«Ты не можешь скрыть свои лживые глаза
А твоя улыбка - тонкая маскировка
Я думал, вы уже поняли
Невозможно скрыть свои лживые глаза »
- Тексты песен Lyin ’Eyes by the Eagles

Если кто-то смотрит вверх и влево, когда что-то говорит, он лжет вам. Если они дергают за рукава, значит, они не правдивы. Заикание? Не верьте ни единому слову из их уст!
Сколько из этих поговорок об обнаружении обмана вы слышали раньше? Людям нравится идея детектора лжи, от народной психологии до тестов на полиграфе и сыворотки правды. Истина, как отмечает известный психолог и признанный авторитет в области лжи Пол Экман, заключается в том, что не существует носа Пинночио, которому кто-то определенно лжет, который применим ко всем людям. У людей могут быть индивидуальные подсказки, которым можно научиться, и определенные физические изменения, если рассматривать их в целом, могут быть хорошим ориентиром, но идеальной системы обнаружения лжи еще не существует.
При этом некоторые люди действительно хорошо умеют распознавать ложь. Вы, наверное, встречали некоторых - игрока за покерным столом, который, кажется, всегда знает, когда кто-то блефует, или вашего второклассного учителя, который каким-то образом всегда мог сказать, что ваша собака на самом деле не съела вашу домашнюю работу. Машины тоже подошли близко: тест на полиграфе, хотя и не всегда точный, считается достаточно надежным для использования в полицейском расследовании, а во многих штатах - для цитирования в зале суда. Эти люди и машины делают это, наблюдая за колебаниями в расширении зрачков, покраснением и множеством других жестов, говорящих одиноким лжецам из толпы. Существует общий набор эвристик, которые детекторы лжи - как люди, так и машины - используют, чтобы определить, лжет ли человек. В случае с людьми не существует ментальной формулы, с помощью которой хорошие детекторы лжи фильтруют информацию, чтобы определить, лжет ли кто-то, это более или менее сводится к внимательной интуиции. Хотя при тестировании на полиграфе используются более конкретные, поддающиеся количественной оценке данные, такие как частота сердечных сокращений и артериальное давление, любые физиологические изменения, которые он измеряет, также могут происходить по причинам, отличным от лжи.
Вместо того, чтобы использовать исключительно интуицию или исключительно физиологические изменения, теперь мы можем воспользоваться всеми данными, которые нам легко доступны. С развитием искусственного интеллекта возможно, что мы будем жить в мире, где знаем, как определять истину с абсолютной уверенностью.
Давайте немного углубимся в самую распространенную в настоящее время систему обнаружения лжи: проверку на полиграфе. Инструмент, используемый в тестах на полиграфе, представляет собой физиологическую запись, которая оценивает различные физические параметры, также известные как «подсказки». Пневмографы обернуты вокруг груди, чтобы измерить частоту дыхания. Сердечно-сосудистая деятельность оценивается с помощью манжеты для измерения кровяного давления. Проводимость кожи оценивается с помощью электродов, прикрепленных к кончикам пальцев человека. Помимо повседневной интуиции, наиболее распространенным методом обнаружения лжи является полиграф. Однако, учитывая, что его основное применение - в расследованиях или судебных заседаниях с высокими ставками, предел погрешности слишком мал, чтобы успокаиваться. Более того, они агрессивны и требуют, чтобы опытный интервьюер проводил допрос и интерпретировал результаты. Достоверность полиграфа снова и снова подвергалась сомнению, критики ссылались на тот факт, что измеренные физиологические параметры имеют доказанную причинную связь только с нервным возбуждением, а не обязательно с ложью.
Другая система обнаружения лжи, инструмент психологической оценки правдоподобности (PBCAT), принадлежит к одной из школ исследований обмана, основанной на так называемом подходе когнитивной нагрузки (CLA). Когнитивная нагрузка - это термин, используемый для обозначения суммы умственного напряжения или усилий, необходимых для выполнения определенной задачи. CLA предполагает, что ложь требует более высокой когнитивной нагрузки, что приводит к определенным образцам поведения. В исследованиях, использованных для разработки PBCAT, исследователи обнаружили, что участникам было легче выявлять обман в других, когда лживым участникам приходилось пересказывать события в обратном порядке, поскольку это создает более тяжелую когнитивную нагрузку. PBCAT - это система с 9 различными шкалами оценок, предназначенная для использования людьми для оценки правдивости рассказов другого человека. Эти шкалы в значительной степени основаны на семантическом содержании рассказа, включая количество противоречий в их рассказе, количество сенсорных деталей и то, насколько расплывчатым или точным был этот человек.
Все эти системы обнаружения лжи сосредоточены исключительно на одном показателе, позволяющем сделать вывод о том, лжет ли кто-то. Люди полагаются на интуицию, полиграфы - на физиологические изменения, а PBCAT - на семантическое содержание. Чтобы создать действительно всеобъемлющий детектор лжи, нам нужно рассмотреть широкий спектр параметров, когда речь идет о том, лжет кто-то или нет. Параметры, измеряемые полиграфом, - хорошее место для начала, но мы также должны попытаться определить факторы, которые информируют человеческую интуицию об обмане, и посмотреть, как мы можем количественно оценить эти факторы. Основополагающий принцип PBCAT, заключающийся в том, что ложь требует большей когнитивной нагрузки, чем говорить правду, проявится не только в рассказе субъекта, но, предположительно, также в его мозговой активности, которую можно измерить с помощью данных ЭЭГ. .
Кроме того, другим недостатком рассмотренных выше систем обнаружения лжи является то, что все они требуют человеческого суждения для проведения оценки. Каждый требует, чтобы человек-переводчик разбирался в результатах, а в случае PBCAT, в первую очередь, человек делает все оценки. Что, если бы мы могли взять то, что работает из всех этих систем, и создать систему на основе искусственного интеллекта, достаточно умен, чтобы делать такие оценки без человеческой предвзятости?
Одна недавно разработанная система обнаружения лжи приблизила нас на шаг ближе к этой цели, используя ИИ для оценки обмана на основе параметра, который существующие системы в значительной степени игнорируют: выражения лица. Выражение лица имеет решающее значение для нашего интуитивного ощущения, когда кто-то лжет, но его трудно определить количественно, так как оно долгое время оставалось вне структурированных систем обнаружения лжи - до сих пор.
Исследователи из Университета Мэриленда разработали Механизм анализа и рассуждения обмана (DARE), систему, которая использует искусственный интеллект для автономного обнаружения обмана в видеороликах судебных заседаний. DARE учили искать человеческие выражения, такие как «выпяченные губы» или «брови нахмурились», а также анализировать звуковые частоты для выявления голосовых паттернов, указывающих на то, лжет человек или нет. Затем он был протестирован с использованием обучающего набора видеороликов, в которых актерам предлагалось либо солгать, либо сказать правду.
Исследователи из Корнельского университета также создали систему, построенную на основе DARE. Система, созданная в Корнелле, в первую очередь ориентирована на обнаружение обмана в реальных видеороликах судебных заседаний. Исследователи также показали, что предсказания коротких, быстрых движений лица могут использоваться в качестве функций для предсказания обмана. Система была обучена с использованием видеозаписей человеческих выражений, которые привели к тому, что система определяла различные классификаторы на основе различных визуальных фильтров. Классификатор - это функция, которая дает прогнозируемое значение вывода, которое используется для присвоения категорийных меток определенным точкам данных в наборе данных. Каждый классификатор получил определенный балл, соответствующий весу. Больший вес означал, что система будет уделять больше внимания этому классификатору при обнаружении лжи. Например, исследователи заметили, что «Поднятие бровей» (эффективность ~ 70%) было более эффективным, чем другие микровыражения.
При тестировании на субъектах, которые не были частью обучающей выборки, система имела AUC 0,877. Это означало, что вероятность того, что система успешно обнаружит обман в видео, составляет 87,7%. При тестировании на человеке система работала лучше. Производительность человека колебалась в районе 0,60 AUC, а у обученной системы - от 0,80 до 0,90. Тем не менее, следует отметить некоторые ключевые моменты: в то время как обученная система значительно превосходит людей, когда дело доходит до визуальных тестов и расшифровок, люди немного обошли систему, когда дело дошло до аудиотеста. Разница была невелика: обученная система находилась на уровне выше 70, а люди - ниже 80. Ключевым фактором, который был принят во внимание, были вариации в обучающей выборке. Чтобы избежать каких-либо предубеждений в системе, обучающая выборка была сделана максимально разнообразной. Это означало, что система обучалась на видео с различными сценариями, случаями, историями и т. Д. Хотя это определенно было сложно, это был важный шаг, поскольку он гарантировал, что система даст объективный результат.
(Чжэ Ву и др., «Обнаружение обмана в видео», 2017 г.)
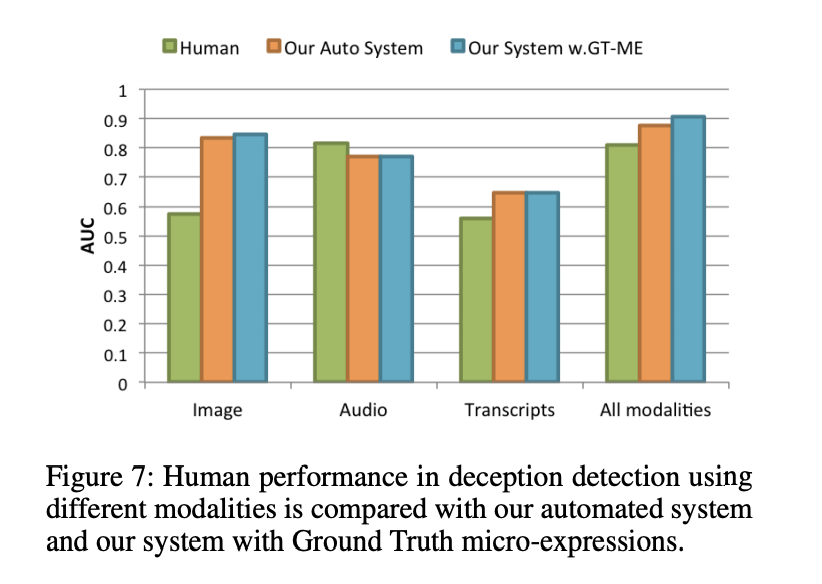
Взято из «Обнаружения обмана в видео», Чже Ву, Бхарат Сингх, Ларри С. Дэвис, В. С. Субрахманян, 12 декабря 2017 г.
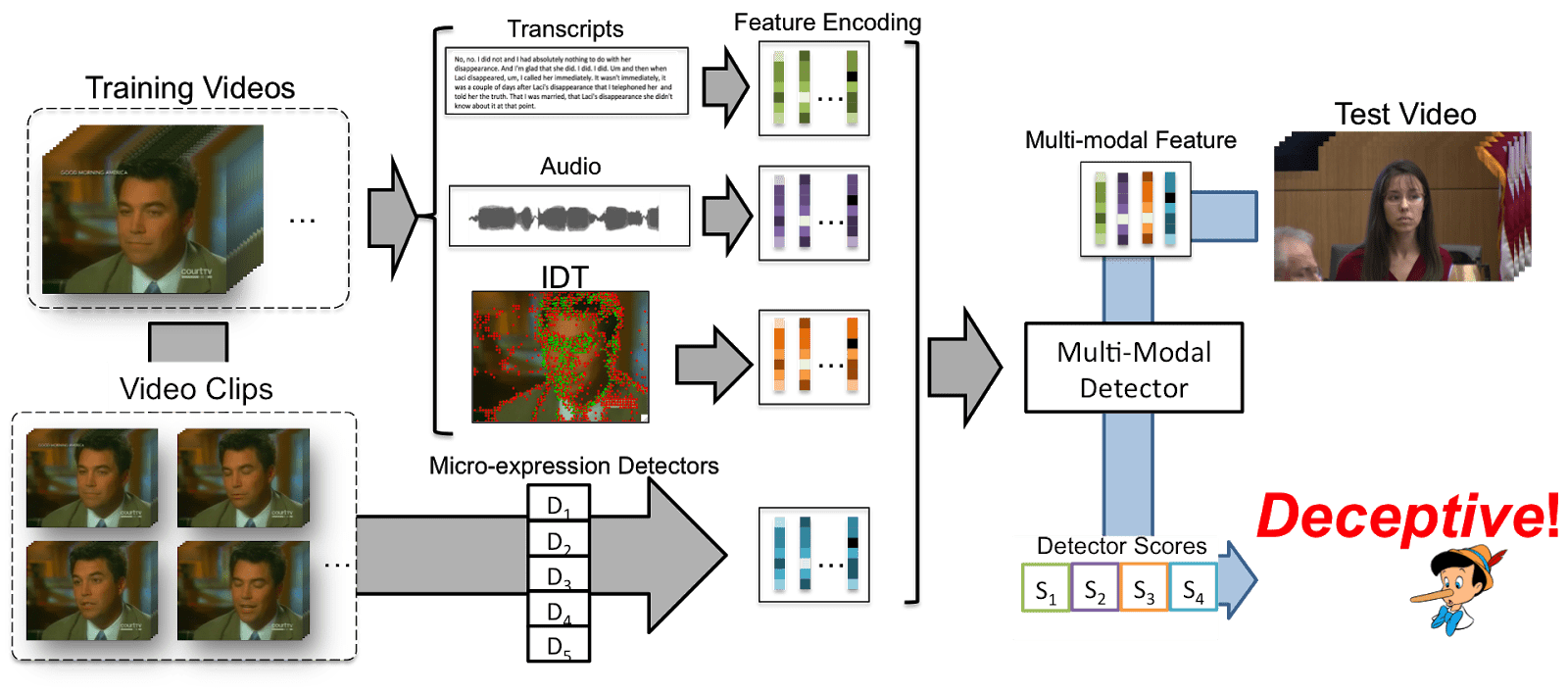
Https://doubaibai.github.io/DARE/
Проведя эти эксперименты, мы можем сделать вывод, что модель обнаружения лжи действительно лучше, чем средний человек, справлялась с задачей выявления лжи. Однако Раджа Чатилья, председатель исполнительного комитета Глобальной инициативы по этическим соображениям в области искусственного интеллекта и автономных систем Института инженеров по электротехнике и радиоэлектронике (IEEE), отмечает, что DARE следует использовать осторожно, особенно в зале суда. При этом Чатилья отмечает, что системы распознавания лиц улучшаются. Он утверждает, что мы можем быть всего через три-четыре года от ИИ, который безупречно и идеально обнаруживает обман, считывая эмоции, скрытые за человеческими выражениями.
Однако важно помнить, что высокая вероятность не означает уверенности. Хотя эти системы можно в значительной степени обучить обнаружению лжи, их можно использовать только в условиях высоких ставок, когда мы на 100% уверены, что система точна. Даже крошечный шанс ошибки может обернуться катастрофой. Хотя исследователи продолжают работать над точностью систем, их способность работать лучше людей в некоторых ситуациях означает, что мы можем использовать их, чтобы сузить круг подозреваемых и указать нам правильное направление.
Также важно отметить, что то, что интерпретация результатов выполняется алгоритмически, а не вручную, не означает, что предвзятость не может существовать. В конце концов, эти алгоритмы пишут люди, а люди определяют стандарты, по которым мы анализируем поведение. Это не означает, что ИИ не является многообещающим методом расследования для достижения цели объективного детектора лжи - это просто означает, что мы должны быть осторожны, чтобы не предполагать, что машина беспристрастна только потому, что это машина.
Тем не менее, с помощью ИИ у нас теперь есть система, которая может количественно определять выражения лица для обнаружения обмана. Хотя алгоритм обнаружения лжи может быть несовершенным, он интересен, потому что демонстрирует потенциал ИИ в количественной оценке других факторов, связанных с ложью, которые мы игнорировали в прошлом. Мы надеемся, что мы сможем провести оценку семантических показателей, подобных тем, которые используются в PBCAT, но без предвзятости человека. ИИ также может быть ключом к использованию успешных аспектов интуитивного распознавания лжи структурированным и объективным образом. Применение машинного обучения открывает возможность персонализировать процесс обнаружения лжи. Мы все еще далеки от создания полностью надежной и всеобъемлющей системы обнаружения лжи, включающей физиологические, семантические, когнитивные и интуитивные параметры, но похоже, что ИИ проложит путь к этому.
Эта статья была написана Шреяшем Айенгаром и Мелоди Сифри и отредактирована Джвалином Джоши.
Шреяш изучает EECS в Калифорнийском университете в Беркли.
Мелоди изучает когнитивные науки в Калифорнийском университете в Беркли.
Джвалин изучает прикладную математику и информатику в Калифорнийском университете в Беркли.