
GloVe: глобальные векторы для представлений слов
В этом посте мы рассмотрим подход, использованный при построении модели GloVE, а также реализуем код Python для извлечения встраивания с учетом определенного слова в качестве входных данных.
По сути, все разработанные языковые модели стремились к достижению одной общей цели - реализации возможности переноса обучения в НЛП. Таким образом, разные образовательные и коммерческие организации искали разные подходы к достижению этой цели.
Одним из таких известных и хорошо зарекомендовавших себя подходов было построение матрицы совпадения слов с огромным корпусом. Этот подход был использован группой исследователей из Стэнфордского университета, который оказался простым, но эффективным методом извлечения вложений слов для данного слова.
Содержание:
- Обзор встраиваемых слов
- Введение в матрицу совместной встречаемости
- Функция затрат для оптимизации
- Реализация Python
Краткий обзор встраиваемых слов:
Вложения слов - это векторные представления слов, которые помогают нам извлекать линейные подструктуры, а также обрабатывать текст таким образом, чтобы модель лучше его понимала. Обычно вложения слов являются весами скрытого слоя архитектуры нейронной сети после того, как определенная модель сходится к функции стоимости. Для более глубокого понимания этого см. Ниже:
Теория встраивания слов в Word2Vec
Введение в матрицу совместной встречаемости
Давайте начнем понимать матрицу совместной встречаемости с ее определения. Матрица совпадения, в первую очередь, дает информацию о частоте встречаемости двух слов вместе в огромном корпусе. Рассмотрим скриншот ниже,
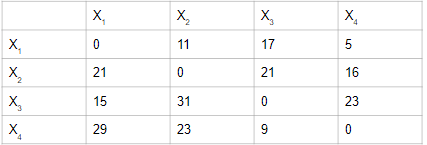
Здесь X1, X2 и т. Д. - уникальные слова в корпусе, а Xij представляет частоту появления Xi и Xj вместе во всем корпусе. Хотя эта матрица в целом не обязательно служит нашей цели, она просто становится целью, на которой обучается нейронная сеть. Другими словами, при вводе одного вектора горячего встраивания конкретного слова (как и в Word2Vec) модель обучается предсказывать матрицу совместной встречаемости.
Итак, в целом прогнозирование матрицы совместной встречаемости - это фальшивая задача, которая была определена для того, чтобы извлечь вложения слов после схождения модели.
Функция затрат:
Для сходимости любой модели машинного обучения ей по сути нужна функция затрат или ошибок, которую можно оптимизировать. В этом случае функция стоимости:
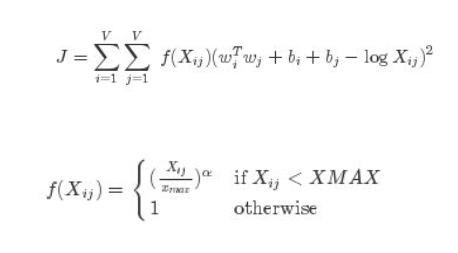
Здесь J - функция стоимости. Итак, давайте рассмотрим термины один за другим:
- Xij - частота появления Xi и Xj вместе в корпусе.
- Wi и Wj - вектор слов для слова i и j соответственно.
- bi и bj соответствуют смещениям относительно слов i и j.
Во втором уравнении Xmax - это порог максимальной частоты одновременного появления, параметр, определяемый для предотвращения потери веса скрытого слоя. Итак, функция f (Xij) по сути является ограничением, определенным для модели.
После того, как функция стоимости оптимизирована, веса скрытого слоя становятся вложениями слов. Вложения слов из модели GLoVE могут иметь вектор размером 50 100 размерностей в зависимости от выбранной нами модели. По приведенной ниже ссылке представлены различные типы моделей GLoVE, выпущенные Стэнфордским университетом, которые доступны для загрузки.
Модель GLoVE: Стэнфордская группа
Реализация Python
Чем выше количество токенов и словарный запас, тем лучше производительность модели. Кроме того, нам необходимо рассмотреть имеющуюся архитектуру, чтобы использовать правильную модель для более быстрых вычислений. Мы будем использовать 100-мерную модель перчатки, обученную на данных Википедии, для извлечения вложений слов для данного слова в Python.

Кроме того, команда print (embedding_index [‘banana’]) дает вектор внедрения слова для слова банан, и аналогично, вектор внедрения для любого слова может быть извлечен. Следуйте приведенному ниже фрагменту кода, чтобы найти индекс подобия косинуса для каждого слова.

Кроме того, можно извлекать линейные подструктуры, что обсуждалось в моем предыдущем посте.
Ссылка ниже перенаправляет вас к файлу кода для извлечения вложений слов в python из предварительно обученной модели GLoVE.
Вложения слов из модели GLoVE 100D
Следите за этим пространством для получения дополнительной информации о встраиваниях, так как я планирую написать серию сообщений, посвященных BERT и его приложениям. Мы будем благодарны за любые отзывы об этом.