PCA и кластеризация в Python
В этом посте я покажу, как использовать несколько техник НЛП для преобразования слов в математические представления и изобразить их в виде точек, а также приведу несколько примеров. График ниже был создан на основе вики Звездных войн Вукипедия и раскрашен алгоритмом кластеризации.

Координаты слов создаются из вложений слов (векторов слов), которые создаются на основе контекстов, в которых встречается каждое слово. Векторы имеют свойства, связанные со значениями слов, приблизительно удовлетворяющие уравнениям типа (vector for “Paris”) - (vector for “France”) + (vector for “Italy”) ≈ (vector for “Rome”) - т.е. вы можете взять Париж, заменить Италию на Францию, и вы получите Рим. Кластеризация и построение графиков также выявляют интересные закономерности; если вы смотрели Звездные войны, вы могли заметить, что алгоритм кластеризации бессознательно разделяет людей, места и организации.
Весь код доступен на github.com/LogicalShark/wordvec
Сбор данных
Найдите подходящий корпус для вашего анализа или для более общих целей, таких как поиск стран или фильмов, вы можете использовать общий текстовый корпус. Получите достаточно данных, чтобы получить значимые вложения слов, но всего 50 КБ или меньше может быть достаточно, если все это актуально.
Я проанализировал собственные имена из франшиз, которые мне лично нравятся, и если вы хотите сделать то же самое, я рекомендую проверить вики франшизы Fandom на наличие дампа базы данных по адресу something.fandom.com/wiki/Special:Statistics (хотя, к сожалению, некоторые не предоставляю дампов баз данных).
Создание векторов слов
Для создания векторов нам нужны слова, которым они соответствуют, что требует разбиения текста на слова. Затем мы можем использовать Word2Vec (модель создания векторных слов) для создания векторов. Чтобы получить список слов, я использовал токенизатор слов NLTK, а для реализации Word2Vec - gensim. Вот еще несколько подробностей об обработке текста:
Ограничения памяти: входные данные были слишком велики, чтобы ими можно было манипулировать сразу, но поскольку Word2Vec может принимать итератор в качестве входных данных, я создал собственный итератор, который принимает файлы по одной строке для токенизации.
Синонимы: некоторые имена, написанные разными способами, которые мы хотим представить в одном векторе, например, Донки Конг = DK или Оби-Ван Кеноби = Бен Кеноби. Вместо того, чтобы комбинировать выходные векторы, мы можем предотвратить проблему с заменой строки на входе. Например, замена всех экземпляров «Donkey Kong» на «DK» означает, что этот символ представлен одним вектором для слова «DK» вместо двух.
Выражения из нескольких слов. Иногда нам нужно, чтобы один вектор представлял несколько слов (например, Хан Соло, Peach’s Castle), но слова разделяются токенизацией и становятся отдельными векторами. Я использовал токенизатор многословных выражений NLTK (MWEtokenizer), который позволяет вам добавлять эти имена в качестве настраиваемых фраз для повторной конкатенации после вывода токенизации слова. Альтернативой была бы повторная замена строки (замените «Han Solo» на «HanSolo»), но я обнаружил, что MWEtokenizer проще.

Сводка. Итератор берет каждую строку в файле, выполняет замены для согласованности синонимов, выполняет токенизацию слов и, наконец, уплотняет многословные выражения. Word2Vec принимает итератор в качестве аргумента вместо списка слов и создает модель с векторами слов.
Графическое изображение векторов слов
У слов очень разные контексты, а это значит, что у векторов есть много функций. Вместо построения графиков по трем характеристикам мы можем использовать Анализ главных компонентов (PCA) для расчета линейной комбинации функций, обеспечивающих ортогональные оси с наибольшим разбросом. Для дальнейшей визуализации шаблонов цвета текста точки устанавливаются с помощью кластеризации k-means ++ (с использованием sklearn), которая автоматически создает k «кластеры». Я использовал matplotlib для построения графиков, получая такой интерактивный график:

Для создания векторов использовалась вики Super Mario Fandom. k=3 кластеризация, кажется, создает кластер «главный персонаж», кластер «местоположение / второстепенный персонаж» и кластер «игровой». Дейзи, Валуиджи и Жаба удачно расположены между главными и второстепенными персонажами. Если Donkey Kong кажется немного ближе к игровому кластеру, чем другие главные герои, то это потому, что Donkey Kong одновременно является персонажем и оригинальной аркадной игрой!

Иногда бывает достаточно двухмерных графиков, чтобы показать закономерности. Позиции и кластеры по оси X на приведенном выше графике приблизительно коррелируют с присутствием на экране каждого символа, что соответствует этой диаграмме:
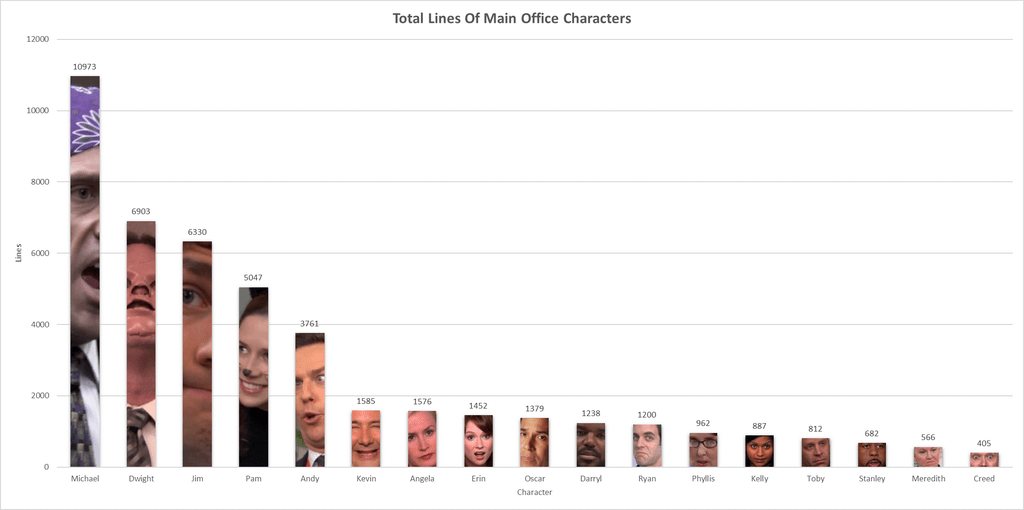
Небольшие спойлеры для Hollow Knight во втором сюжете ниже!

Больше графиков и векторной арифметики слов

Что касается арифметики, функция most_similar_cosmul найдет приближенные решения для векторного сложения каждого слова в positive и вычитания слов в negative. Я счел полезным поставить на одно положительное слово больше, чем отрицательное, для сети из одного слова-вектора. Это включает одно слово в положительном и пустом отрицательном.
Wvlinear.py использует эту функцию для поиска уравнений. Однако несвязанные друг с другом слова часто сочетаются по чистой случайности, поэтому я рекомендую искать отношения самостоятельно с помощью wvarith.py.
Спасибо за чтение! Весь код и некоторые образцы моделей доступны на github.com/LogicalShark/wordvec. Дайте знать, если у вас появятся вопросы!