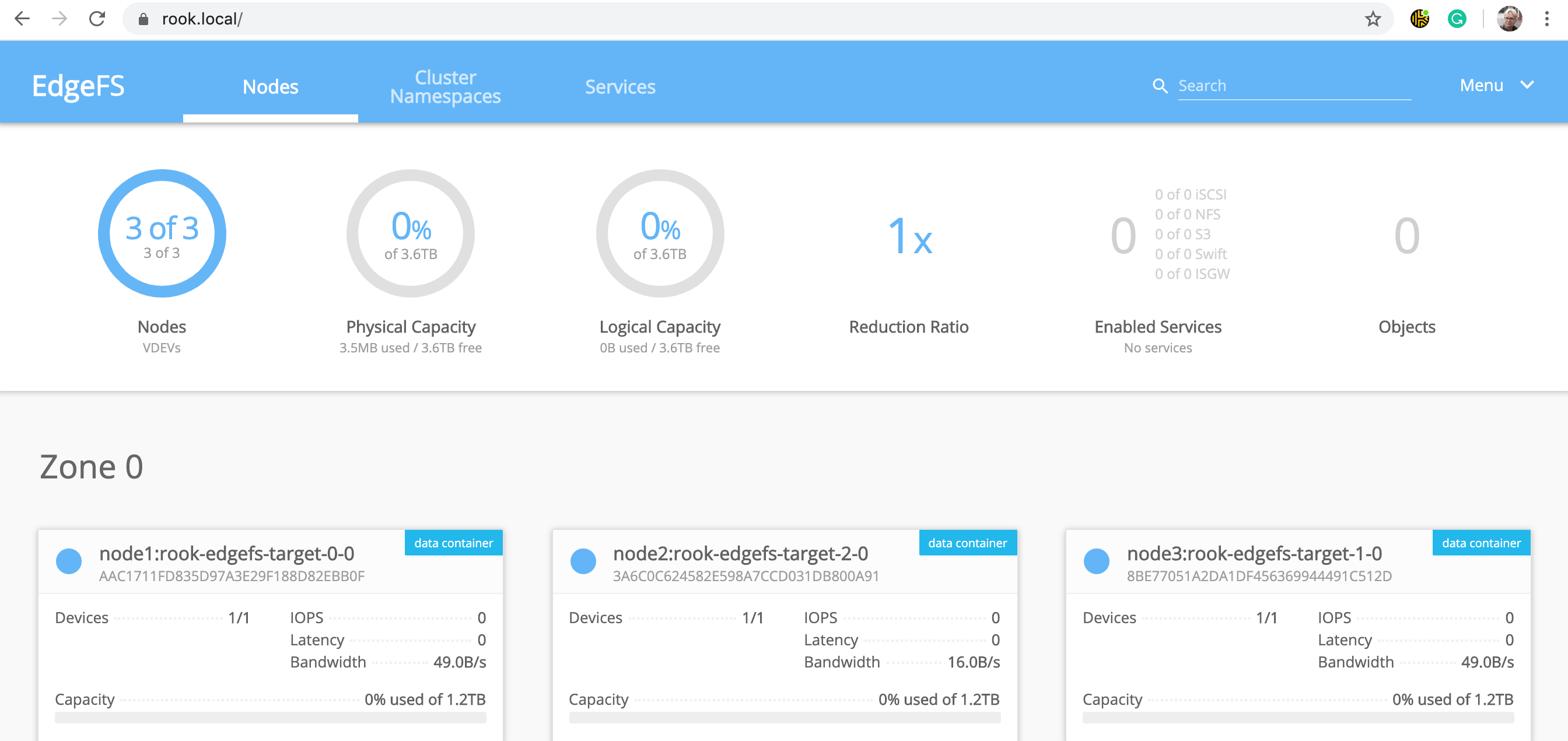
В следующей статье я обещаю что-нибудь сделать со всем этим новым хранилищем, доступным в моем кластере Kubernetes. Но до тех пор я собираюсь погреться в лучах истинного настроения и запуска кластера EdgeFS.
Это был долгий путь, и если вы прошли его до конца, я вам аплодирую. Если вы действительно запустили его, это будет большим достижением. По пути мне пришлось устранять множество разных проблем. То, что я объясняю все это линейным повествованием, не означает, что мне не пришлось несколько раз отступать, чтобы все исправить. Но я надеюсь, что мои усилия дали вам инструкции, необходимые для правильной сборки этой штуки.
Вот репозиторий GitHub для скриптов из этой статьи: https://github.com/rkamradt/storage-deploy/tree/v1.0
Другие упомянутые статьи: