TL; DR: в основном речь идет о преобразовании исходной бумаги для ознакомления [1] группы Йошуа Бенжио в блок-схемы. Проверьте последнюю диаграмму перед приложением, чтобы увидеть полную блок-схему.
Эпистемический статус: я пытаюсь правильно понять механизм внимания на уровне, на котором я знаю, как применить его к любому типу данных / проблеме или любой модальности, и как настроить его, чтобы улучшить. Эта статья похожа на мои собственные заметки, чтобы научить себя. Наконец, поскольку я сам не реализовал механизм внимания, я недостаточно квалифицирован и самоуверен, когда пишу это.

Мотивация: Большинство объяснений в Интернете хорошо поработали в объяснении о чем« механика внимания » о, но не точных механических деталях того, как она работает, например, какой вектор сочетается с какой матрицей. Хотя исходная статья делает это действительно хорошо, она похожа на очень сжатую версию, типичную для академического письма, а это означает, что мне нужно приложить много усилий, чтобы ее распечатать. Это то, что.
Краткая предыстория
В оригинальной статье рассматривается конкретная проблема Обработки естественного языка (NLP), которая представляет собой задачу машинного перевода, перевод предложения с исходного языка на целевой язык. Он сформулирован как архитектура кодер-декодер последовательность-последовательность (seq2seq), которая обычно выполняется с использованием вариаций RNN, таких как LSTM и GRU, которые представляют собой класс алгоритмов глубокого обучения. часть Искусственной нейронной сети (ИНС), которая является парадигмой искусственного интеллекта (ИИ), управляемой данными / машинным обучением, а не парадигмой, управляемой моделями. В остальной части статьи предполагается, что вы знакомы с этими концепциями.
Ванильный РНН

Bahdanau et. al. описал типичный блок кодера RNN с помощью следующего уравнения. Я распаковал это уравнение с помощью следующей диаграммы. x_t - это слово в виде вектора. Функция f (.) Обычно представляет собой некоторый тип RNN, например LSTM и GRU. В статье используется Двунаправленная RNN (BiRNN). Наконец, h_t - это скрытые состояния RNN.
Полная архитектура кодировщика приведена ниже, где c - вектор, кодирующий все предложение. Обычно c = h_T, что в основном является последним скрытым состоянием RNN.

Ниже представлена полная структура типичного кодировщика-декодера seq2seq RNN с преувеличенными ошибками при переводе. Представьте себе язык, где информация о расстоянии (здесь и там), счетности (много против много) и пол / возраст / число (мужчины против девушки) содержится в одном слове, переводимая на Другой язык, где эта информация должна быть разбита на несколько слов, которые могут даже не примыкать друг к другу, или наоборот. Более того, существует также проблема глагола« быть », особенность, которая не универсальна для всех языков. Тогда мы сможем увидеть такие ошибки.

(Я делаю вид, что функция g (.) Производит следующее слово (технически слово вектор, из-за встраивания, но с этого момента я буду называть его просто «словами»). В статье это фактически вектор вероятности всех слов. Но это не важное различие в механизме внимания.)
Ограничение ванильного РНН
Поскольку механизм внимания применяется только к части декодера, мы можем игнорировать часть кодера и сосредоточиться на H, который является набором всех h_j. (В исходной статье есть изменение обозначений, поэтому я отражаю его здесь. «J» - это индекс для части кодера, «i» - это индекс для части декодера, которая раньше была «t».)

Во-первых, в механизме внимания мы собираемся использовать H, набор всех h_j (набор всех скрытых состояний) вместо последнего, так что давайте оставим его там. Во-вторых, для упрощения мы сосредоточимся на одном блоке декодера RNN, как показано справа на рисунке выше.
Функция g (.) (Блок RNN) несет основную ответственность за создание следующего слова (вектора, встроенного) y_i. Это решение принимается путем объединения информации из c (представляющего ВСЕ ПРЕДЛОЖЕНИЕ на исходном языке), y_i (предыдущее слово), s_i (предыдущее скрытое состояние).
Авторы осознали, что использование c - действительно плохой способ делать что-то. Прежде всего, когда человек пытается перевести следующее слово (при условии, что он уже определил порядок слов), он сосредоточится (читай: ОБРАТИТЕ ВНИМАНИЕ) только на одном (максимум, нескольких) словах. , а не все предложение. Тем не менее, используя c в качестве входных данных, архитектура сети / модели в некоторой степени предполагает, что мы должны попытаться вычислить следующее слово из какого-то целостного понимания ВСЕГО ПРЕДЛОЖЕНИЯ, что совершенно определенно не так.
(Почему несколько слов вместо одного? В зависимости от языка (особенно при переводе с аналитического языка на синтетический) мы должны выяснить, какую форму использовать в зависимости от контекста. Многие языки меняют форму в зависимости от множества различных Грамматический аспект, такой как единственное / множественное число, мужской / женский / средний, прошлое / настоящее / будущее и т.д. »На английский он / она). Сеть должна обращать внимание на слово 'dia' и любое слово, которое может указывать на пол человека, о котором идет речь. , чтобы правильно перевести.)
Суть внимания

Суть внимания в том, чтобы заменить общую букву «c» КОНТЕКСТНЫМ ВЕКТОРОМ c_i. Вместо того, чтобы давать декодеру одно и то же «c» на каждом шаге, мы будем давать декодеру разные c_i на каждом шаге. Есть надежда, что этот c_i уделит внимание релевантным словам в исходном предложении.
Для этого функции c (.), Которая генерирует вектор контекста c_i, требуется подробная информация об исходном предложении (поэтому мы используем векторы аннотаций H, а не только последний h_j) и текущем скрытом состоянии RNN декодера s_i ( отсюда красная стрелка). В идеале контекстный вектор c_i будет содержать много информации о релевантных словах и мало информации о других, менее значимых словах.
Как на самом деле реализован декодер

На каждом этапе декодирования есть 3 важных выхода:
- y_i, слово на целевом языке.
- s_i, текущее скрытое состояние RNN декодера текущего временного шага.
- c_i, взвешенное представление исходного предложения (вес основан на внимании).
[Я не уверен, что это истинная мотивация, но…] Имеет смысл иметь 3 разных модуля, каждый из которых отвечает за каждый вывод: c (.), F (.) И g (.):
- c(H,s_i-1) = c_i
- f(c_i, s_i-1, y_i-1) = s_i
- g(c_i, s_i, y_i-1) = y_i
Наконец, внимание!
Последний вопрос: как вычислить векторы контекста c_i? Лучше всего это можно объяснить с помощью приведенной ниже полномасштабной модели (которая, учитывая аннотацию, я надеюсь, не требует пояснений).
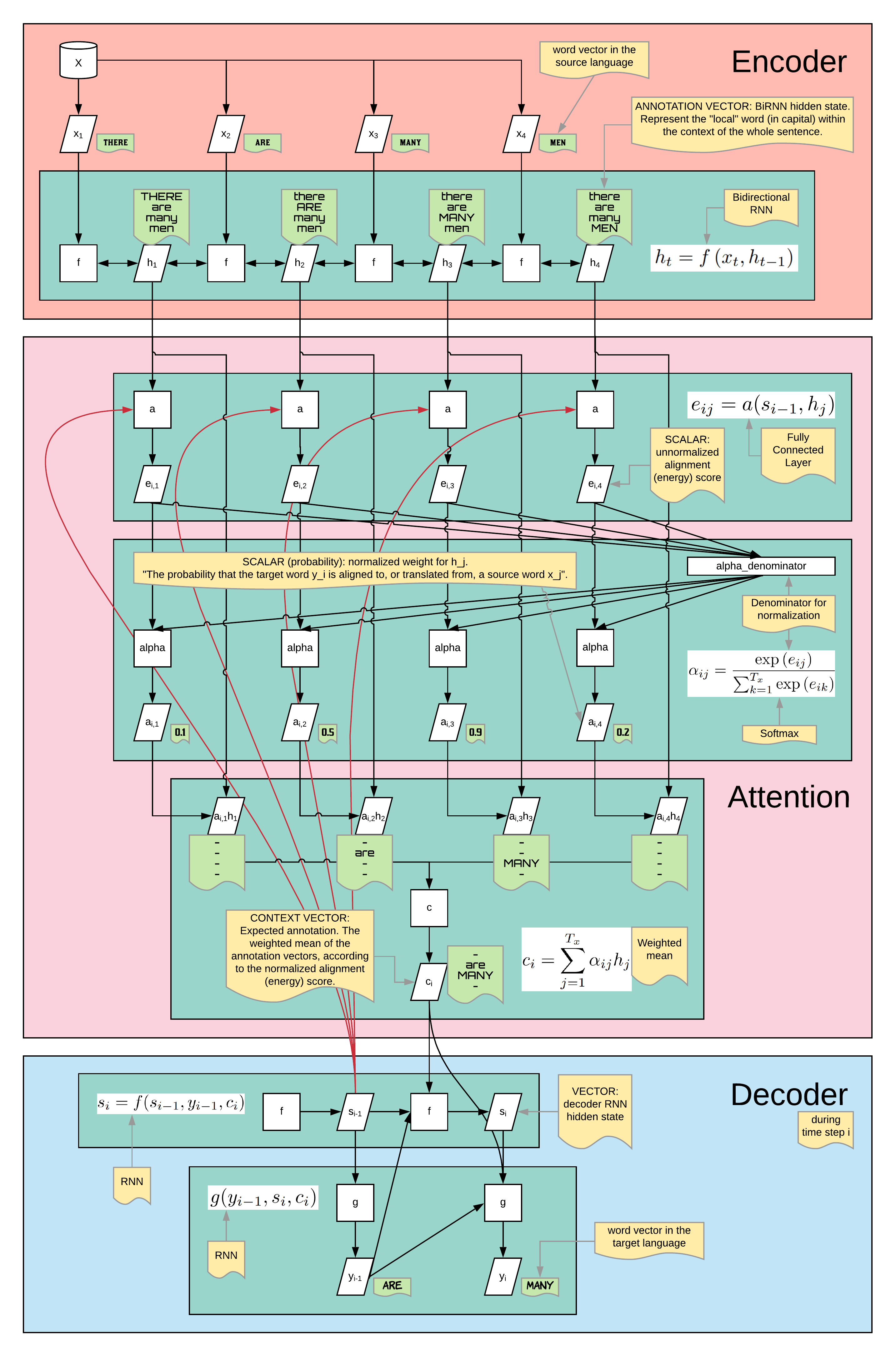
Самая важная часть - это оценка выравнивания e_i, j. (По какой-то непонятной мне причине это также называется энергией). Он вычисляет релевантность каждого слова на исходном языке (представленном аннотацией h_j) на основе текущего скрытого состояния RNN декодера. Затем мы придаем больший вес более релевантным словам и меньший вес менее релевантным словам. Это эквивалентно уделению внимания более релевантным словам. Следующий шаг - просто «нормализовать» веса с помощью softmax. (По какой-то непонятной мне причине это эквивалентно вероятности). Наконец, мы вычисляем средневзвешенное значение всех слов в предложении исходного языка, в результате чего получаем вектор контекста c_i.
Приложение


Чтобы получить знаменитую фигуру матрицы выравнивания, просто нанесите на график все a_i, j, где i - столбец, а j - строка.
Мягкое внимание и жесткое внимание
Механизм внимания, который здесь описывается, можно рассматривать как мягкое внимание, так как он использует softmax. Если бы использовалась функция max (.), То c_i было бы просто наиболее релевантным вектором слов. Это может быть менее выгодно, поскольку некоторые слова совпадают с несколькими словами на другом языке. Что еще более важно, мы не можем использовать обратное распространение через max (.), В то время как мы можем сделать то же самое с softmax.
Ссылки и благодарности
[1] Д. Богданау, К. Чо и Ю. Бенжио, Нейронный машинный перевод путем совместного обучения согласованию и переводу (2015 г.), Международная конференция по обучающим представлениям (ICLR)
Sichen за то, что научил меня тому, как работает внимание.
Все изображения принадлежат мне, если иное не указано в подписи.