В этом блоге мы анализируем настроения твитов, которые имели место во время президентских дебатов в августе 2016 года в Огайо. Мы провели как категоризацию данных, так и анализ контента, чтобы ответить, был ли твит релевантным, какой кандидат упоминал больше всего в твитах и тональность твита.
Считайте данные в R, данные также доступны в базе данных SQL, но здесь мы загрузили файл CSV в R.
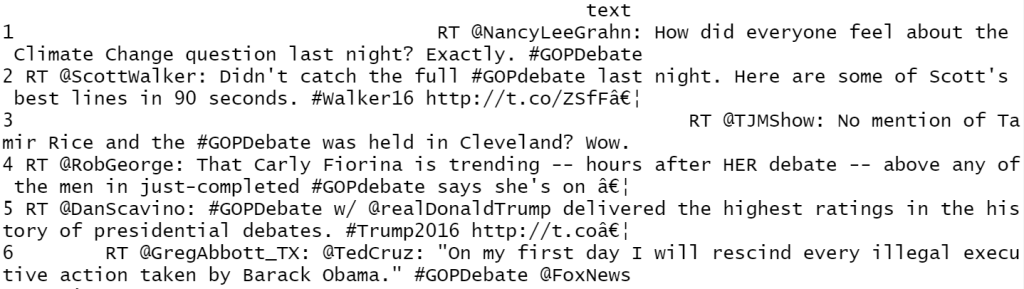
data=read.csv("Sentiment.csv") head(data)
Структурирование данных - самая важная часть этого процесса. Набор данных «Настроение» содержит различную другую информацию, которая не имеет отношения к этому, чтобы выбрать здесь конкретно столбцы «текст» и «тональность» и исключить остальное.
library(tidyverse) datas=data%>%select(text,sentiment) head(datas) round(prop.table(table(datas$sentiment)),2)
Вывод после структурирования данных:

Очистка данных:
library(tm) library(SnowballC) corpus = VCorpus(VectorSource(datas$text)) corpus = tm_map(corpus, content_transformer(tolower)) corpus = tm_map(corpus, removeNumbers) corpus = tm_map(corpus, removePunctuation) corpus = tm_map(corpus, removeWords, stopwords("english")) corpus = tm_map(corpus, stemDocument) corpus = tm_map(corpus, stripWhitespace) as.character(corpus[[1]])
Вывод после очистки текста:
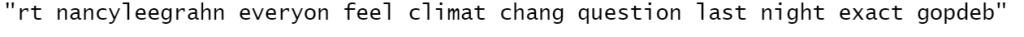
Для подсчета частоты каждого слова во всем документе мы используем другой термин, известный как матрица терминов документа, который делает нашу функцию корпуса более представимой в числовом выражении.
dtm = DocumentTermMatrix(corpus) dtm dim(dtm) dtm = removeSparseTerms(dtm, 0.999) dim(dtm)
Ниже показан список слов из нашего текста, повторяющийся как минимум более 100 раз.

Визуализация текстовых данных с помощью облака слов, которое дает лучшее представление о наиболее часто употребляемых словах в каждой тональности.
library(wordcloud)
library(ggplot2)
install.packages("RColorBrewer")
#wordcloud requires RColorBrewer positive= subset(datas,sentiment=="Positive") wordcloud(positive$text, max.words = 100, colors = "blue") negative = subset(datas,sentiment=="Negative") wordcloud(negative$text, max.words = 100, colors = "purple") neutral = subset(datas,sentiment=="Neutral") wordcloud(neutral$text, max.words = 100, colors = "turquoise")
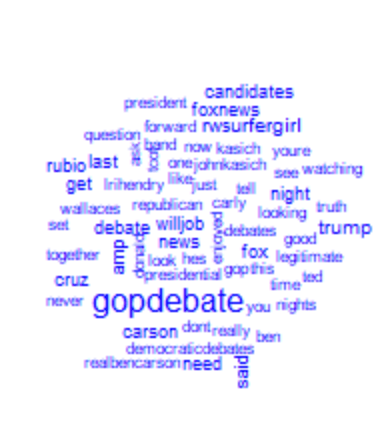
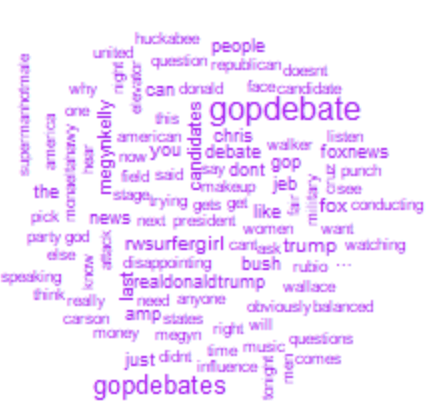

Кроме того, мы использовали алгоритм машинного обучения «Наивный Байес» для прогнозирования, обсуждаемого ниже.
#As naive bayes algorithm excepts binary
convert <- function(x) {
y <- ifelse(x > 0, 1,0)
y <- factor(y, levels=c(0,1), labels=c("No", "Yes"))
y
}
datanaive = apply(dtm, 2, convert)
dataset = as.data.frame(as.matrix(datanaive))
dataset$Class = datas$sentiment
str(dataset$Class)
Разделение данных
set.seed(31)
split = sample(2,nrow(dataset),prob = c(0.75,0.25),replace = TRUE)
train_set = dataset[split == 1,]
test_set = dataset[split == 2,]
prop.table(table(train_set$Class))
prop.table(table(test_set$Class))


# naive bayes
install.packages("e1071")
library(e1071)
library(caret)
control= trainControl(method="repeatedcv", number=10, repeats=2)
system.time( classifier_nb <- naiveBayes(train_set, train_set$Class, laplace = 1,trControl = control,tuneLength = 7) )
Выход модели:

Оценка модели Наивного Байеса и прогнозируемая точность составляет 98,67%, что показано ниже:
# model evaluation
nb_pred = predict(classifier_nb, type = 'class', newdata = test_set)
confusionMatrix(nb_pred,test_set$Class)
Статистика наивной байесовской модели:

Спасибо, что прочитали мою статью. Надеюсь, вы получили некоторое представление о том, как алгоритм машинного обучения работает с контент-анализом.