Теория и приложения в науке о данных

Экспериментирование лежит в основе бизнес-решений, независимо от того, работаете ли вы в бумажной компании или в крупнейшей в мире многонациональной технологической компании. Джефф Безос из Amazon был процитирован:
«Наш успех в Amazon зависит от того, сколько экспериментов мы проводим в год, в месяц, в неделю, в день…»
В этом посте мы более подробно рассмотрим проверку гипотез, используя материалы курса из Williams College MATH 162, в частности Проверка гипотез с использованием статистики Адама Мэсси и Стивена Дж. Миллера ». Желательно заранее ознакомиться с A / B-тестированием и биномиальным распределением.
Мы покажем, как мы можем проверить, являются ли наблюдаемые различия в пропорциях случайными или есть действительно существенные различия. Затем мы обобщим эту концепцию на категориальные переменные.
В обоих случаях мы:
- Представьте гипотетический бизнес-кейс
- Пройти теорию
- Решите случай с помощью Python 3.
Не стесняйтесь подписываться на Блокнот GitHub!
Тестирование пропорций K

Пример использования: регистрация на Udemy
Рассмотрим случай, когда мы ведем бизнес по онлайн-обучению, такой как Udemy.com, и после изменения главной страницы видим рост числа регистраций: наблюдаемые различия в пропорциях являются случайными или они существенно отличаются?
K Теория пропорций
Чтобы ответить на этот вопрос, предположим, что у нас есть X1, X2... Xk независимые случайные величины с Xi, имеющими биномиальное распределение с параметрами ni (количество испытаний) и θi (вероятность успеха). Таким образом, у нас есть K популяций, и каждая из них связана ровно с одной пропорцией.
Если x1, x2... xk - наблюдаемые значения из этих распределений, и если все ni достаточно велики, то мы можем использовать центральную предельную теорему, чтобы аппроксимировать каждое из них с помощью стандартной нормы (z-оценка):

Поскольку каждое из них дает нормальное распределение, мы знаем, что следующее будет распределение хи-квадрат с K степенями свободы:

Поэтому мы хотим проверить нулевую гипотезу Ho: θ1= θ2 ...= θK = θ0
Наша альтернативная гипотеза состоит в том, что некоторые θi отличаются от θ0.
Мы хотим построить нашу критическую область размером α (альфа) так, чтобы:
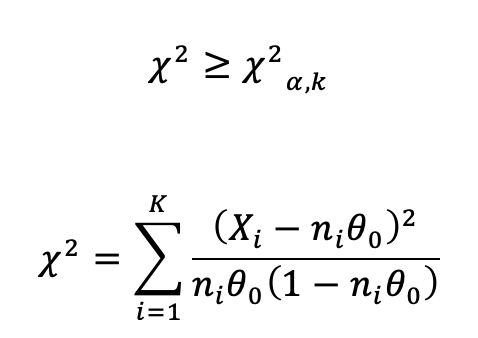
Если среднее значение θ0 не указано, мы должны вычислить объединенную оценку θ_hat и обновить критическую область:

Примечание: если мы используем объединенную оценку, мы теряем степень свободы. Поскольку это напрямую влияет на статистику теста и критическую область, очень важно отслеживать, когда он используется.
С учетом сказанного, мы можем записывать наши испытания в таблицу непредвиденных обстоятельств:

Мы ссылаемся на записи внутри таблицы с помощью fij, где i соответствует строке (образцу), а j соответствует столбцу. Следовательно, если j=1, то мы говорим об успехе, а если j=2, мы имеем в виду неудачу.
При рассмотрении нулевой гипотезы θ1= θ2 ...= θK = θ0 ожидаемые значения рассчитываются как:

При использовании объединенной оценки θ_hat ожидаемые значения становятся:

Используя приведенные выше уравнения и записи в таблице, мы вычисляем нашу тестовую статистику как:

Udemy Registration: значение тестирования
Мы возвращаемся к исходному вопросу в гипотетическом примере Удеми: наблюдаемые различия в пропорциях вызваны случайностью или они значительно отличаются? Мы будем использовать α=0.05 для уровня значимости.
Ради этого случая мы создали набор данных игрушек, предназначенный для репликации такого экземпляра. Пусть запись 1 означает регистрацию (успех), а 0 - отсутствие регистрации (неудача). Предположим, что мы оцениваем 3 субъекта, и фрейм данных выглядит следующим образом:

Нам не хватает значений, потому что 3 образца имеют разный размер. Этого следовало ожидать в реальных приложениях.
Простыми манипуляциями с пандами мы можем создать для этого случая таблицу непредвиденных обстоятельств:

Мы можем реализовать формулы в функции test_k_prop, используя пакет scipy для получения значения хи в квадрате. В противном случае всегда можно поискать таблицу.
Ниже приведен dataframedf_stats, показанный для пояснения. Здесь мы можем увидеть, как мы рассчитали ожидаемые частоты, используя объединенную оценку θ и значение хи-квадрат для каждой выборки и каждого соответствующего результата.

В этом случае вычисленное значение хи-квадрат составляет 6.423, что превышает 5.991, что приводит к отклонению нулевой гипотезы.
Тестирование категориальных переменных

Пример использования: регистрация с премиум-членством
Что, если бы у нас была дополнительная опция в контексте примера, рассмотренного ранее? Представьте, если бы мы представили премиальный пакет для подписавших, который предлагает сеансы 1: 1 с наставником, а также множество других преимуществ. Наша цель больше не является двоичной, так как же нам проверить связь между категориальными переменными?
Тестирование r x c таблиц непредвиденных обстоятельств
В приведенном выше случае у нас есть отдельные образцы из r популяций (математика, экономика, кодирование) и c различных результатов (без регистрации, подписки, премиум).
Поэтому мы проверяем связь между категориальными переменными и понимаем, что каждая популяция происходит от полиномиального распределения.
Нулевая гипотеза утверждает, что для всех индексов 1 ≤ j ≤ c мы имеем:

Альтернативная гипотеза утверждает, что существуют такие i, j, k, что:

Мы рассчитываем статистику теста так же, как и раньше:
Как и в предыдущем случае, f_ij исходит из собранных данных, так что f_ij - это количество наблюдений в совокупности i для результата j. Ожидаемые значения рассчитываются следующим образом:

Таким образом, n_i - это размер выборки, взятой из популяции i, n - общее количество наблюдений, а f_j - общее количество раз, когда мы наблюдаем результат j:

Эта статистика теста дает нам t-распределение с (r-1)(c-1) степенями свободы.
Несколько вариантов регистрации: значимость тестирования
Вернемся к гипотетическому случаю и представим следующий обновленный фрейм данных df_r_c:

В контексте этой проблемы наша нулевая гипотеза утверждает, что предмет (экономика, математика, кодирование) и количество подписок независимы. И наоборот, альтернативная гипотеза утверждает, что это не так.
Мы будем использовать α=0.01 для уровня значимости. Следовательно, чтобы отклонить нулевую гипотезу, нам требуется значение хи-квадрат больше 13,277.
Сначала давайте определим функцию, которая будет возвращать матрицу ожиданий:
Затем мы возвращаем хи-квадрат и сравниваем его с критическим значением:
В этом случае отклоните нулевую гипотезу с помощью 25.9 ›13.3.
Парные данные и неполные таблицы непредвиденных обстоятельств

Хотя это выходит за рамки данной статьи, стоит сделать обзор случая, когда у нас есть парные данные и, следовательно, структурные нули.
Рассмотрим случай с Mario Kart, где King Boo не является игровым персонажем, если пользователь не платит пакет за 1,99 доллара. Только после первоначальной покупки пользователь может опробовать дополнительные моды скинов (как этот).
Как мы проверяем популярность пакета? Кроме того, как мы можем проверить популярность мода скина по сравнению с другими? Можем ли мы сравнить модификации скинов, если некоторые из них были приобретены ранее?
Подобные случаи могут возникать, и специалисты по данным должны иметь представление о продуктах, чтобы определять такие случаи.
Заключение

Формулы и реализации можно пропустить в пользу таких пакетов, как scipy. Однако стоит реализовать их с нуля, чтобы получить интуитивное понимание.
В заключение мы увидели, как можно проверить пропорции и обобщить подход к таблицам непредвиденных обстоятельств. Используя эти методы, специалисты по обработке данных могут преобразовывать данные в практические бизнес-идеи.